Le blog des BU sur les publications électroniques et les données de la recherche
Articles taggués API
Le web de données, Isidore adore !
111 années
par Géraldine Geoffroy.
dans Zoom sur...
L’API d’Isidore pour en explorer les données, c’est chouette. L’accès par un Sparql Endpoint, c’est encore mieux !
Mais avant toute chose, un petit crochet par les concepts et technologies de base du Linked Open Data s’impose (car c’est de cela qu’il s’agit).
Et commençons donc par le formalisme RDF (pour Resource Description Framework) qui ne désigne rien de moins que le modèle de description et de publication des ressources et des métadonnées sur le web. Cette modélisation s’appuie sur 3 fondamentaux :
- Des triplets : une ressource est décrite par un ensemble de triplets, chaque triplet étant constitué par une association du type <sujet><prédicat><objet>, à l’image d’une structure grammaticale sujet-verbe-complément. Par exemple <ce livre><a pour titre>< Merci pour ce moment>, <ce livre><a été écrit par><Valérie Trierweiler> etc.. sont des triplets caractérisant l’opus en question.
- Des ontologies et des thésaurus : ce sont des modélisations (elles-mêmes structurées en triplets RDF) de représentations des connaissances (par exemple le Dublin Core). Dans les triplets RDF, Les prédicats se fondent donc sur les ontologies existantes pour typer les relations sujets-objets, c’est-à dire les sémantiser.
- Des URI : des identifiants pérennes sur le web pour chaque métadonnée. Une URI peut être une URL qui donne accès au contenu de la ressource (on parle alors URI déréférencée), mais pas que…Les sujets et prédicats des triplets RDF sont toujours des URI, tandis que les objets sont soit des URI soit des littéraux. Ainsi nos triplets précédents s’expriment (dans la notice RDF du Sudoc)
<http://www.sudoc.fr/180856936/id> <dc:title> “Merci pour ce moment" <http://www.sudoc.fr/180856936/id"> <marcrel:aut> <http://www.idref.fr/115490108/id>
L’ensemble des triplets constitutifs d’une base de données RDF (Isidore, le Sudoc, l’INSEE, DBPedia…) sont stockés dans un triplestore et forment donc un graphe qu’il est possible de requêter grâce au langage Sparql (assez similaire au SQL, le langage de requête des bases de données relationnelles) via un point d’accès web, un Sparql Endpoint.
Retour donc à Isidore dans le web de données : Isidore moissonne ses diverses sources selon le protocole OAI-PMH, c’est-à dire rapatrie des sets de données en format Dublin Core, les convertit en triplets RDF, les enrichit par croisement avec des référentiels externes, puis stocke tout ça dans un triplestore accessible avec Sparql par le Sparql Endpoint Virtuoso d’Isidore.
Et illustration de l’intérêt de tout ça avec un cas pratique : comment exploiter les données d’Isidore afin d’obtenir et étudier un corpus constitué de composants Calames et de publications autour des fonds patrimoniaux que possède ma BU (par exemple Henri Bosco, Gabriel Germain, Georges Perros, Samivel… et Michel Butor tant qu’on y est) ?
