HTTBU
Le blog des BU sur les publications électroniques et les données de la recherche
.jpg)
Image : Rosino, CC BY-SA 2.0
Comme à chaque début d’année, un petit point sur les modifications d’abonnements.
Les bonnes nouvelles d’abord :
Deux nouveaux bouquets Jstor sont ouverts à la consultation :
– Jstor Arts & Sciences V, axé principalement sur l’histoire, les arts, la philosophie et la littérature (plus de détails sur la collection)
– Jstor 19th century british pamphlets, qui contient plus de 26000 pamphlets britanniques (plus de détails sur la collection)
Le périmètre de notre abonnement à Diane s’étend dans le cadre de la négociation Couperin : accès à l’ensemble de la base (et non pas aux entreprises les plus importantes comme précédemment).
L’accès distant sera disponible dans les prochains jours, et il n’y a plus de restriction en nombre d’utilisateurs simultanés. Bien évidemment, cette base, comme toutes les ressources, est soumise à une licence et son usage doit se faire dans un cadre strict d’enseignement et de recherche. Les éditeurs de droit et d’économie sont particulièrement attentifs.
Nous avons changé de fournisseur pour PsycInfo, PsycArticles. Ils sont désormais accessibles par Proquest, avec une interface plus simple et intuitive.
N’hésitez pas à Interroger un bibliothécaire si vous éprouvez des difficultés ou avez des questions sur cette nouvelle interface.
Une nouvelle base complète l’offre en psychologie : Proquest psychology journals (texte intégral de revues et de thèses)
Les moins bonnes ensuite :
L’augmentation moyenne constatée pour la documentation électronique se situe autour de 4%, et est accentuée par la hausse du dollar.
Les bibliothèques ont donc dû supprimer certains produits moins consultés pour maintenir le reste de l’offre. Il s’agit de :
– Comprehensive Physiology (pour les mises à jour, l’antériorité restant accessible)
– Francis (la base n’est plus maintenue par le CNRS, et doit devenir gratuite d’ici la fin de l’année)
– Socindex (accessible sur BiblioSHS pour les unités CNRS)
– ASFA : Aquatic Sciences Fisheries Abstracts
Conf+ CFI sera accessible jusqu’à la fin de l’année universitaire 2014-2015 (fin juin).
et les périodiques électroniques :
Biochemical journal
Journal of biochemistry
Journal of biological chemistry
Journal of neurophysiology
Journal of Trauma and Acute Care Surgery
Spine
Bien sûr, toutes nos autres ressources sont toujours accessibles par le portail des BU.
Les bibliothèques sont à votre disposition pour vous procurer les documents qui ne font pas partie de nos collections par le service du Prêt entre bibliothèques.
Bonne année et belles découvertes documentaires
Isidore est un portail d’accès unifié aux publications électroniques (principalement francophones) en sciences humaines et sociales, développé depuis 2011 dans le cadre de la Très Grande Infrastructure dédiée aux humanités numériques, le TGIR Human-num.
Isidore moissonne et agrège les données de multiples sources et bases de données telles que Revues.org, Persée, Gallica, Calames, Cairn, Dumas, Erudit…, soit en tout plus de 3 millions de documents.
Mais plus intéressant encore, Isidore s’appuie sur les technologies de ce que l’on appelle le LOD (Linked Open Data), pour enrichir les données engrangées d’information, grâce à des sources complémentaires.
Parmi celles-ci, citons :
Lorsque chaque notice est récupérée par Isidore, elle est enrichie grâce à ces différentes sources. Donc, lorsqu’on fait une recherche via Isidore, les notices récupérées présentent plus d’informations que dans leur base de données source : une indexation plus riche, des données de géolocalisation, d’autres notices liées…
C’est déjà beaucoup, mais il y a encore mieux : Isidore expose ses données, il permet aux utilisateurs de les récupérer pour les ré-exploiter ensuite dans d’autres environnements.
Un des points d’accès proposé pour cela est l’API web d’Isidore : derrière ce sigle un peu mystérieux que l’on traduit en français par « interface de programmation« , on parle en fait d’un service par lequel un logiciel, un fournisseur expose tout ou partie de ses données et/ou de ses fonctionnalités.
Revenons donc à Isidore : l’API est documentée sur ce site, on peut y effectuer une recherche classique par un formulaire de recherche. La recherche fournit une liste de résultats web (format HTML normal), mais en cliquant sur « Informations techniques », on obtient un lien vers les mêmes résultats, mais en XML.
