Le blog des BU sur les publications électroniques et les données de la recherche
Zoom sur…
Des articles dédiés à une ressource en particulier : une base de données, un site des revues en ligne…
Frantext version 2
8 années
par Ingrid Da Silva.
dans Zoom sur...
A l’occasion du passage à une nouvelle version, modernisée et enrichie, de la base Frantext, nous vous proposons un focus sur cette base de données textuelle.
![]()
Tout d’abord, qu’est-ce que Frantext ?
- le fruit du travail d’une équipe de l’ATILF-CNRS : une vingtaine de chercheurs, d’enseignants-chercheurs, d’ingénieurs et de collaborateurs scientifiques qui travaillent en lien avec des spécialistes en sciences du langage, en littérature française, des informaticiens ainsi qu’une équipe en charge de la numérisation et du balisage
- une base de données de textes français littéraires et philosophiques, mais aussi scientifiques et techniques (environ 10%) qui vont de 950 à nos jours : 4987 références dont 1026 sont postérieurs à 1950
- des corpus sélectionnés en fonction de leur diversité et représentativité : textes littéraires classiques, presse, ouvrages scientifiques, livres de cuisine, traités de cynégétique, manuels, romans policiers…
- des possibilités de recherches simples et complexes sur des formes, des lemmes ou des catégories grammaticales dans un corpus donné
- attention : cette base ne permet pas le téléchargement ni la lecture des textes en version intégrale. Les versions numériques des textes libres de droit sont téléchargeables sur le site du CNRTL.
Quelles nouveautés grâce à Frantext 2 ?
- une interface modernisée
- la création simplifiée d’un corpus à partir des métadonnées : corpus prédéfinis, création personnalisée de corpus
- des corpus enrichis, lemmatisés et catégorisés
- l’usage des expressions régulières et CQL (Corpus Query Language) dans les recherches avancées, listes de mots et grammaires avec assistant de conception des requêtes
- de nouvelles fonctionnalités de tri, filtre et visualisation des résultats
La version 2 de Frantext remplacera définitivement la 1ère version à partir du 30 juin. Pour vous aider à utiliser cette nouvelle version, une documentation est disponible ici.
Votre tableur atteint ses limites? Préparez vos données avec Openrefine
9 années
OpenRefine est un logiciel libre et gratuit permettant de nettoyer, préparer et enrichir des données. Il est utilisé dans le monde des bibliothèques mais aussi par des étudiants et chercheurs dans différentes disciplines.
![]()
Avant de pouvoir analyser des données, il est souvent nécessaire de les nettoyer (harmoniser des valeurs hétérogènes, repérer des anomalies, etc.), de les préparer (changement de format, réorganisation des colonnes, etc.), ou de les enrichir.
Vous avez certainement l’habitude de réaliser ces opérations avec un tableur (Excel, Libreoffice, Google Drive…), ou pour certains d’entre-vous avec des scripts rédigés dans différents langages informatiques (R, Python, Bash…). Mais il existe des outils spécifiques, plus simples d’utilisation que les langages de script, et possédant des fonctions absentes des tableurs traditionnels. Openrefine est l’un d’eux.
Ce 23 octobre, nous avons proposé un atelier de découverte de cet outil au LearningCentre SophiaTech. Pour toutes les personnes qui n’ont pas pu y assister, voici le support créé pour l’occasion :
Si vous souhaitez en savoir plus sur cet outil ou d’autres du même type, n’hésitez pas à nous contacter : donnees-scd@unice.fr
Universalis : l’encyclopédie 3 en 1
9 années
par Ingrid Da Silva.
dans Zoom sur...
Pour Universalis, la rentrée rime avec nouveautés. Depuis le 1er septembre, la version en ligne de cette encyclopédie propose une interface et des fonctionnalités nouvelles. A cette occasion, nous vous proposons un focus sur cette ressource électronique.
Universalis, c’est la possibilité de faire des recherches en ligne dans 3 outils :
Une encyclopédie
-
des articles rédigés par des spécialistes sur de nombreux sujets : arts, sciences humaines et sociales, lettres, droit, sciences politiques, sciences de la Terre, biologie…
-
des articles illustrés avec photographies, dessins, cartes vidéos, animations, extraits sonores, diaporamas… et accompagnés de bibliographies
-
des articles imprimables, exportables et disponibles en format audio
-
des fiches de lecture pour les œuvres littéraires
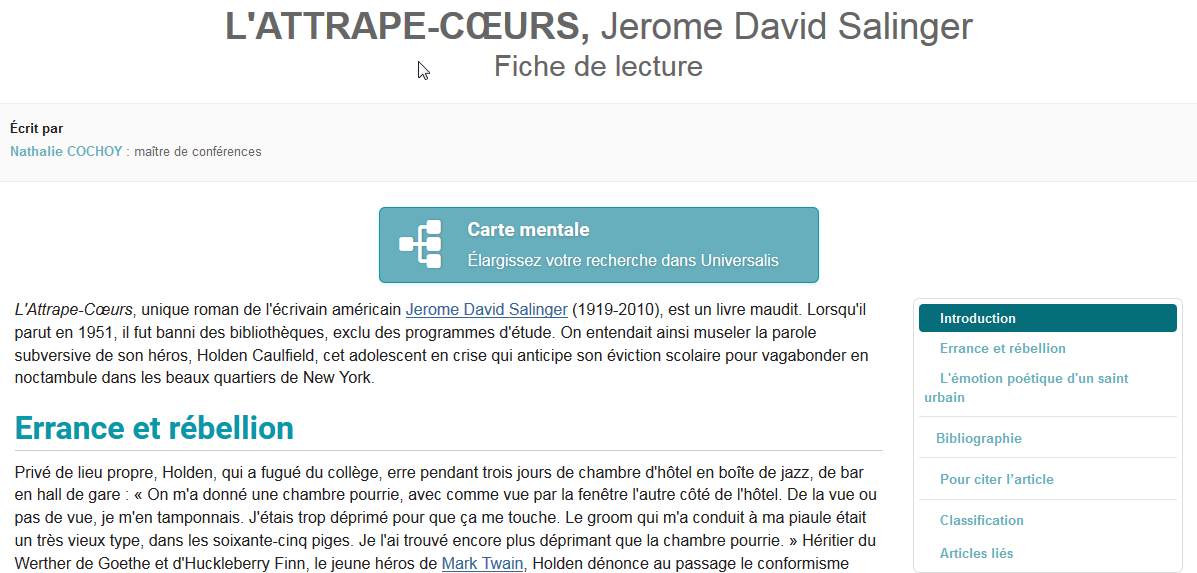
-
une carte mentale interactive pour élargir facilement vos recherches :
Un atlas
-
plusieurs types de cartes : générale, de situation, administrative, physique…
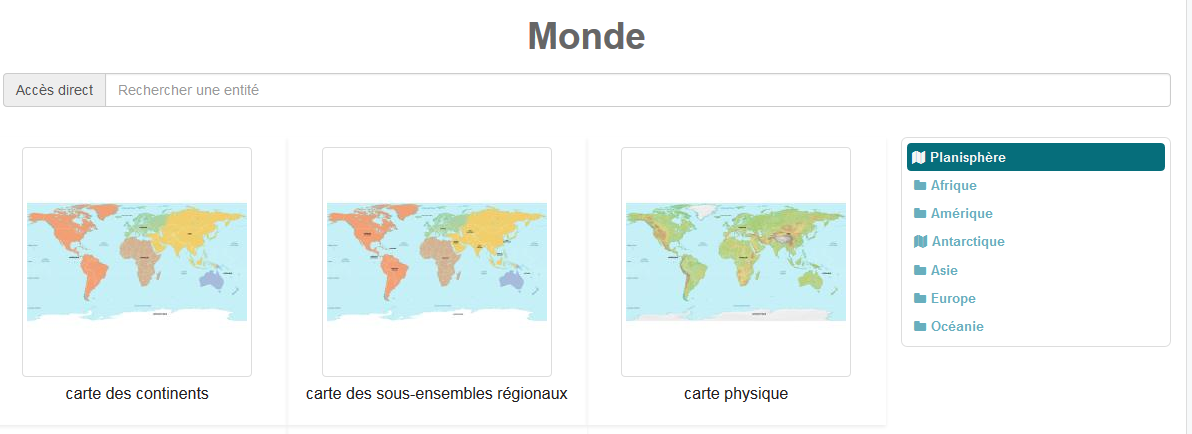
-
des données et chiffres clés
Un dictionnaire
-
plus de 122 000 définitions de noms communs

-
des renvois depuis les articles vers la définition des termes
Retrouvez ici des tutoriels pour connaître toutes les astuces de recherche dans Universalis.