Pour commencer, on formule sa requête dans le Sparql Endpoint, ici une requête de type CONSTRUCT qui permet d’obtenir un set de résultats formant lui-même un graphe « personnalisé » à partir du graphe d’Isidore, puis on choisit la sérialisation (le format de sortie, RDF/XML en l’occurence) de ce nouveau graphe :
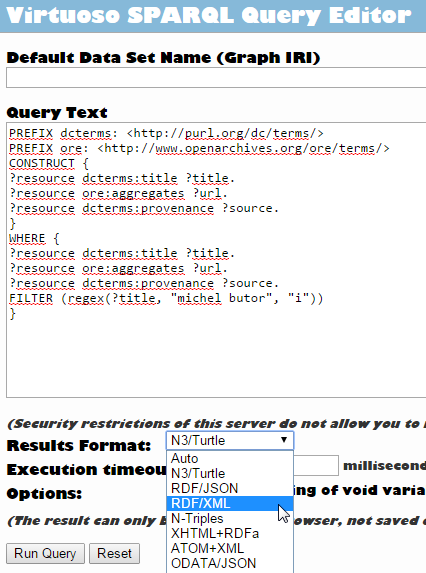
Graphe que l’on peut donc visualiser comme tel :
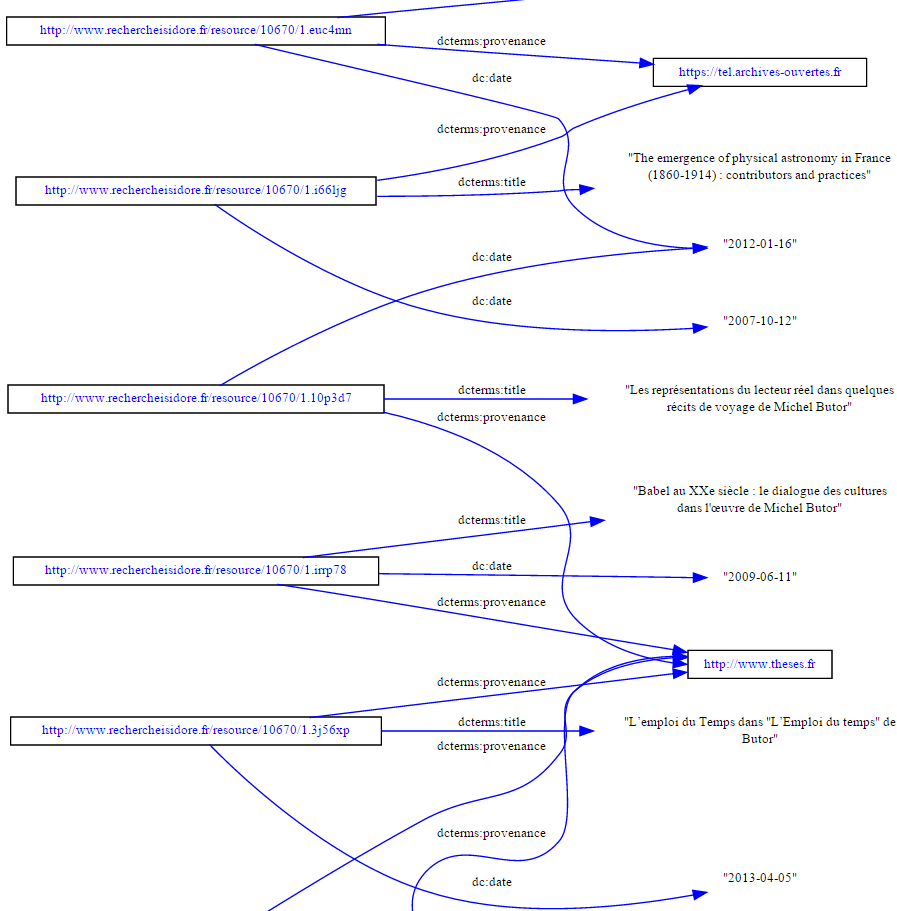
Ou plus joli, plus dynamique et en ligne :
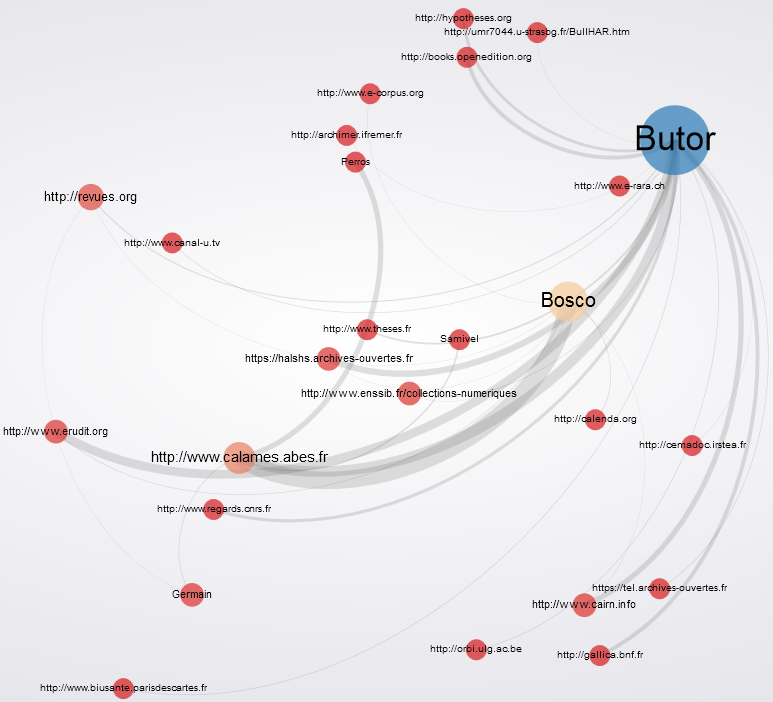
On peut aussi (essayer de) faire de jolis graphiques de visualisation statistique du corpus constitué : poids relatifs de chaque auteur dans les résultats, répartition par source de données…
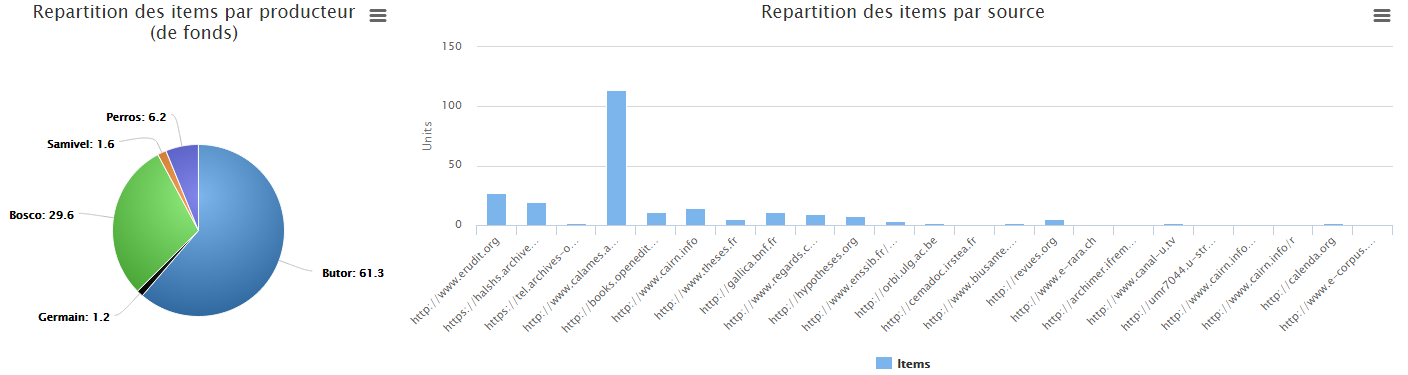
Dans la même lignée, puisque Isidore enrichit ses données avec le référentiel Geonames, rien n’empêche de cartographier l’ensemble des résultats. Et puisque data.bnf propose aussi son Sparql Endpoint, pourquoi ne pas faire une réquête conjointe sur le graphe d’Isidore et celui de data.bnf afin de s’approcher d’une vue FRBRisée (hiérarchisée) des documents relatifs à ces fonds ? Par exemple pour le fonds Henri Bosco :