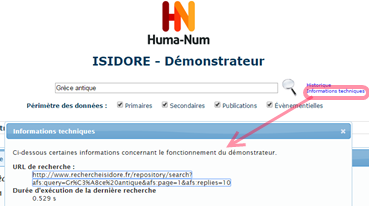
Ce format est :
Bon, c’est là que ça se complique un peu car ces notices en XML, on n’en fait rien en tant que telles : il faut savoir les manipuler avec des langages comme XSLT ou PHP pour les exploiter, les convertir sous d’autres formats, bref les redistribuer.
Mais assez de blablas, un bon exemple valant mieux que de longs discours, Imaginons que je commence une thèse sur le concept de culotte comme indicateur sociétal en France.
Je souhaite donc commencer par faire une cartographie de l’ensemble des publications francophones sur la culotte sous ses dimensions historiques, sociales, linguistiques etc… Pour cela j’ai donc besoin de constituer un corpus de références de publications (une bibliographie du sujet) que je pourrai ensuite analyser en le soumettant à d’autres logiciels d’exploration et de visualisation.
J’interroge donc l’API d’Isidore en utilisant le mot-clé « Culotte » soit « http://www.rechercheisidore.fr/repository/search?afs:query=Culotte&afs:page=1&afs:replies=100 » (les derniers paramètres indiquant que j’affiche d’abord la page 1 de la liste de résultats et que je souhaite afficher 100 résultats par page). En interrogeant l’API de manière récursive sur toutes les pages de résultats, j’obtiens en réponse 836 notices, que je peux donc manipuler (si je parle le XSLT, ou si je demande à ma BU qui le connaît), transformer en XML, CSV, JSON, ou tout autre format et ensuite analyser comme je le souhaite.
Ainsi, en passant par l’API Isidore (plutôt que la recherche standard), je peux pour chaque notice obtenir le lieu de publication de la ressource décrite, et sa discipline. Je peux ainsi confronter répartition géographique et disciplinaire des publications moissonnées :
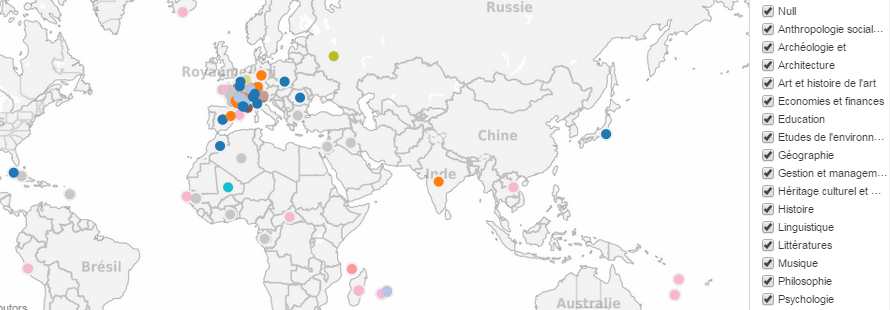
Publications scientifiques sur la « culotte » : répartition géographique et disciplinaire – visualisation obtenue avec le logiciel Tableau Public
Ou encore visualiser sous forme de graphe les relations de proximité entre concepts :
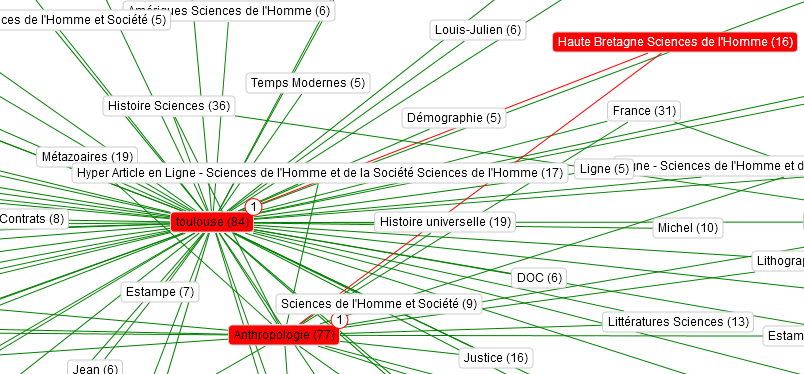
Concepts associés à chaque notice et liens entre eux – visualisation obtenue avec le logiciel Voyant Tool
Ou encore extraire les résumés dans l’ordre chronologique et en étudier les fréquences d’apparition de certains mots :
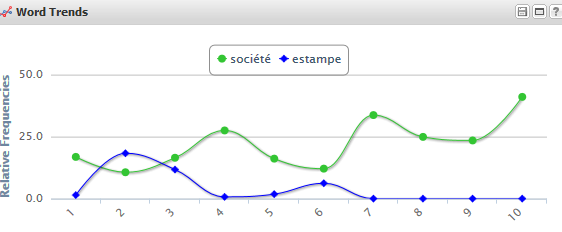 Fréquence de certains mots-clés dans les 836 ressources traitant de la culotte – visualisation obtenue avec Voyant Tool
Fréquence de certains mots-clés dans les 836 ressources traitant de la culotte – visualisation obtenue avec Voyant Tool
Ou encore etc…
A partir du même exemple, vous pouvez visualiser sur cette page web d’autres types d’exploitation de données récupérées grâce à l’API d’Isidore, véritable sésame pour l’exploration de corpus bibliographiques en SHS.