Et pour plus d’informations, n’hésitez pas à écrire à docelec@unice.fr.
What’s the MOOC !!! ????
010 années

Vous avez envie d’aller plus loin que vos cours à l’Université Nice Sophia Antipolis, sans quitter ce paradis ! Internet vous offre tant d’opportunités : le MOOC (massive open online course) est à la fois une nouvelle mode et une nouvelle ressource pour votre avenir.
Véritable parcours pédagogique construit par des spécialistes, généralement sur plusieurs semaines, voire mois, ces cours en ligne se caractérisent par l’usage de ressources éducatives libres (vidéos en ligne, mais aussi forums, procédés d’évaluation en ligne…), par leur ouverture massive via les nouvelles technologies et la logique de l’accès libre, c’est-à-dire ouverts à tous les usagers potentiels, étudiants, chômeurs, retraités, curieux de tous bords… (même si attention, tous les MOOC ne sont pas gratuits).

L’un des plus importants réservoirs français de cours est FUN-MOOC, qui propose autant des cours pour réussir les DELF et DALF, que des introductions aux technologies du web de données et web sémantique par l’INRIA Sophia Antipolis, membre de l’Université Côte d’Azur.
 Pour se tenir au courant des MOOC en cours ou à venir, le Ministère de l’Enseignement supérieur tient à jour un calendrier des MOOC des principales plate-formes françaises. L’Université d’Artois proposait très récemment un MOOC « MOOC Fantasy, de l’Angleterre victorienne au Trône de fer ». Il existe également des annuaires de MOOC, très bien présentés par le Blog OutilsTice, afin de vous aider à vous repérer dans le choix immense du web.
Pour se tenir au courant des MOOC en cours ou à venir, le Ministère de l’Enseignement supérieur tient à jour un calendrier des MOOC des principales plate-formes françaises. L’Université d’Artois proposait très récemment un MOOC « MOOC Fantasy, de l’Angleterre victorienne au Trône de fer ». Il existe également des annuaires de MOOC, très bien présentés par le Blog OutilsTice, afin de vous aider à vous repérer dans le choix immense du web.
Et si vous n’avez pas le courage de suivre un MOOC sur plusieurs mois, vous pouvez picorer à droite et à gauche des contenus plus courts, conférences, colloques… Beaucoup d’institutions mettent désormais en ligne leurs contenus : par exemple, le Collège de France propose les textes de nombreuses leçons et conférences en ligne sur OpenEditions, ainsi que les versions vidéo ou audio. A voir la toute récente leçon inaugurale de l’écrivain Alain Mabanckou « Lettres noires : des ténèbres à la lumière », retraçant le parcours de la littérature coloniale à la littérature « négro-africaine », ou les cours de Yann LeCun, autorité dans le monde de l’Intelligence artificielle, sur l’apprentissage profond.
L’Enseignement supérieur a également son propre site, Canal-u, qui propose des conférences sur des thématiques aussi larges que « Les multiples conditions pour l’habitabilité des ![]() planètes », d’André Maeder, professeur émérite à l’Observatoire de Genève, aux « Histoires de Hou Hsia-Hsien » de Wafa Gherman, à la Cinémathèque française.
planètes », d’André Maeder, professeur émérite à l’Observatoire de Genève, aux « Histoires de Hou Hsia-Hsien » de Wafa Gherman, à la Cinémathèque française.
Diversité, multidisciplinarité, ouverture… A vous d’explorer maintenant !!!
50 ans d’activité scientifique, 50 ans d’open access, 50 ans de collaborations
011 années
par Publications électroniques UNS.
dans Zoom sur...
J’ai décrit dans un précédent billet le contenu de HAL-Unice, en terme de volumétrie.
Rappelons que les constatations sont faites pour le corpus constaté, c’est-à-dire les archives déposées dans HAL, et les articles signalés par les chercheurs dans HAL. Ce corpus ne prend donc en compte
- ni l’ensemble de la publication scientifique de l’Université
- ni même l’ensemble de la politique d’open access des structures de recherche de l’Université, car il existe d’autres dépôts d’archives en France et dans le monde
Si les archives déposées dans ArXiv par des chercheurs français se retrouvent automatiquement dans HAL, ce n’est pas le cas par exemple de CiteSeerx, dans lequel on trouvera de nombreux articles déposés par des chercheurs affiliés à l’Université de Nice, qui ne sont pas du tout signalés dans HAL.
Par ailleurs les disciplines sont inégalement représentées du fait aussi des pratiques de publication des chercheurs, directement liées aux conditions d’évaluation (ex : publier un ouvrage compte-t-il ou non ?) et aux pratiques des communautés scientifiques et des maisons d’édition.
Pour les archives qui y sont déposées ou signalées, HAL-Unice constitue-t-il un bon corpus pour donner à voir toutes les collaborations entre laboratoires et structures de recherche ? On peut toujours essayer.
A chaque notice est associée l’affiliation du ou des auteurs. Cette affiliation est presque toujours exprimée de manière double, quand elle désigne le nom du labo et l’université de rattachement de celui-ci ; ou triple quand il s’agit d’une UMR, rattachée à la fois au CNRS et à l’Université.
En moyenne, une ressource est affiliée à 6 structures de recherche, avec un maximum de 56 pour l’ensemble étudié…
On peut donc considérer que chaque article est le fruit d’une collaboration entre les structures de recherche auxquelles appartiennent leurs auteurs. Chaque article donne à voir une collaboration entre deux structures de recherche.
De manière plus globale (c’est-à-dire en regardant les liens entre les structures de recherche, non pas notice par notice mais pour l’ensemble du corpus), on découvre tout un réseau continu entre les établissements.

