Le blog des BU sur les publications électroniques et les données de la recherche
Articles taggués humanités numériques
DfR : l’autre interface Jstor
011 années
par Cécile Pierre.
dans Zoom sur...
A côté de son interface standard, Jstor offre aux chercheurs l’interface Data for Research. Encore en version beta, cette interface propose des fonctionnalités d’exploitation avancées de la base Jstor.
Intérêts de cette interface :
- Décharger en une fois un nombre important de données (limité à 1000 maximum) sans avoir à les sélectionner page par page. Il s’agit cependant uniquement des références bibliographiques et résumés (pas de texte intégral)
- Visualiser graphiquement la répartition chronologique d’un corpus (date) et les mots-clés (nuage de mots)
- Bénéficier de fonctionnalités d’analyse linguistique sur les documents (extraction automatique de mots-clés, fréquence de mots isolés, digrammes, trigrammes…)
Quelques exemples d’exploitation : travailler sur l’évolution d’une discipline, sur l’usage d’un concept dans une discipline, récupérer l’ensemble des articles parus dans une revue, en afficher la distribution chronologique et thématique…
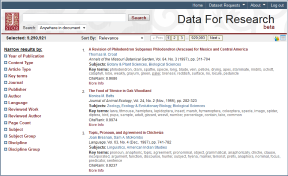
Fonctionnement de la recherche
La sélection se fait par restrictions successives. Par défaut l’ensemble des documents Jstor est sélectionné, et l’on peut ensuite rechercher des termes et/ou restreindre par les facettes proposées en colonne de gauche.
– Recherche : l’interface propose un champ de recherche unique, avec éventuellement une limitation sur les champs à interroger (titre, auteur, résumé, légende, mot-clé, citations).
Il est possible d’affiner sa recherche en construisant des équations, à l’aide d’opérateurs booléens et des codes de champs, visibles dans les URL, par exemple :
Recherche d’articles ayant le mot « Afrique » dans titre ou résumé : ((ta:afrique) OR (ab:afrique))
Récupération des articles de la revue Etudes rurales en se limitant au type « article » : (jcode:etudesrurales) AND (ty:fla)
– Facettes :
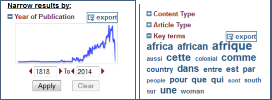
La facette Date affiche un graphique de distribution chronologique. La facette Key terms présente un nuage de mots. Les listes ou graphiques pour chaque facette sont exportables
Comment récupérer le corpus de données ?
Il faut créer un compte et s’identifier (Log in/register).
Le corpus doit être inférieur à 1000 documents, sinon une sélection aléatoire sera faite lors de l’export. Il est possible de contacter Jstor pour lever cette limite. Il faut alors expliciter en détail son projet, comme le demandent aussi d’autres éditeurs pour la fouille de données. Toutefois, cette exigence peut sembler problématique (voir la question des données du data mining dans ce billet de Sciences Communes…).
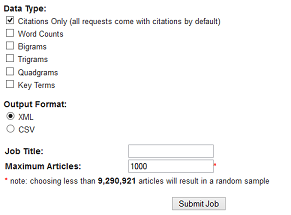
Une fois sa sélection faite, cliquer sur Datasets request, puis Submit new request.
Une fenêtre s’ouvre et vous indique le statut du traitement. Lorsque le résultat est prêt, un mail est envoyé à l’adresse de messagerie paramétrée. Aller sur « List prior requests » pour récupérer les résultats au format zip (full dataset) et un rappel des critères de recherche (summary file)
![]()
En cas de problème, l’assistance mail Jstor s’avère très réactive et efficace.
L’exploitation des résultats
L’ensemble des références bibliographiques est récupéré dans un fichier unique.
On peut par exemple importer ces données dans Excel (fonctionne bien pour l’export csv en choisissant le codage UTF8)
Pour les analyses linguistiques, on obtient un fichier par référence ; le liens avec les références se fait par l’identifiant du document.
On peut ensuite utiliser un outil d’analyse de texte (exemples trouvés – non testés – : JstorR, Paper Machines, Mallet…)
Pour les usages autorisés et la ré-exposition des données, voir les Terms and conditions (en particulier, l’incorporation dans des bases de données accessibles doit se faire avec l’accord de l’éditeur)
Quelques limites de DfR
- Contenu de la base JSTOR. Une grande partie des revues sont accessibles uniquement jusqu’à une certaine date ou après une période d’embargo de plusieurs années. Jstor est donc plus adapté à des recherches portant sur une vaste période chronologique ou l’antériorité, et pas sur les années récentes
- Complétude des données : les résumés par exemple ne sont pas nécessairement présents, surtout avant les années 70. La restriction d’une recherche sur ce critère présente donc un biais.