Logiciels libres utilisés : Tableau Public, Voyant Tools, Simile Exhibit.
NB : les données aspirées par l’API l’ont été uniquement pour l’exemple, elles n’ont pas été nettoyées de toutes leurs « scories » éventuelles, ce qui explique un affichage pas toujours très « propre ».
Dans un prochain billet : le Sparql Endpoint d’Isidore, un autre point d’accès pour explorer sémantiquement les données d’Isidore structurées en RDF.
Une préquelle de ce qui vous attend dès la rentrée : un focus sur le portail en SHS Isidore, l’utilisation de son API avec des recherches culottées, des techniques d’extraction de données et quelques idées de visualisation…

A côté de son interface standard, Jstor offre aux chercheurs l’interface Data for Research. Encore en version beta, cette interface propose des fonctionnalités d’exploitation avancées de la base Jstor.
Intérêts de cette interface :
Quelques exemples d’exploitation : travailler sur l’évolution d’une discipline, sur l’usage d’un concept dans une discipline, récupérer l’ensemble des articles parus dans une revue, en afficher la distribution chronologique et thématique…
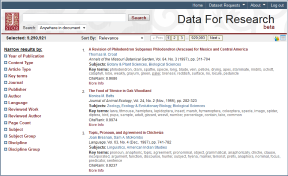
Fonctionnement de la recherche
La sélection se fait par restrictions successives. Par défaut l’ensemble des documents Jstor est sélectionné, et l’on peut ensuite rechercher des termes et/ou restreindre par les facettes proposées en colonne de gauche.
– Recherche : l’interface propose un champ de recherche unique, avec éventuellement une limitation sur les champs à interroger (titre, auteur, résumé, légende, mot-clé, citations).
Il est possible d’affiner sa recherche en construisant des équations, à l’aide d’opérateurs booléens et des codes de champs, visibles dans les URL, par exemple :
Recherche d’articles ayant le mot « Afrique » dans titre ou résumé : ((ta:afrique) OR (ab:afrique))
Récupération des articles de la revue Etudes rurales en se limitant au type « article » : (jcode:etudesrurales) AND (ty:fla)
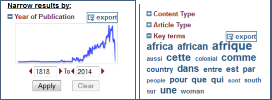
– Facettes :
La facette Date affiche un graphique de distribution chronologique. La facette Key terms présente un nuage de mots. Les listes ou graphiques pour chaque facette sont exportables
Comment récupérer le corpus de données ?
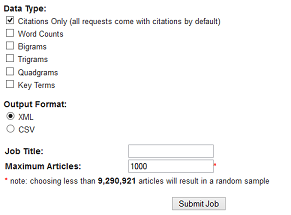
Il faut créer un compte et s’identifier (Log in/register).
Le corpus doit être inférieur à 1000 documents, sinon une sélection aléatoire sera faite lors de l’export. Il est possible de contacter Jstor pour lever cette limite. Il faut alors expliciter en détail son projet, comme le demandent aussi d’autres éditeurs pour la fouille de données. Toutefois, cette exigence peut sembler problématique (voir la question des données du data mining dans ce billet de Sciences Communes…).
Une fois sa sélection faite, cliquer sur Datasets request, puis Submit new request.
Une fenêtre s’ouvre et vous indique le statut du traitement. Lorsque le résultat est prêt, un mail est envoyé à l’adresse de messagerie paramétrée. Aller sur « List prior requests » pour récupérer les résultats au format zip (full dataset) et un rappel des critères de recherche (summary file)
![]()
En cas de problème, l’assistance mail Jstor s’avère très réactive et efficace.
L’exploitation des résultats
L’ensemble des références bibliographiques est récupéré dans un fichier unique.
On peut par exemple importer ces données dans Excel (fonctionne bien pour l’export csv en choisissant le codage UTF8)
Pour les analyses linguistiques, on obtient un fichier par référence ; le liens avec les références se fait par l’identifiant du document.
On peut ensuite utiliser un outil d’analyse de texte (exemples trouvés – non testés – : JstorR, Paper Machines, Mallet…)
Pour les usages autorisés et la ré-exposition des données, voir les Terms and conditions (en particulier, l’incorporation dans des bases de données accessibles doit se faire avec l’accord de l’éditeur)
Quelques limites de DfR
Malgré tout cet outil simple à prendre en main me semble ouvrir de nombreuses possibilités.