Explications
Les données qui ont permis de générer ce graphe :
A chaque article est associé un ou plusieurs « sets ». Quand il y a plusieurs affiliations d’établissements, cela apparaît sous la forme :
<collection>UNICE</collection> <collection>SHS</collection> <collection>EPHE</collection> <collection>INRAP</collection> <collection>CNRS</collection> <collection>UNIV-TLSE2</collection> <collection>CEPAM</collection> <collection>TRACES</collection> <collection>CBAE</collection> <collection>UNIV-MONTP3</collection> <collection>UMR5140</collection> <collection>UNIV-AMU</collection> <collection>MMSH</collection> <collection>LADIR</collection> <collection>UPMC</collection>
On a considéré qu’à travers cette liste, chaque structure de recherche était liée à chacune des autres, ce qui a généré toutes les paires possibles :
UNICE;SHS / UNICE;EPHE / UNICE;INRAP / UNICE;CNRS / UNICE;UNIV-TLSE2 / UNICE;CEPAM / UNICE;TRACES / UNICE;CBAE / UNICE;UNIV-MONTP3 / UNICE;UMR5140 / UNICE;UNIV-AMU / UNICE;MMSH / UNICE;LADIR / UNICE;UPMC / SHS;EPHE / SHS;INRAP / SHS;CNRS / SHS;UNIV-TLSE2 / SHS;CEPAM / SHS;TRACES / SHS;CBAE / SHS;UNIV-MONTP3 / SHS;UMR5140 / SHS;UNIV-AMU / SHS;MMSH / SHS;LADIR / SHS;UPMC / EPHE;INRAP / EPHE;CNRS / EPHE;UNIV-TLSE2 / EPHE;CEPAM / EPHE;TRACES / EPHE;CBAE / EPHE;UNIV-MONTP3 / EPHE;UMR5140 / EPHE;UNIV-AMU / EPHE;MMSH / EPHE;LADIR / EPHE;UPMC / INRAP;CNRS / INRAP;UNIV-TLSE2 / INRAP;CEPAM / INRAP;TRACES / INRAP;CBAE / INRAP;UNIV-MONTP3 / INRAP;UMR5140 / INRAP;UNIV-AMU / INRAP;MMSH / INRAP;LADIR / INRAP;UPMC / CNRS;UNIV-TLSE2 / CNRS;CEPAM / CNRS;TRACES / CNRS;CBAE / CNRS;UNIV-MONTP3 / CNRS;UMR5140 / CNRS;UNIV-AMU / CNRS;MMSH / CNRS;LADIR / CNRS;UPMC / UNIV-TLSE2;CEPAM / UNIV-TLSE2;TRACES / UNIV-TLSE2;CBAE / UNIV-TLSE2;UNIV-MONTP3 / UNIV-TLSE2;UMR5140 / UNIV-TLSE2;UNIV-AMU / UNIV-TLSE2;MMSH / UNIV-TLSE2;LADIR / UNIV-TLSE2;UPMC / CEPAM;TRACES / CEPAM;CBAE / CEPAM;UNIV-MONTP3 / CEPAM;UMR5140 / CEPAM;UNIV-AMU / CEPAM;MMSH / CEPAM;LADIR / CEPAM;UPMC / TRACES;CBAE / TRACES;UNIV-MONTP3 / TRACES;UMR5140 / TRACES;UNIV-AMU / TRACES;MMSH / TRACES;LADIR / TRACES;UPMC / CBAE;UNIV-MONTP3 / CBAE;UMR5140 / CBAE;UNIV-AMU / CBAE;MMSH / CBAE;LADIR / CBAE;UPMC / UNIV-MONTP3;UMR5140 / UNIV-MONTP3;UNIV-AMU / UNIV-MONTP3;MMSH / UNIV-MONTP3;LADIR / UNIV-MONTP3;UPMC / UMR5140;UNIV-AMU / UMR5140;MMSH / UMR5140;LADIR / UMR5140;UPMC / UNIV-AMU;MMSH / UNIV-AMU;LADIR / UNIV-AMU;UPMC / MMSH;LADIR / MMSH;UPMC / LADIR;UPMC
L’ensemble de ces paires a ensuite été chargée dans Gephi, pour obtenir une clusterisation et une répartition spatiale qui a rapproché les établissements travaillant le plus souvent ensemble, et attribuant (ou tentant d’attribuer) des couleurs par sous-groupes.
Le corpus considéré de manière « brute » (sans sélection des données traitées) laisse entendre qu’il n’y a pas vraiment de sous-ensembles nets : aucun groupe de noeuds ne se détache vraiment des autres, il y a plutôt, dans l’activité de publication, un continuum de la recherche.
Limites et reprises
On peut voir d’emblée au moins 3 limites aux données en entrée :
- il y a un trop grand nombre de noeuds (1177 « établissements » distincts) et de liens (31.000 liens distincts) pour obtenir un graphe satisfaisant
- Les données en entrée ne sont pas propres : les collections « SHS », « AO-ECONOMIE », ne sont pas des établissements
- Les universités sont sur le même plan que les laboratoires : donc toutes les universités sont finalement liées entre elles (via leurs laboratoires, y compris ceux qui ne travailleraient que dans un champ disciplinaire bien précis, et avec une liste fermée d’autres laboratoires du même champ disciplinaire).
Cette absence de partition en sous-groupes est donc inévitable tant qu’on prend en compte les universités.
Voici donc 2 autres tentatives pour voir si une visualisation différente pourrait se dégager :
1. Données en entrée nettoyées des mentions de domaines de recherche, et des noms d’Université (ou CNRS)
Dans le graphe ci-dessous, les universités et le CNRS ont été retirées. Ne sont conservées que les structures de recherche de type Laboratoire ou Institut.
On passe ainsi à 1063 établissements (nœuds) et 18.000 liens :

Certains sous-ensembles se dégagent mieux (le graphe est moins uniforme) : SophiaTech et l’INRIA avec le labo de math J.A. Dieudonné ; les laboratoires de l’OCA (en vert) – et juste à côté, dans un vert légèrement différent, des structures de recherche en SHS (la plus visible sur le graphe étant le CEPAM).
Pourtant de nombreux liens existent manifestement entre ces groupes, et on continue d’observer le continuum évoqué plus haut.
2. Données en entrée : les liens les plus importants
Une méthode supplémentaire pour « nettoyer » les données consiste à évacuer toutes les collaborations trop ponctuelles (1 à 5 occurrences), pour ne conserver que celles qui se sont répétées pour la rédaction de plusieurs archives déposées.
Ci-dessous le graphe exploitant les collaborations répétées au moins 6 fois dans le corpus étudié (404 structures de recherche, 2830 liens) :

Le risque est évidemment de faire disparaître des laboratoires très présents dans le corpus initial, mais qui travaillent ponctuellement avec un grand nombre d’autre laboratoires très diversifiés : chaque lien concernant ce labo apparaissant peu de fois, il finit par disparaître complètement du graphe…
661 structures sont évacuées suite à ce filtre supplémentaire, mais aucune ne relève de l’Université Nice Sophia Antipolis (qui est le sujet de ce billet).
Ultime remarque : les SHS semble avoir disparu dans la masse. Du coup, voici un graphe rien que pour eux.

Celui-ci est dynamique et permet notamment de filtrer sur le nom d’un labo (via le petit moteur de recherche dans l’en-tête), pour voir identifier ses partenaires et sa position dans le réseau.