- La sélection « en entonnoir » est parfois frustrante ; si l’on n’utilise pas d’équation de recherche avancée, impossible par exemple de sélectionner plus d’une revue ou d’une discipline à la fois dans les facettes
- La restriction à 1000 documents s‘avère à l’usage assez contraignante
- Les mots clés ne sont pas toujours très pertinents dans les langues autres que l’anglais
- La recherche porte sur le texte intégral du document, ce qui génère parfois du bruit dans les recherches.
Malgré tout cet outil simple à prendre en main me semble ouvrir de nombreuses possibilités.
Humanités numériques : prêt(sque)
112 années
par Etienne Cavalié.
dans Grand angle
L’informatique est entré dans le monde des chercheurs en sciences humaines depuis longtemps déjà. On présente souvent le père Roberto Busa comme l’un des initiateurs de ces pratiques, qui avec l’aide d’IBM a automatisé l’analyse lexicale des textes de Thomas d’Aquin dès le début des années 1950.
Il est donc tout naturel que les recherches en linguistique soient déjà familiers de ces enjeux depuis longtemps. Y compris à Nice.
Néanmoins, le traitement informatisé n’est pas la seule dimension de ce qu’on appelle désormais les humanités numériques.
Il a fallu quelques années pour que la communauté scientifique intègre que les promesses apportées par le numérique changeaient non seulement les outils de la recherche, mais aussi ses perspectives.
Et c’est finalement tout une nouvelle culture qui se met en marche.

Manifeste des Digital humanities – THATCamp – Paris 2010 – image Wikimedia Commons – CC-BY-SA-2.0
Les digital humanities, ou humanités numériques, sont une idée dans l’air du temps, dont la vogue n’est pas sans rappeler celle du web 2.0 il y a quelques années.
Néanmoins l’expression est également un concept permettant de désigner les conséquences sur la nature même de l’activité de recherche, notamment :
- l’accès facilité aux données
Auparavant, le temps du chercheur ou du doctorant pouvait être consacré à simplement constituer un corpus. L’alimentation de ce corpus justifiait en soi des mois ou années de recherche (à charge pour les successeurs de l’exploiter). - le passage de l’échantillon aux Big Data
les historiens travaillent souvent sur des archives éparses, clairsemées — bref : rares.
Exploiter l’état des paroisses et des feux de 1328 ne ressemble pas vraiment à l’utilisation qu’on peut faire des bases Insee relatives à la population française (et toutes autres sources parallèles). L’utilisation de ces données ne va pas de soi. - La production scientifique : les confrères n’attendent plus seulement de pouvoir bénéficier de l’article final. Les données brutes qui ont servi à l’élaborer, voire la base de données constituée pour l’occasion, doivent être mises à disposition.
Donc en ligne.
Donc dans des formats exploitables (et il y a une vie après le CSV). - La publication scientifique : Word, ce n’est pas une machine à écrire avec écran et la possibilité de cliquer sur Ctlr+Z. De même, le numérique, ce n’est pas que de la bureautique.
La diffusion en ligne permet de produire autre chose que du texte : des PDF contenant des images 3D, des frises chronologiques dynamiques — plus largement, toute une diversité de possibles sur la manière de donner à voir les résultats de la recherche
Source : « Map Geocoded data with Gephi » – 17 mai 2010
- La diffusion scientifique au plus grand nombre.
Internet ouvre un champ nouveau de lecteurs : les citoyens.
Mais cette large diffusion n’est possible que si certains acteurs ne remettent pas des enclosures informationnelles, c’est-à-dire des barrières (juridiques, financières, techniques) qui dépossèdent le grand public du savoir produit dans les établissements de recherche.
Humanités numériques + bibliothèques = ?
Avec les humanités numériques, il est question de ressources, il est question de formats, de gestion, de traitement et d’enrichissement des données, de production scientifique, de pérennité, d’accès, de droits de réutilisation, de diffusion du savoir.
Bref, il est question de plein de dimensions dont les bibliothèques sont familières. Où elles peuvent accompagner les projets de recherche, par exemple :
- sur l’identification des référentiels à exploiter pour produire et publier des données
- sur les licences disponibles à associées à ces jeux de données, et plus globalement sur leur mode de gestion
- sur les questions de T&D mining (et notamment les services – ou pas – proposés par les grands éditeurs)
- sur la diffusion du savoir, notamment avec la mise à disposition immédiate via une archive ouverte
Pour aller plus loin
- HumanLit, un carnet d’Hypotheses.org sur les humanités numériques
- Une infographie sur les résultats d’une enquête menée par HumanLit portant sur les humanités numériques, portant sur la perception de cette notion auprès des chercheurs
- Renseigner une autre enquête sur les humanités numériques de Dariah-EU, visant à « comprendre comment les chercheurs européens utilisent les ressources, les méthodes et les outils numériques, et de quelle manière les infrastructures numériques peuvent répondre à leurs besoins » (afin de mieux développer leur offre de service).