Vous vouliez en savoir plus sur la journée nationale des URFIST du 25 septembre ? Voici la suite !
La présentation par Rodrigo Costas -Comesaña de ses travaux sur Altmetrics a permis de faire un point sur la définition des altmetrics, les outils concernés (plateformes sociales comme Mendeley, ResearchGate, outils grand public comme Twitter, Facebook), les données disponibles, les biais, et ce que l’on peut en attendre.
Le travail sur ces données présente de nombreux problèmes (corrélation entre les sources ou manque de cohérence au sein du même outil, difficulté de manipulation, manque de normalisation…). On note dans les résultats une sous-représentation de certaines disciplines plus complexes, ou si les titres d’article sont trop longs (twitter et facebook). L’intérêt semble donc plus de mesurer la réception et la vision sociale de la science par le profane que d’en tirer une évaluation des travaux.

Source : Wikimedia, Photo by CEphoto, Uwe Aranas / CC-BY-SA-3.0
Le sociologue des sciences Yves Gingras a remis en perspective historique ces évolutions. La situation actuelle résulte à la fois de l’arrivée d’Internet, qui a changé l’unité (de la revue à l’article), de la financiarisation de l’économie de l’édition, et de l’avènement d’un nouveau management public au sein des universités (centré sur l’évaluation). L’utilisation des indicateurs pour l’évaluation dépend de la fonction de l’institution. Il faut s’interroger sur les outils disponibles et leurs limites pour l’objectif visé (l’indice H est mal conçu ; Scopus et Wos, quoique incomplets, restent mieux contrôlés, que d’autres).
Les données de la recherche sont un autre sujet d’actualité. Le directeur exécutif de Codata (Committee on Data for Science and Technology- ICSU) a présenté les initiatives en cours pour promouvoir l’ouverture des données de la recherche : groupes de travail, déclaration Open access, avec des recommandations pour la citation normalisée des ensembles de données, projet d’attribution de DOI aux données (Datacite), entrepôt international de dépôt (Dryad).
Au total, une journée riche et instructive.
Retrouvez dans les abonnements électroniques de l’UNS les publications de Rodrigo Costas (Springer, Wiley) et celles d’Yves Gingras (Cairn.info, Erudit)
Voir aussi la première partie du compte-rendusur ce blog, et les interventions en vidéo sur le wiki de l’URFIST de Nice
 Le 25 septembre l’UNS a accueilli la journée des URFIST, consacrée aux nouvelles formes de communication et d’évaluation scientifique (voir le programme en ligne). L’occasion de mettre en perspective les pratiques d’édition et d’évaluation actuelles dans l’environnement numérique, et de faire le point sur des termes souvent cités, mais au contenu encore flou (épi-revues, Altmetrics).
Le 25 septembre l’UNS a accueilli la journée des URFIST, consacrée aux nouvelles formes de communication et d’évaluation scientifique (voir le programme en ligne). L’occasion de mettre en perspective les pratiques d’édition et d’évaluation actuelles dans l’environnement numérique, et de faire le point sur des termes souvent cités, mais au contenu encore flou (épi-revues, Altmetrics).
La première intervention était consacrée aux épi-revues. Alain Monteil a présenté la stratégie de l’INRIA. L’institut a fait le choix volontariste de la voie verte de l’Open Access : dépôt obligatoire sur Hal pour les chercheurs, et évaluation basée sur les listes de publication Hal. Une offre Open Access est élaborée, en partenariat avec le CCSD, autour du dépôt dans Hal-INRIA, de Sciencesconf.org pour les conférences, et de la plateforme Episciences (revues). Le Journal of Data Mining & Digital Humanities (trimestriel) est déjà en ligne. D’autres projets concernent IAM- Informatics & applied mathematics,DMTCS- Discrete Maths & Theoretical Computer Science.
Ces épi-revues veulent offrir un nouveau modèle de publication, notamment dans des sciences mal représentées dans l’édition traditionnelle. Elles fournissent un label de qualité en continuité avec les éditeurs classiques (comité éditorial, évaluation par les pairs, archivage à long terme, visibilité et référencement) mais cherchent également à dépasser leurs limites : fournir un accès libre sans embargo dès la soumission de l’article, favoriser les échanges entre scientifiques en intégrant la dimension des réseaux sociaux ; réunir plusieurs objets (images, codes, vidéos…) ; aller vers la transdisciplinarité.
Le rôle de l’édition a été interrogé par plusieurs intervenants.