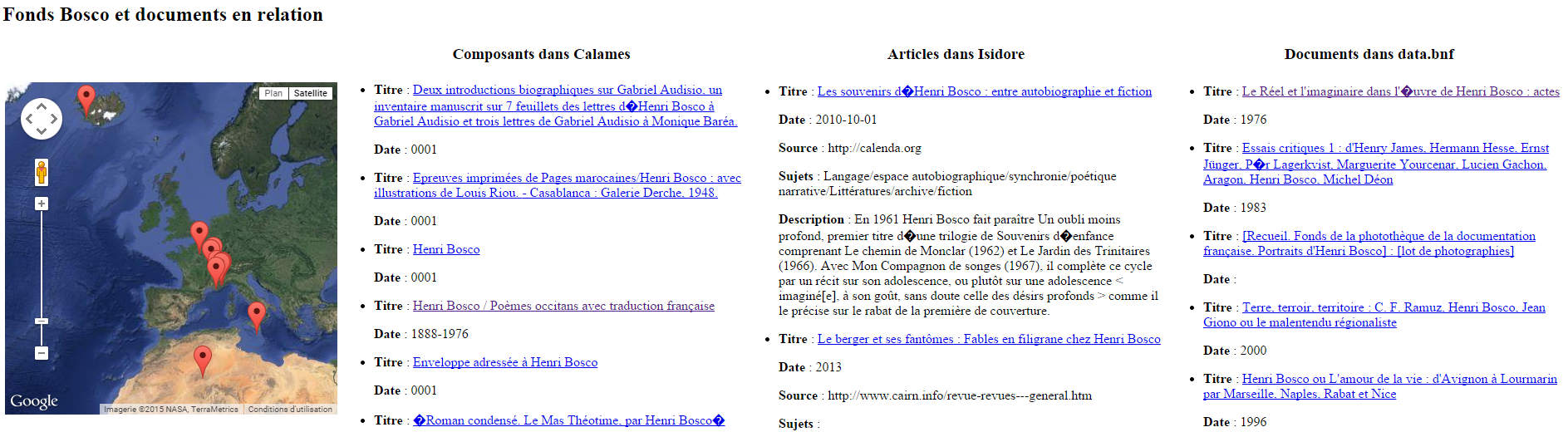
Pour visualiser la page web, c’est ici
Ainsi, les métadonnées d’Isidore formalisées en RDF, c’est la possibilité de :
- s’affranchir du niveau des notices et parcourir le graphe ouvert d’Isidore au niveau des données et non plus des notices
- exploiter l’interopérabilité de données sorties de leurs silos et structurées selon le même formalisme, indépendamment de leurs formats natifs (le web de données)
- pouvoir lier les données entre elles grâce aux URI et aux alignements des ontologies entre elles (le linked open data)
- d’exploiter sémantiquement le typage des relations entre sujets et objets, d’appliquer des algorithmes d’exploration sémantique grâce aux prédicats définis par des ontologies elles-mêmes définies sur le web (compréhensibles par des machines) pour un traitement « intelligent » des données (le web sémantique)