Pourquoi dans le graphe global ne voit-on presque plus que des structures de recherche en sciences ? Parce que dans les archives déposées ou signalées dans HAL-Unice, les SHS indiquent beaucoup moins d’affiliations : les collaborations entre labos sont en moins grand nombre :
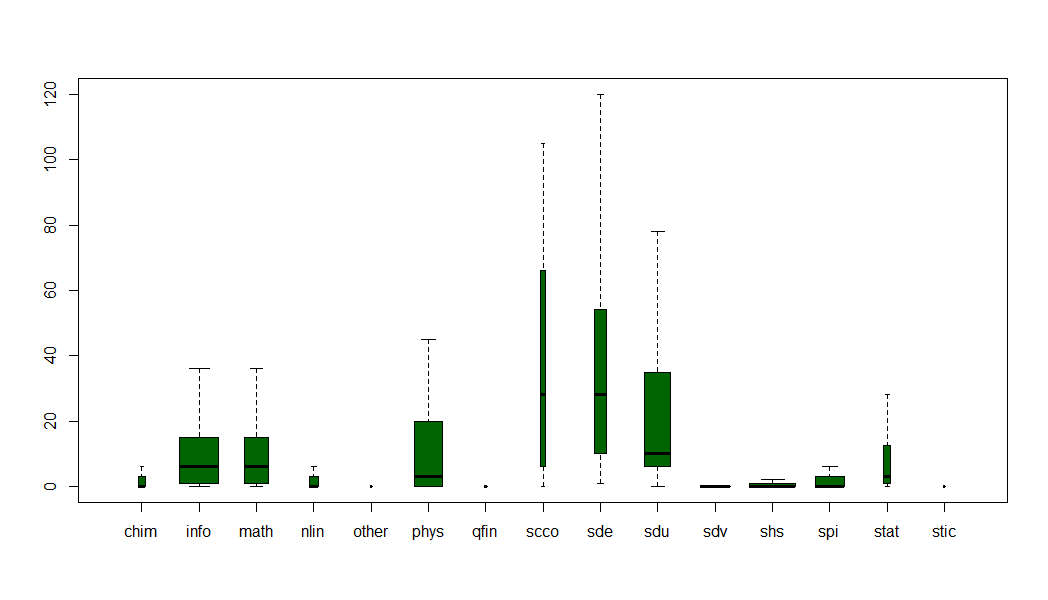
Comment lire ce graphique ?
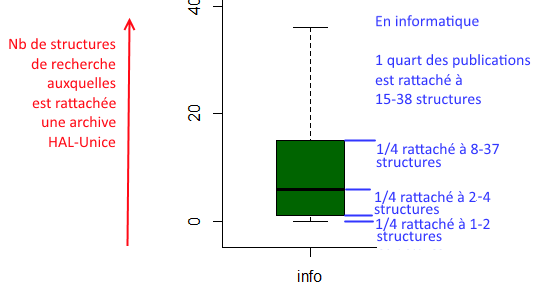
- Pour chaque discipline, on voit le nombre d’établissements auxquelles sont rattachées les archives, avec leur dispersion.
Par exemple, en physique, le nombre d’établissement par archive va de 1 à 48. La moitié des archives sont rattachés à 1-8 établissements, l’autre moitié des archives de physique sont rattachées à 8-48 établissements.
En SHS, les 3/4 des publications sont rattachés à une seule structure de recherche
On voit donc que les Sciences du Vivant (SDV), les SHS, la science non linéaire (NLIN) sont plus tassées, donc sont rattachées à un moins grand nombre de structures de recherche, que l’économie, les sciences de l’environnement (SDE) ou les sciences de l’Univers (SDU) - La largeur des colonnes rend compte du nombre d’archives recensées : il y en a beaucoup plus en informatique, en physique et en SHS qu’en économie et en statistiques
Les archives en SHS contiennent moins de liens entre structures de recherche que celles en informatique, ce qui permet d’expliquer en grande partie leur « disparition » dans le graphe globale des collaborations
Limite essentielle de l’exercice
Si la démarche est intéressante (et justifie la publication de ce billet), les observations ci-dessus sont trop tributaires de la source des informations, qui est très partielle. J’ai déjà signalé que le corpus n’était ni exhaustif ni représentatif.
Il y a un autre biais, tout aussi gênant : le champ « setSpec » où sont stockées les informations exploitées ci-dessus est uniquement la mention des tampons associés à chaque ressource. Donc si un laboratoire de recherche n’a pas choisi de demander l’activation d’un tampon pour ses publications, il n’est pas mentionné dans ces setSpec.
Peut-on exploiter une autre source d’informations pour rattacher chaque archive déposée à des structures de recherche ? 2 autres sources seraient envisageables :
- Le champ « contributeurs » mentionne souvent le nom des laboratoires
- à partir du nom du chercheur, retrouver le nom de son laboratoire grâce à l’API Affiliation des auteurs
La première piste est bloquée du fait que, contrairement au champ setSpec, l’information n’y est pas normalisée : sur 22295 « contributeurs » dans le corpus, il y a 8244 formes différentes, ce qui ne veut pas dire 8244 structures de recherche : l’INRIA de Sophia-Antipolis apparaît sous 75 formes différentes.
La seconde piste serait plus prometteuse, s’il n’y avait le problème des homonymes, et des affiliations multiples (qui sont parfois en fait la même structure bénéficiant de plusieurs « fiches » dans HAL) ou successives.
Conclusions
L’analyse des collaborations entre structures de recherche, au travers du cas du corpus de HAL-Unice, donne à voir (à visualiser) le réseau de la recherche française, à travers le prisme de leur activité dans HAL (nombre de dépôts et tampon).
On pourrait pousser cependant plus loin l’analyse, pour calculer, par exemple en fonction des disciplines, le nombre de structures de recherche (moyen, médian) auquel un laboratoire (ou l’un de ses chercheurs) de l’Université s’associe.
Une évolution sur la durée pourrait aussi se révéler intéressante, mais sur un autre corpus : celui de HAL-Unice, pour cela, est sans doute trop concentré sur le XXIe siècle.
En revanche une projection cartographique, avec des données de géolocalisation, donnerait à voir l’extension de ces collaborations, et le poids des partenariats locaux. Il faudrait pour cela lier chaque structure à ces informations.
Pour avoir une vision plus satisfaisante, il faudrait entreprendre un gros travail de reprise des données disponibles, en systématisant par exemple la constitution de « collections » (tampons) par structure de recherche.
Le travail d’analyse est aussi très tributaire des données : et telles qu’elles sont il n’est pas toujours simple de distinguer automatiquement les structures UNS des autres, de les rattacher à une ou plusieurs disciplines. On pourra donc envisager des opérations de nettoyage et d’amélioration de la base initiale, pour pouvoir ensuite l’exploiter un peu mieux.
Ces 2 billets étaient surtout l’occasion de donner à voir ce que contenait HAL-Unice, comme reflet d’une partie de la production scientifique de l’Université.
Les thèses, produites elles durant 5 décennies, en sont un autre volet au moins aussi intéressant. Il en sera donc bientôt question.
50 ans d’activité scientifique, 50 ans d’open access
111 années
par Etienne Cavalié.
dans Zoom sur...
Depuis plusieurs années (pas depuis 50 ans : les archives ouvertes n’existaient pas à l’époque), l’Université dispose d’une archive ouverte afin que ses chercheurs puissent y déposer leurs articles ou projets d’articles de manière rapide, efficace, et sans contrainte d’accès.
Actuellement, cela représente près de 13.000 archives décrites ou déposées dans HAL rattachées à une structure de l’Université. Cette masse constitue en soi une source d’information sur la production scientifique de l’établissement.
Ce n’est évidemment pas une source exhaustive sur la production scientifique de l’Université, et sa volumétrie (notamment par discipline) ne rend pas compte de l’activité de publication des chercheurs.
Néanmoins l’exploitation de ces données peut nous apprendre pas mal de choses sur l’activité à l’UNS.
A l’issue du parcours, je vous parlerai de ceci :
Mais avant ça, commençons pas des considérations plus basses, sur ce que contient ce corpus.