Pierre Mounier (Cleo) a évoqué les pratiques des blogs et carnets de recherche en SHS. Parfois présentés comme un moyen pour les chercheurs de retrouver une liberté d’écriture, en opposition aux publications, ces carnets recouvrent de fait des réalités plus variées, en hybridation avec l’édition traditionnelle qui conserve son rôle : blogs de chercheurs, veille, communication plus ou moins institutionnelle autour de projets de recherche, accompagnement éditorial (informations, discussions, commentaires). On peut citer en exemple les carnets des revues VertigO ou Terrain. La publication peut d’ailleurs à son tour naître à partir de billets de blogs (collection de livres Open edition press).
David Monniaux a tracé une vision très différente de l’édition en informatique, où le travail de mise en forme est perçu comme à la charge de l’auteur. Son blog n’aborde pas son travail de recherche, pas assez grand public. Il induit un mode d’écriture et des précautions spécifiques.
Les entreprises aussi s’interrogent sur les modèles éditoriaux. Faculty of 1000 a présenté deux de ses produits : F1000Prime (sélection d’articles par des scientifiques) ; F1000Research (publication en libre-accès sur le modèle auteur-payeur).
De façon comparable aux épi-revues, il y a une volonté de mise à disposition de l’article dès l’origine et de visibilité sur le processus d’évaluation (commentaires, versions etc). Mais le coût économique reste classiquement à la charge des établissements utilisateurs et/ou producteurs (respectivement abonnement et paiement par l’auteur).
Tout comme l’édition, l’évaluation évolue et a fait l’objet de plusieurs contributions stimulantes au cours de cette journée. A suivre dans le prochain billet !
Les bibliothèques universitaires de l’UNS participent à la 7ème édition de la semaine internationale du libre accès « Generation Open ! ».
Cet événement mondial permet à la communauté scientifique d’en savoir plus sur les bénéfices du libre accès, de partager ses connaissances et ses expériences entre collègues, et de contribuer à la promotion du libre accès.
http://www.oaweekfrance.org/lopen-access-week/quest-ce-que-lopen-access-week/
Prenez 15 minutes et venez à la BU de votre choix avec un (ou plusieurs) de vos articles, déjà publié(s) ou non, en format PDF,

le mardi 14 octobre 2014 entre 13h et 16h à la BU Lettres – Henri Bosco (campus Carlone)
le mardi 14 octobre 2014 entre 16h et 19h au Learning Centre SophiaTech (Les templiers, Batiment Forum, niveau – 1) avec la participation de l’INRIA*
le mercredi 15 octobre 2014 de 16h et 19h au Learning Centre SophiaTech (Les templiers, Batiment Forum, niveau – 1) avec la participation de l’INRIA*
le jeudi 16 octobre 2014 de 10h à 13h à la BU Droit (campus Trotabas)
le jeudi 16 octobre 2014 de 14h30 à 17h30 à la BU Saint Jean
le vendredi 17 octobre 2014 de 9h30 à 12h30 à la BU Sciences (Campus Valrose), avec la participation du laboratoire JAD*
Nous vous aiderons à déposer votre premier article dans Hal-Unice, l’archive ouverte de l’UNS et à faire peut-être votre premier pas en Open Access.
Si vous n’avez pas d’article à déposer, venez quand même pour :
Nous vous attendons nombreux pour fêter l’Open Access. Et si vous n’êtes vraiment pas disponible à une de ces dates, n’hésitez à nous contacter pour toute question ou pour prévoir un rendez-vous avec le pôle Publications des BU à ao-scd@unice.fr.
Avec la participation de l’INRIA et du laboratoire JAD et avec le soutien de la MSHS et du GREDEG*
Ce projet bénéficie du label Foster
(* : ajout du 09/10/2014)
Quand on cherche un ouvrage, la première tentation est d’aller voir directement dans les rayons de la BU.
Parfois ça marche. Parfois non.

N’en concluez pas trop vite que la BU n’a pas le document voulu : Il est peut-être
Il est présent sur toutes les pages du site

Il vous permet de trouver tous types de documents
Chaque exemplaire est localisé sur un plan de la BU
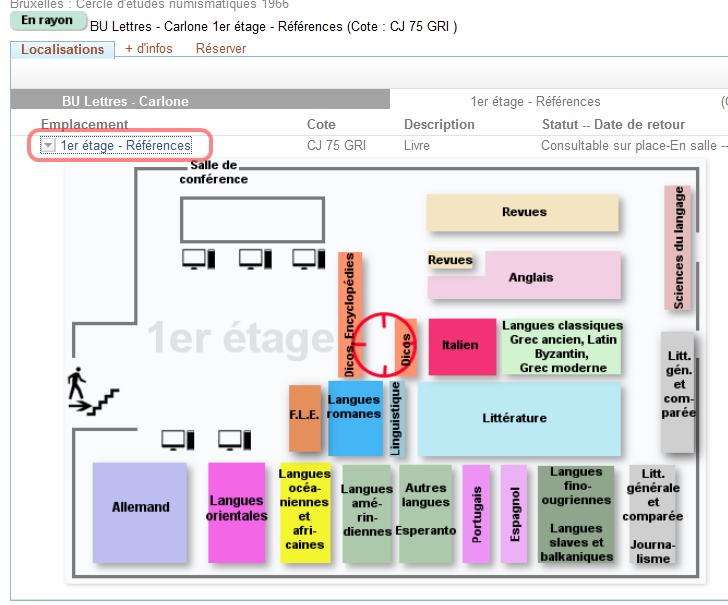
Vous pouvez y chercher par titre, auteur, date, sujet ou thématique, ISBN, cote d’ouvrage, etc.