Au-delà des formats et des normes, il est sans doute là l’enjeu pour nos données bibliographiques comme pour les autres (données de gestion , données de la recherche…) : s’inscrire dans cette nouvelle brique de l’architecture du web où ce ne sont plus les pages html ou les documents qui sont liés mais les données et participer à la constitution d’un graphe, un jour, devenu universel.
Logiciels libres utilisés : Rhizomik RedeFer (et ses supers API), gexf-js Viewer, Highcharts
NB : pour ceux qui la chercheraient, il y encore une culotte quelque part…
Happy Isidore ! (Prononcer : A-P-I Isidore)
211 années
par Géraldine Geoffroy.
dans Zoom sur...
Ou comment extraire, exploiter, retraiter et visualiser les données d’Isidore avec un cas pratique…
Isidore : une interface unique en SHS de 3 millions de notices
Isidore est un portail d’accès unifié aux publications électroniques (principalement francophones) en sciences humaines et sociales, développé depuis 2011 dans le cadre de la Très Grande Infrastructure dédiée aux humanités numériques, le TGIR Human-num.
Isidore moissonne et agrège les données de multiples sources et bases de données telles que Revues.org, Persée, Gallica, Calames, Cairn, Dumas, Erudit…, soit en tout plus de 3 millions de documents.