Répartition annuelle
Les plus anciens articles déposés datent de 1973. Ce n’est évidemment pas la date de leur dépôt, mais bien de leur rédaction
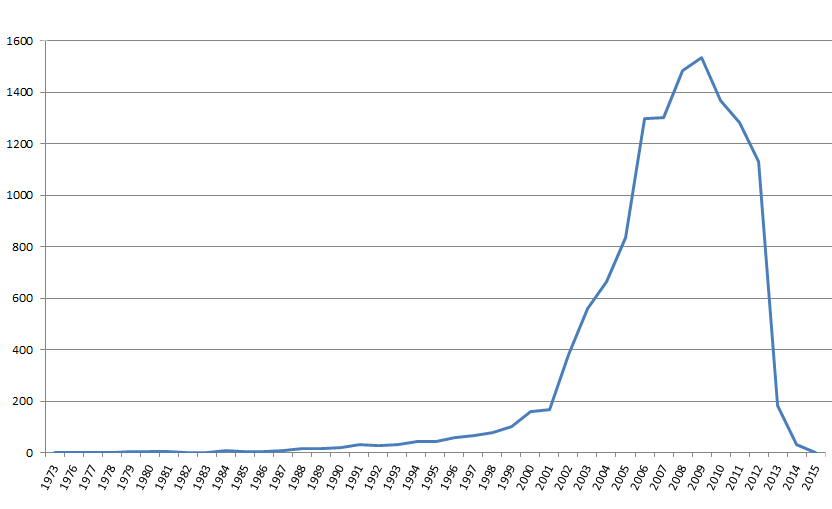
Voici la plus ancienne notice signalée dans HAL-Unice.
Texte intégral vs. notice bibliographique
Car il s’agit bien là d’une notice. Et de manière générale, il y a chaque année près de 2 fois plus de notices déposées que d’archives en texte intégral :
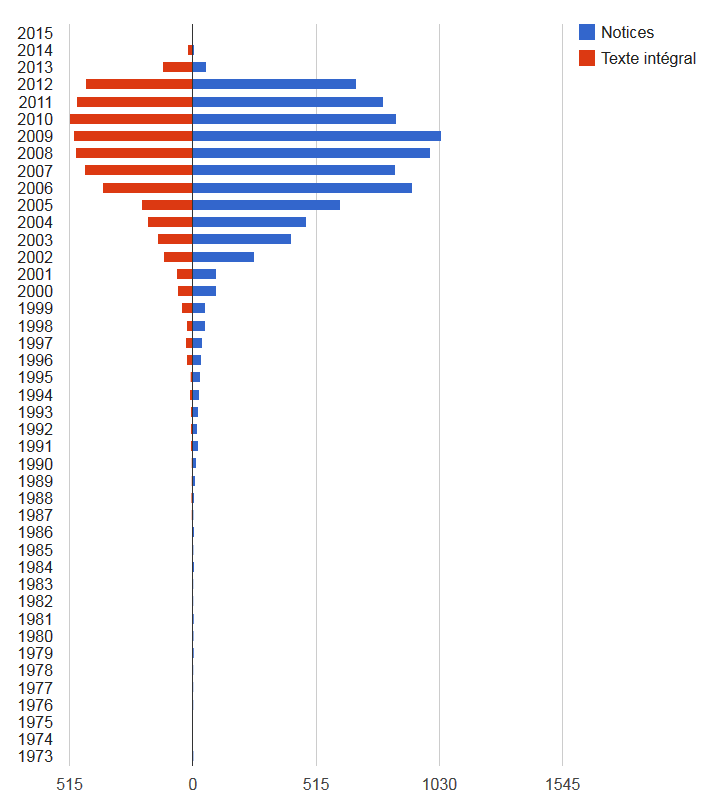
HAL-Unice sert donc aussi en grande partie, pour certains chercheurs à recenser leur production, notamment quand le dépôt ne leur semble pas possible (une hésitation sur ce qui est possible ou non ? suivez le guide).
Les disciplines représentées
Ci-dessous une représentation des disciplines, dont les chercheurs déposent de manière assez différenciée.
- La longueur des barres rend compte du nombre d’archives signalées
- La couleur rend compte de la proportion des archives disponibles en texte intégral, rapporté aux articles signalés pour la discipline
- quand c’est clair : il y a surtout des notices ;
- quand c’est foncé : surtout du texte intégral).
Le pourcentage de texte intégral est indiqué entre parenthèses.
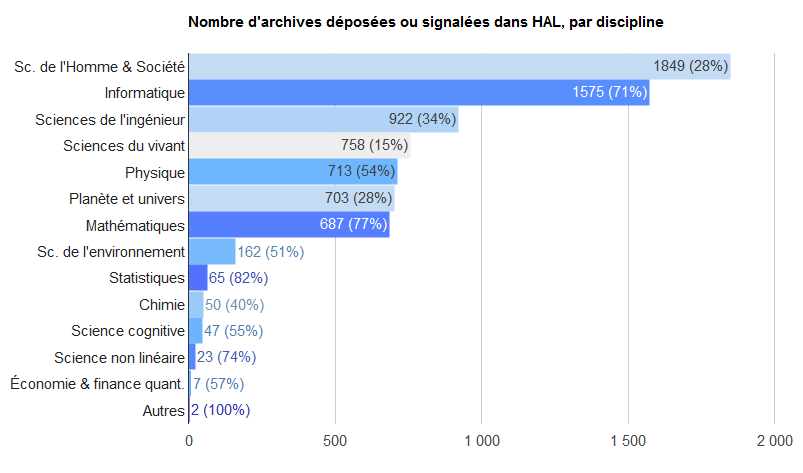
Les comportements des déposants dans HAL sont donc très diversifiés : HAL sert manifestement plus de base de signalement en SHS, où l’on sait par ailleurs que la démarche open access a une antériorité moindre que dans les sciences dures, qui ont initié ce mouvement avec ArXiv puis CiteSeer. La différence dans la proportion de texte intégral peut être liée aussi à la politique de certains laboratoires, plus incitatifs que d’autres.
Le web de données, Isidore adore !
111 années
par Géraldine Geoffroy.
dans Zoom sur...
L’API d’Isidore pour en explorer les données, c’est chouette. L’accès par un Sparql Endpoint, c’est encore mieux !
Mais avant toute chose, un petit crochet par les concepts et technologies de base du Linked Open Data s’impose (car c’est de cela qu’il s’agit).
Et commençons donc par le formalisme RDF (pour Resource Description Framework) qui ne désigne rien de moins que le modèle de description et de publication des ressources et des métadonnées sur le web. Cette modélisation s’appuie sur 3 fondamentaux :
- Des triplets : une ressource est décrite par un ensemble de triplets, chaque triplet étant constitué par une association du type <sujet><prédicat><objet>, à l’image d’une structure grammaticale sujet-verbe-complément. Par exemple <ce livre><a pour titre>< Merci pour ce moment>, <ce livre><a été écrit par><Valérie Trierweiler> etc.. sont des triplets caractérisant l’opus en question.
- Des ontologies et des thésaurus : ce sont des modélisations (elles-mêmes structurées en triplets RDF) de représentations des connaissances (par exemple le Dublin Core). Dans les triplets RDF, Les prédicats se fondent donc sur les ontologies existantes pour typer les relations sujets-objets, c’est-à dire les sémantiser.