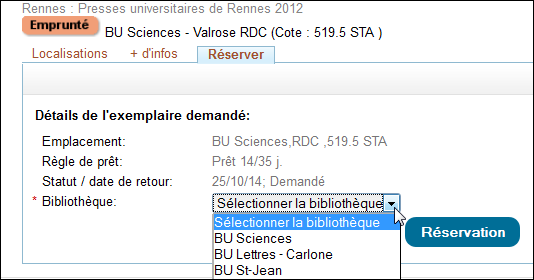
Si l’ouvrage est emprunté, vous pouvez le réserver et le demander à le retirer dans la bibliothèque de votre choix
Si vous ne trouvez pas l’ouvrage que vous souhaitez, vous pouvez encore (en bas de la liste des résultats)
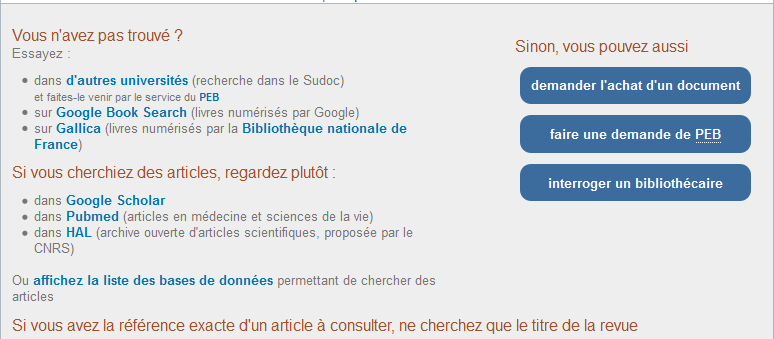
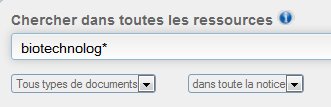
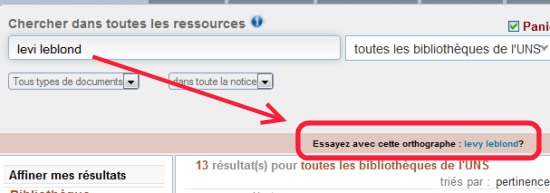
Quand vous voulez des ouvrages ou des revues sur un thème précis, sans avoir de titre en tête, vous allez spontanément indiquer le mot qui vous vient naturellement à l’esprit pour décrire ce thème.
Or la BU indique les sujets des ouvrages à partir d’une liste fermée de mots autorisés.
Imaginons que vous vous intéressiez aux cultures numériques. En cherchant « Culture numérique » dans l’outil de recherche, vous allez trouvez des résultats, mais pas tous les résultats sur le sujet. Et il y aura certainement du bruit.
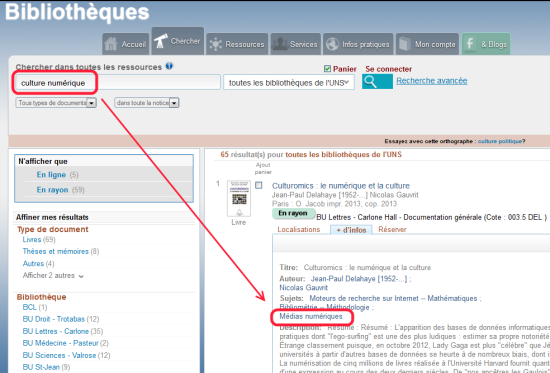
En réalité, tous les ouvrages sur la culture numérique ont été signalés par l’expression « médias numériques ». Et vous ne pouvez le savoir qu’après avoir trouvé au moins un ouvrage sur le sujet qui vous intéresse.