Des informations enrichies
Mais plus intéressant encore, Isidore s’appuie sur les technologies de ce que l’on appelle le LOD (Linked Open Data), pour enrichir les données engrangées d’information, grâce à des sources complémentaires.
Parmi celles-ci, citons :
- le référentiel disciplinaire européen de HAL,
- la base de données géographique Geonames,
- le thésaurus PACTOLS spécialisé en archéologie et sciences de l’Antiquité,
- le répertoire d’autorités RAMEAU…
Lorsque chaque notice est récupérée par Isidore, elle est enrichie grâce à ces différentes sources. Donc, lorsqu’on fait une recherche via Isidore, les notices récupérées présentent plus d’informations que dans leur base de données source : une indexation plus riche, des données de géolocalisation, d’autres notices liées…
Des informations facilement récupérables
C’est déjà beaucoup, mais il y a encore mieux : Isidore expose ses données, il permet aux utilisateurs de les récupérer pour les ré-exploiter ensuite dans d’autres environnements.
Un des points d’accès proposé pour cela est l’API web d’Isidore : derrière ce sigle un peu mystérieux que l’on traduit en français par « interface de programmation« , on parle en fait d’un service par lequel un logiciel, un fournisseur expose tout ou partie de ses données et/ou de ses fonctionnalités.
Revenons donc à Isidore : l’API est documentée sur ce site, on peut y effectuer une recherche classique par un formulaire de recherche. La recherche fournit une liste de résultats web (format HTML normal), mais en cliquant sur « Informations techniques », on obtient un lien vers les mêmes résultats, mais en XML.
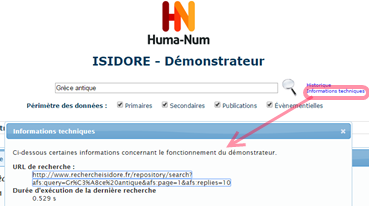
Ce format est :
- structuré (il distingue les titres, les auteurs, les dates, etc.)
- enrichi (pour un auteur donné, il renvoie vers différentes sources où cet auteur est référencé ; il rajoute diverses indexations)
- interopérable (on peut récupérer ce fichier XML pour le « manipuler » à d’autres fins)
Bon, c’est là que ça se complique un peu car ces notices en XML, on n’en fait rien en tant que telles : il faut savoir les manipuler avec des langages comme XSLT ou PHP pour les exploiter, les convertir sous d’autres formats, bref les redistribuer.
Cas pratique
Mais assez de blablas, un bon exemple valant mieux que de longs discours, Imaginons que je commence une thèse sur le concept de culotte comme indicateur sociétal en France.
Je souhaite donc commencer par faire une cartographie de l’ensemble des publications francophones sur la culotte sous ses dimensions historiques, sociales, linguistiques etc… Pour cela j’ai donc besoin de constituer un corpus de références de publications (une bibliographie du sujet) que je pourrai ensuite analyser en le soumettant à d’autres logiciels d’exploration et de visualisation.
J’interroge donc l’API d’Isidore en utilisant le mot-clé « Culotte » soit « http://www.rechercheisidore.fr/repository/search?afs:query=Culotte&afs:page=1&afs:replies=100 » (les derniers paramètres indiquant que j’affiche d’abord la page 1 de la liste de résultats et que je souhaite afficher 100 résultats par page). En interrogeant l’API de manière récursive sur toutes les pages de résultats, j’obtiens en réponse 836 notices, que je peux donc manipuler (si je parle le XSLT, ou si je demande à ma BU qui le connaît), transformer en XML, CSV, JSON, ou tout autre format et ensuite analyser comme je le souhaite.