- Des URI : des identifiants pérennes sur le web pour chaque métadonnée. Une URI peut être une URL qui donne accès au contenu de la ressource (on parle alors URI déréférencée), mais pas que…Les sujets et prédicats des triplets RDF sont toujours des URI, tandis que les objets sont soit des URI soit des littéraux. Ainsi nos triplets précédents s’expriment (dans la notice RDF du Sudoc)
<http://www.sudoc.fr/180856936/id> <dc:title> “Merci pour ce moment" <http://www.sudoc.fr/180856936/id"> <marcrel:aut> <http://www.idref.fr/115490108/id>
L’ensemble des triplets constitutifs d’une base de données RDF (Isidore, le Sudoc, l’INSEE, DBPedia…) sont stockés dans un triplestore et forment donc un graphe qu’il est possible de requêter grâce au langage Sparql (assez similaire au SQL, le langage de requête des bases de données relationnelles) via un point d’accès web, un Sparql Endpoint.
Retour donc à Isidore dans le web de données : Isidore moissonne ses diverses sources selon le protocole OAI-PMH, c’est-à dire rapatrie des sets de données en format Dublin Core, les convertit en triplets RDF, les enrichit par croisement avec des référentiels externes, puis stocke tout ça dans un triplestore accessible avec Sparql par le Sparql Endpoint Virtuoso d’Isidore.
Et illustration de l’intérêt de tout ça avec un cas pratique : comment exploiter les données d’Isidore afin d’obtenir et étudier un corpus constitué de composants Calames et de publications autour des fonds patrimoniaux que possède ma BU (par exemple Henri Bosco, Gabriel Germain, Georges Perros, Samivel… et Michel Butor tant qu’on y est) ?
Pour commencer, on formule sa requête dans le Sparql Endpoint, ici une requête de type CONSTRUCT qui permet d’obtenir un set de résultats formant lui-même un graphe « personnalisé » à partir du graphe d’Isidore, puis on choisit la sérialisation (le format de sortie, RDF/XML en l’occurence) de ce nouveau graphe :
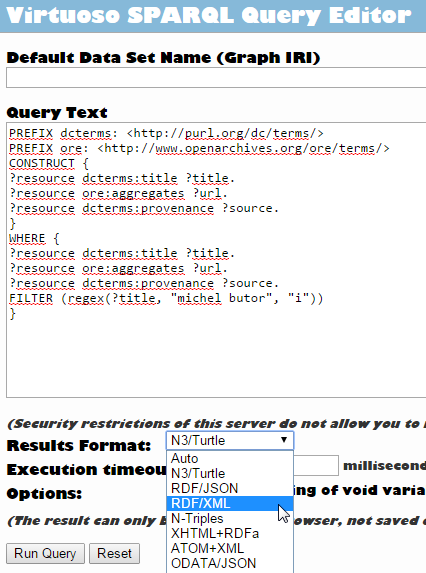
Graphe que l’on peut donc visualiser comme tel :
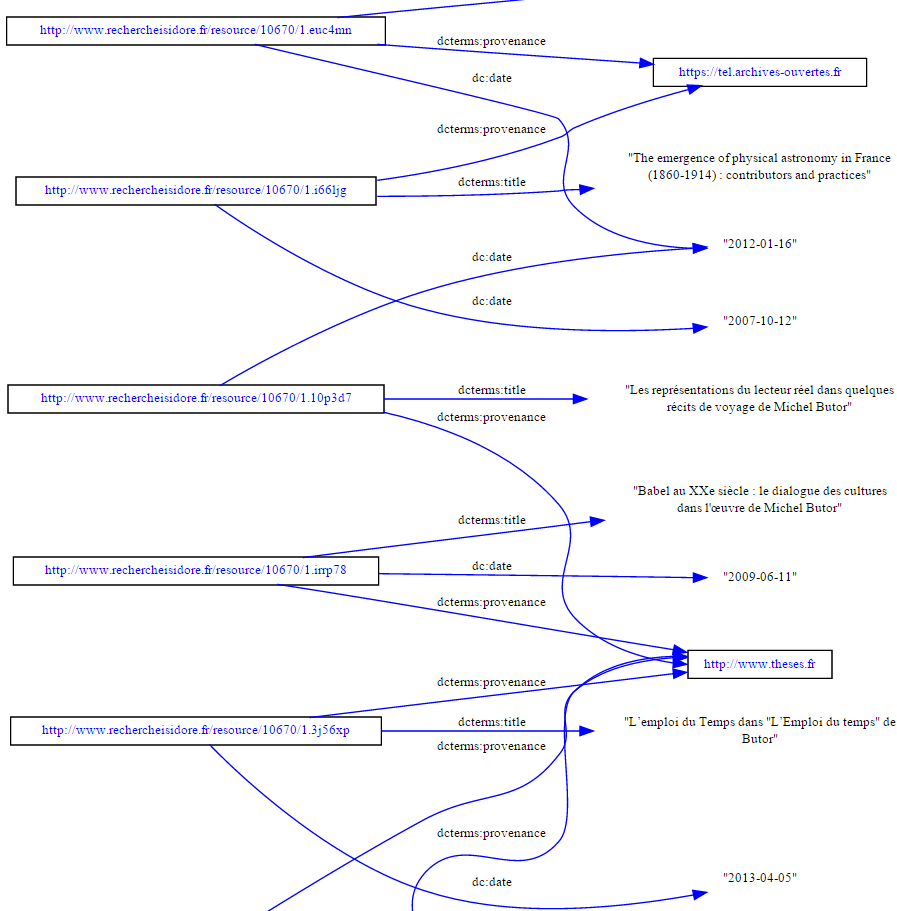
Ou plus joli, plus dynamique et en ligne :
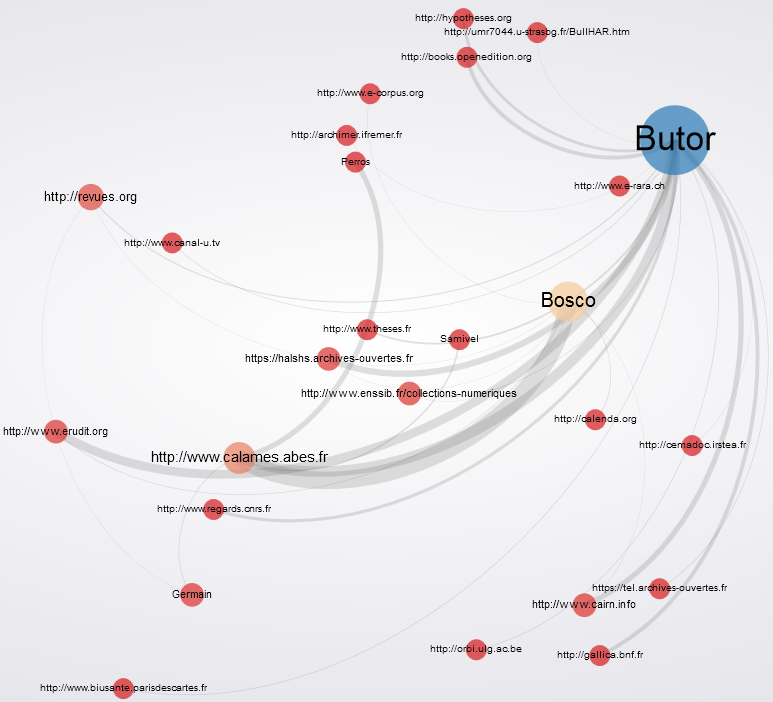
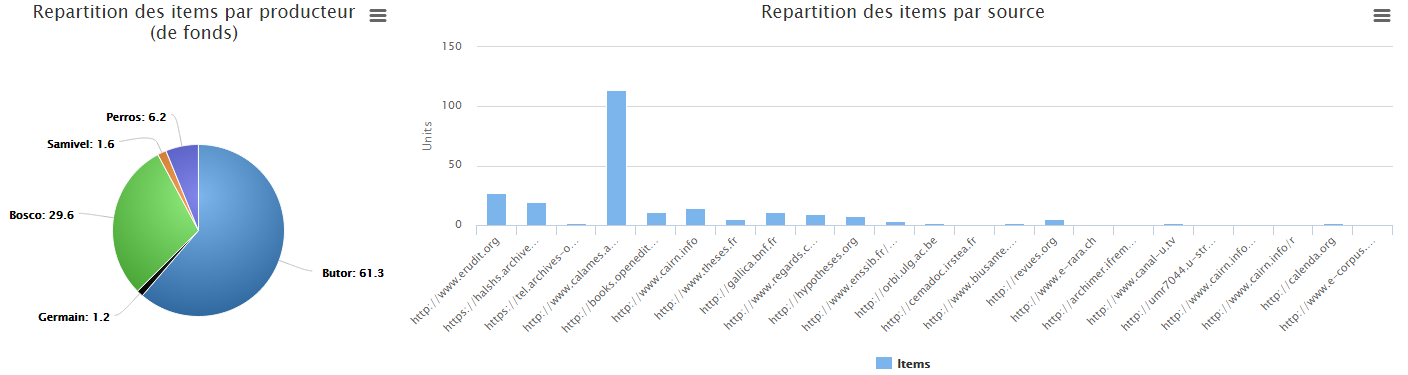
On peut aussi (essayer de) faire de jolis graphiques de visualisation statistique du corpus constitué : poids relatifs de chaque auteur dans les résultats, répartition par source de données…
Dans la même lignée, puisque Isidore enrichit ses données avec le référentiel Geonames, rien n’empêche de cartographier l’ensemble des résultats. Et puisque data.bnf propose aussi son Sparql Endpoint, pourquoi ne pas faire une réquête conjointe sur le graphe d’Isidore et celui de data.bnf afin de s’approcher d’une vue FRBRisée (hiérarchisée) des documents relatifs à ces fonds ? Par exemple pour le fonds Henri Bosco :
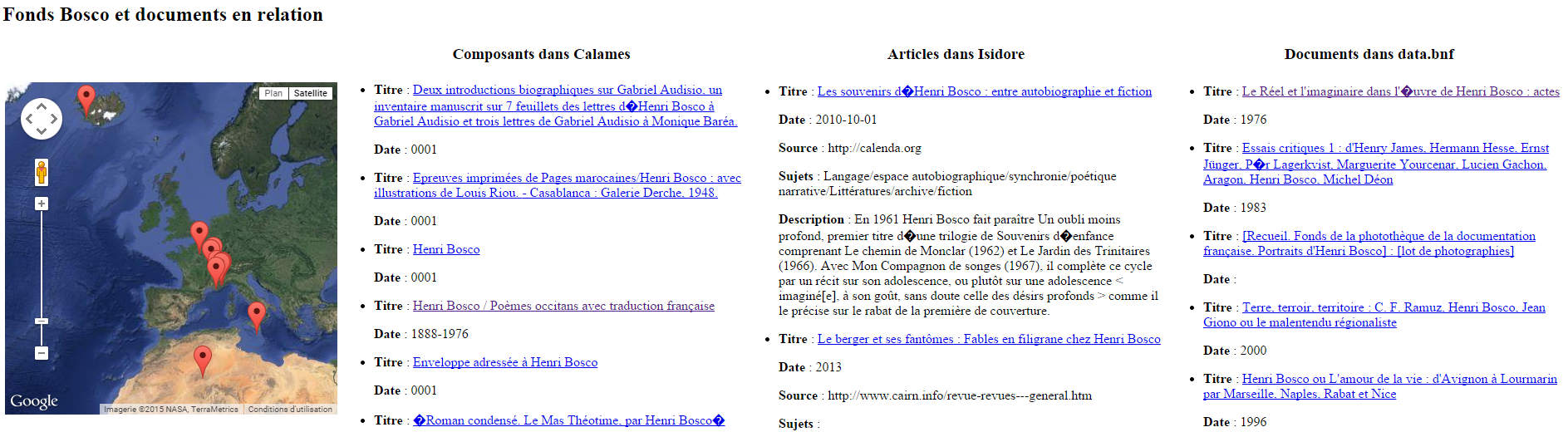
Pour visualiser la page web, c’est ici
Ainsi, les métadonnées d’Isidore formalisées en RDF, c’est la possibilité de :