Vous avez donc intérêt à :
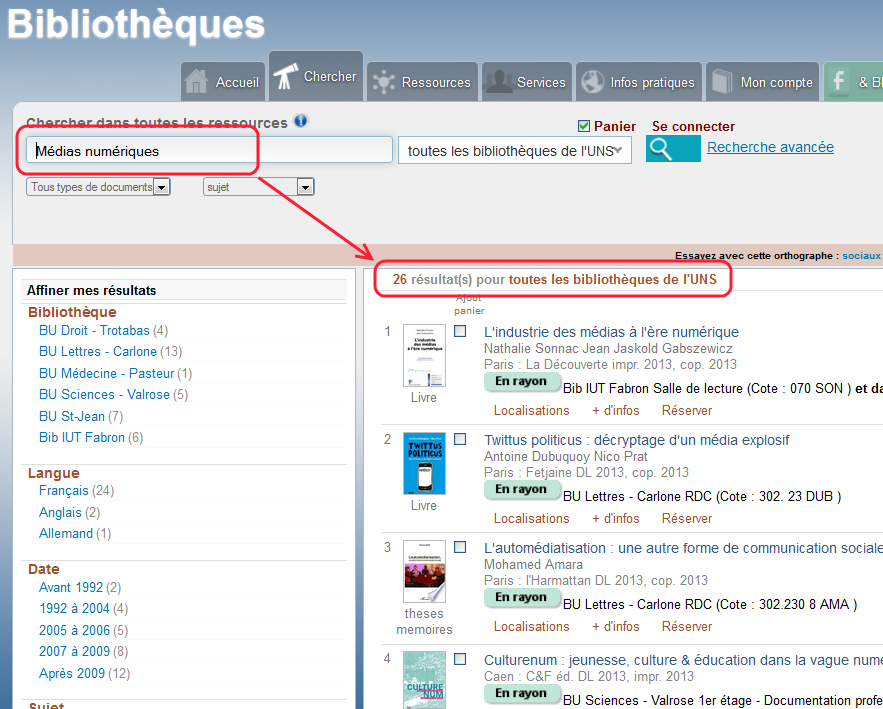
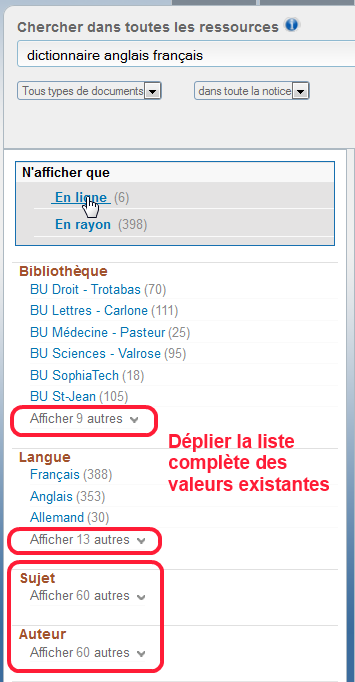
Puisque vous ne pouvez pas circuler dans les rayons de nos collections de ebooks, vous pouvez afficher l’ensemble des ebooks en cherchant « ebook » + limiter sur la facette « En ligne », puis filtrer par sujet (ça revient à se promener dans des rayonnages de bibliothèque)
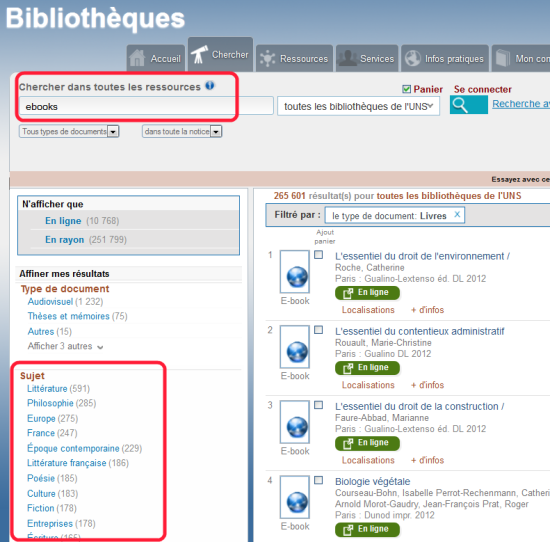
Même chose : cherchez « ejournal« , plus limitez les résultats avec les facettes
Un même livre peut être réédité plusieurs fois. C’est souvent le cas pour les manuels, notamment.
Par défaut, l’outil de recherche n’affiche que l’édition la plus récente. Si vous voulez consulter une édition plus ancienne (par exemple si la plus récente est empruntée), il suffit de cliquer sur l’icône à droite) :

Installez l’outil de recherche des BU dans votre navigateur (pour Firefox ou Chrome).
L’accès au plugin se trouve aussi en pied de page des listes de résultats
Dans le bandeau supérieur de recherche, une info-bulle cliquable vous rappelle les principales choses à savoir sur l’outil de recherche.