Ainsi, en passant par l’API Isidore (plutôt que la recherche standard), je peux pour chaque notice obtenir le lieu de publication de la ressource décrite, et sa discipline. Je peux ainsi confronter répartition géographique et disciplinaire des publications moissonnées :
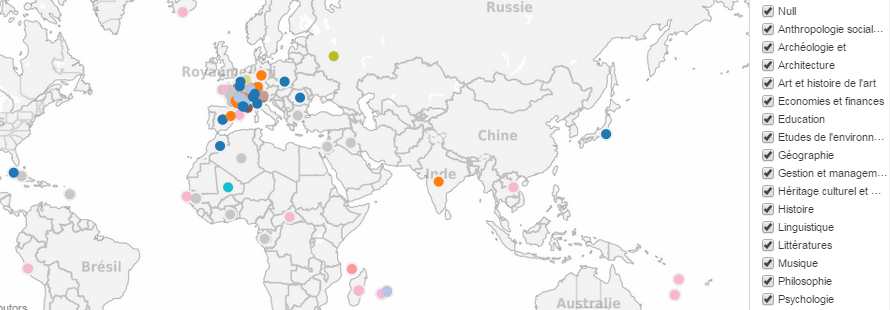
Publications scientifiques sur la « culotte » : répartition géographique et disciplinaire – visualisation obtenue avec le logiciel Tableau Public
Ou encore visualiser sous forme de graphe les relations de proximité entre concepts :
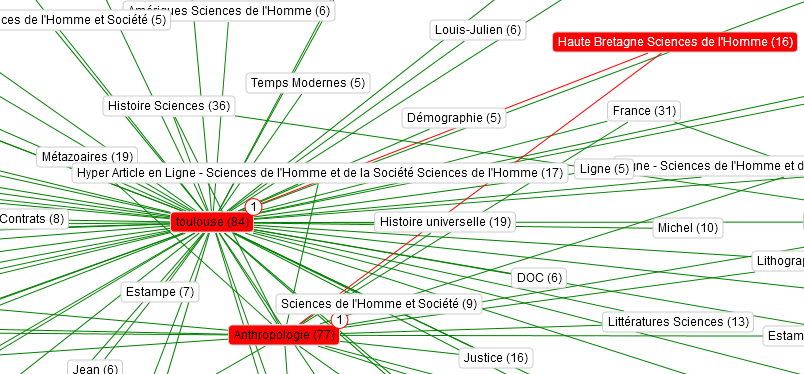
Concepts associés à chaque notice et liens entre eux – visualisation obtenue avec le logiciel Voyant Tool
Ou encore extraire les résumés dans l’ordre chronologique et en étudier les fréquences d’apparition de certains mots :
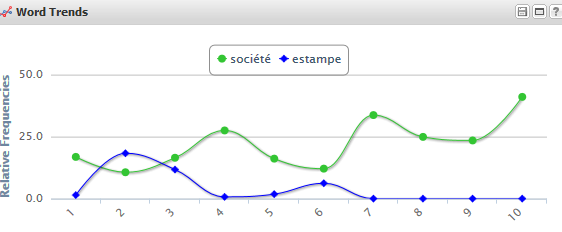 Fréquence de certains mots-clés dans les 836 ressources traitant de la culotte – visualisation obtenue avec Voyant Tool
Fréquence de certains mots-clés dans les 836 ressources traitant de la culotte – visualisation obtenue avec Voyant Tool
Ou encore etc…
A partir du même exemple, vous pouvez visualiser sur cette page web d’autres types d’exploitation de données récupérées grâce à l’API d’Isidore, véritable sésame pour l’exploration de corpus bibliographiques en SHS.
Logiciels libres utilisés : Tableau Public, Voyant Tools, Simile Exhibit.
NB : les données aspirées par l’API l’ont été uniquement pour l’exemple, elles n’ont pas été nettoyées de toutes leurs « scories » éventuelles, ce qui explique un affichage pas toujours très « propre ».
A suivre
Dans un prochain billet : le Sparql Endpoint d’Isidore, un autre point d’accès pour explorer sémantiquement les données d’Isidore structurées en RDF.