- s’affranchir du niveau des notices et parcourir le graphe ouvert d’Isidore au niveau des données et non plus des notices
- exploiter l’interopérabilité de données sorties de leurs silos et structurées selon le même formalisme, indépendamment de leurs formats natifs (le web de données)
- pouvoir lier les données entre elles grâce aux URI et aux alignements des ontologies entre elles (le linked open data)
- d’exploiter sémantiquement le typage des relations entre sujets et objets, d’appliquer des algorithmes d’exploration sémantique grâce aux prédicats définis par des ontologies elles-mêmes définies sur le web (compréhensibles par des machines) pour un traitement « intelligent » des données (le web sémantique)
Au-delà des formats et des normes, il est sans doute là l’enjeu pour nos données bibliographiques comme pour les autres (données de gestion , données de la recherche…) : s’inscrire dans cette nouvelle brique de l’architecture du web où ce ne sont plus les pages html ou les documents qui sont liés mais les données et participer à la constitution d’un graphe, un jour, devenu universel.
Logiciels libres utilisés : Rhizomik RedeFer (et ses supers API), gexf-js Viewer, Highcharts
NB : pour ceux qui la chercheraient, il y encore une culotte quelque part…
Happy Isidore ! (Prononcer : A-P-I Isidore)
212 années
par Géraldine Geoffroy.
dans Zoom sur...
Ou comment extraire, exploiter, retraiter et visualiser les données d’Isidore avec un cas pratique…
Isidore : une interface unique en SHS de 3 millions de notices
Isidore est un portail d’accès unifié aux publications électroniques (principalement francophones) en sciences humaines et sociales, développé depuis 2011 dans le cadre de la Très Grande Infrastructure dédiée aux humanités numériques, le TGIR Human-num.
Isidore moissonne et agrège les données de multiples sources et bases de données telles que Revues.org, Persée, Gallica, Calames, Cairn, Dumas, Erudit…, soit en tout plus de 3 millions de documents.
Des informations enrichies
Mais plus intéressant encore, Isidore s’appuie sur les technologies de ce que l’on appelle le LOD (Linked Open Data), pour enrichir les données engrangées d’information, grâce à des sources complémentaires.
Parmi celles-ci, citons :
- le référentiel disciplinaire européen de HAL,
- la base de données géographique Geonames,
- le thésaurus PACTOLS spécialisé en archéologie et sciences de l’Antiquité,
- le répertoire d’autorités RAMEAU…
Lorsque chaque notice est récupérée par Isidore, elle est enrichie grâce à ces différentes sources. Donc, lorsqu’on fait une recherche via Isidore, les notices récupérées présentent plus d’informations que dans leur base de données source : une indexation plus riche, des données de géolocalisation, d’autres notices liées…
Des informations facilement récupérables
C’est déjà beaucoup, mais il y a encore mieux : Isidore expose ses données, il permet aux utilisateurs de les récupérer pour les ré-exploiter ensuite dans d’autres environnements.