Vous trouverez également des info-bulles bleues un peu partout
![]()
N’hésitez pas à vous en servir !
Revel est la plateforme de diffusion de revues électroniques en sciences humaines et sociales de l’université Nice Sophia Antipolis. Et elle fête cette année son dixième anniversaire !
On vous a parlé dans les billets précédents, ici et là, de l’aventure humaine qu’est Revel, et de l’implication des équipes de chercheurs et des documentalistes-bibliothécaires dans ce projet. Le résultat de cette aventure c’est la diffusion en ligne des revues et colloques en sciences humaines et sociales (SHS pour les intimes) de l’université Nice Sophia Antipolis, ce qui en chiffres donne la combinaison gagnante 15, 7, 8, 1, 2, 269, 3252, 40 000 :

15 revues en libre accès (parfois avec délai pour la mise en libre accès) :
Et pour ces 15 revues réunies, c’est aujourd’hui :
sans oublier la partie réservée aux colloques de l’UNS, qui héberge pour l’instant 8 espaces de colloques certains pour une unique manifestation, d’autre pour des collections d’actes de colloques.
N’hésitez pas à contacter l’équipe du pôle Publication des BU pour toute question relevant de la publications de revues scientifiques ou de colloques à l’UNS à revel@unice.fr.
Les revues Revel en SHS de l’UNS
| Rursus sur Revues.org | Poiétique, réception et réécriture des textes antiques |
| Cycnos sur Revel | Etudes anglophones |
| Socio-Anthropologie sur Revues.org puis Mondes contemporains bientôt sur Revues.org |
Sciences sociales |
| Cahiers de l’Urmis sur Revues.org | Sciences sociales |
| Cahiers de Narratologie sur Revues.org | Analyse et théorie narratives |
| Cahiers de la Méditerranée sur Revues.org bientôt sur Persée |
Histoire et sciences sociales |
| Revue française de musicothérapie sur Revel | Musicothérapie |
| Oxymoron sur Revel | Psychanalytise et interdiscipline |
| Noesis sur Revues.org | Philosophie |
| Loxias sur Revel | Littératures française et comparée |
| Corpus sur Revues.org | Linguistique |
| ERIEP sur Revel | Economie industrielle |
| Revue d’économie industrielle sur Revues.org sur Cairn sur Persée |
Economie industrielle |
| Alliage sur Revel | Culture, sciences, techniques |
| Perspectives internationales et européennes (arrêtée) sur Revel | Droit international |
486 237, c’est le nombre d’articles téléchargés dans l’université pour l’année 2013.
Il y en a sûrement au moins un qui vous intéresse.
Nouvel arrivant ? Voici quelques ficelles pour utiliser la documentation électronique !

Image : US Army, Wikimedia. Domaine public
Toutes les ressources en ligne auxquelles l’université est abonnée sont signalées sur le portail des bibliothèques.
Vous y trouverez aussi certaines ressources en accès libre sur le web, indiquées par une puce verte ![]() .
.
Deux outils à votre disposition :
Vous recherchez un article précis ? Il faut chercher au titre de la revue. Une recherche par thème ? Identifiez les bases de données dans votre discipline pour trouver des articles et documents pertinents (La faq dédiée vous en dira plus).
Quelques pistes de départ
 Ressources généralistes de premier niveau :
Ressources généralistes de premier niveau :
Les Que sais-je
Plus complexe mais riche, la base de presse Factiva (voir l’article)
Pour une recherche approfondie, les plates-formes des éditeurs et outils spécialisés dans les différentes disciplines.
La page Ressources en ligne propose une entrée par sujet pour repérer les instruments de votre discipline
Des tutoriels, signalés par l’icône ![]() et des supports de cours peuvent vous aider à prendre en main les interfaces.
et des supports de cours peuvent vous aider à prendre en main les interfaces.
Vous avez trouvé un document intéressant ? 😀
Pour le consulter, il suffit de cliquer sur le lien… ou presque !
Car pour accéder aux ressources en ligne à distance, vous devrez vous identifier avec un Sésame (pour les étudiants) ou un login de messagerie (pour les enseignants et chercheurs)
Si ce n’est pas déjà fait, demandez votre identifiant sur l’ENT de l’université
Un problème ou une question ? Nous sommes là pour vous dépanner. Utilisez le formulaire Interroger un bibliothécaire, ou écrivez à docelec@unice.fr
 SCD BU Université Nice Sophia Antipolis
2015 |
Propulsé par WordPress et Mystique thème par digitalnature
SCD BU Université Nice Sophia Antipolis
2015 |
Propulsé par WordPress et Mystique thème par digitalnature