Un des points d’accès proposé pour cela est l’API web d’Isidore : derrière ce sigle un peu mystérieux que l’on traduit en français par « interface de programmation« , on parle en fait d’un service par lequel un logiciel, un fournisseur expose tout ou partie de ses données et/ou de ses fonctionnalités.
Revenons donc à Isidore : l’API est documentée sur ce site, on peut y effectuer une recherche classique par un formulaire de recherche. La recherche fournit une liste de résultats web (format HTML normal), mais en cliquant sur « Informations techniques », on obtient un lien vers les mêmes résultats, mais en XML.
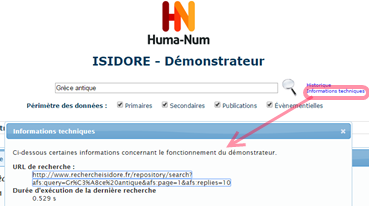
Ce format est :
- structuré (il distingue les titres, les auteurs, les dates, etc.)
- enrichi (pour un auteur donné, il renvoie vers différentes sources où cet auteur est référencé ; il rajoute diverses indexations)
- interopérable (on peut récupérer ce fichier XML pour le « manipuler » à d’autres fins)
Bon, c’est là que ça se complique un peu car ces notices en XML, on n’en fait rien en tant que telles : il faut savoir les manipuler avec des langages comme XSLT ou PHP pour les exploiter, les convertir sous d’autres formats, bref les redistribuer.
Cas pratique
Mais assez de blablas, un bon exemple valant mieux que de longs discours, Imaginons que je commence une thèse sur le concept de culotte comme indicateur sociétal en France.
Je souhaite donc commencer par faire une cartographie de l’ensemble des publications francophones sur la culotte sous ses dimensions historiques, sociales, linguistiques etc… Pour cela j’ai donc besoin de constituer un corpus de références de publications (une bibliographie du sujet) que je pourrai ensuite analyser en le soumettant à d’autres logiciels d’exploration et de visualisation.
J’interroge donc l’API d’Isidore en utilisant le mot-clé « Culotte » soit « http://www.rechercheisidore.fr/repository/search?afs:query=Culotte&afs:page=1&afs:replies=100 » (les derniers paramètres indiquant que j’affiche d’abord la page 1 de la liste de résultats et que je souhaite afficher 100 résultats par page). En interrogeant l’API de manière récursive sur toutes les pages de résultats, j’obtiens en réponse 836 notices, que je peux donc manipuler (si je parle le XSLT, ou si je demande à ma BU qui le connaît), transformer en XML, CSV, JSON, ou tout autre format et ensuite analyser comme je le souhaite.
Ainsi, en passant par l’API Isidore (plutôt que la recherche standard), je peux pour chaque notice obtenir le lieu de publication de la ressource décrite, et sa discipline. Je peux ainsi confronter répartition géographique et disciplinaire des publications moissonnées :
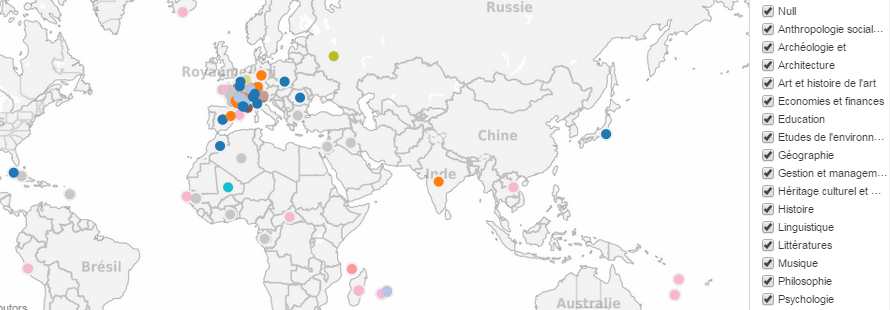
Publications scientifiques sur la « culotte » : répartition géographique et disciplinaire – visualisation obtenue avec le logiciel Tableau Public
Ou encore visualiser sous forme de graphe les relations de proximité entre concepts :
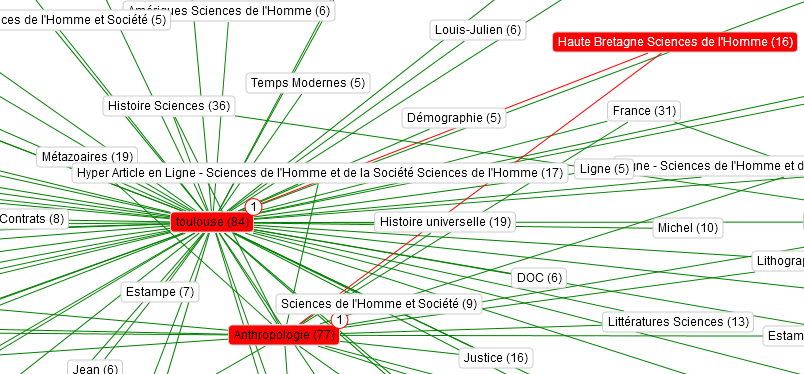
Concepts associés à chaque notice et liens entre eux – visualisation obtenue avec le logiciel Voyant Tool
Ou encore extraire les résumés dans l’ordre chronologique et en étudier les fréquences d’apparition de certains mots :
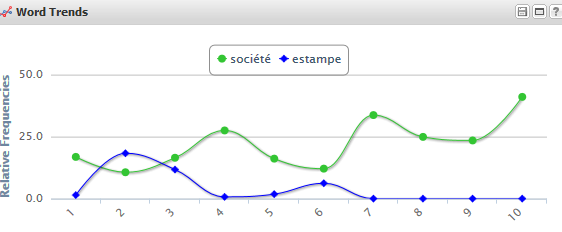 Fréquence de certains mots-clés dans les 836 ressources traitant de la culotte – visualisation obtenue avec Voyant Tool
Fréquence de certains mots-clés dans les 836 ressources traitant de la culotte – visualisation obtenue avec Voyant Tool
Ou encore etc…
A partir du même exemple, vous pouvez visualiser sur cette page web d’autres types d’exploitation de données récupérées grâce à l’API d’Isidore, véritable sésame pour l’exploration de corpus bibliographiques en SHS.
Logiciels libres utilisés : Tableau Public, Voyant Tools, Simile Exhibit.
NB : les données aspirées par l’API l’ont été uniquement pour l’exemple, elles n’ont pas été nettoyées de toutes leurs « scories » éventuelles, ce qui explique un affichage pas toujours très « propre ».
A suivre
Dans un prochain billet : le Sparql Endpoint d’Isidore, un autre point d’accès pour explorer sémantiquement les données d’Isidore structurées en RDF.
DfR : l’autre interface Jstor
012 années
par Cécile Pierre.
dans Zoom sur...
A côté de son interface standard, Jstor offre aux chercheurs l’interface Data for Research. Encore en version beta, cette interface propose des fonctionnalités d’exploitation avancées de la base Jstor.
Intérêts de cette interface :
- Décharger en une fois un nombre important de données (limité à 1000 maximum) sans avoir à les sélectionner page par page. Il s’agit cependant uniquement des références bibliographiques et résumés (pas de texte intégral)
- Visualiser graphiquement la répartition chronologique d’un corpus (date) et les mots-clés (nuage de mots)
- Bénéficier de fonctionnalités d’analyse linguistique sur les documents (extraction automatique de mots-clés, fréquence de mots isolés, digrammes, trigrammes…)
Quelques exemples d’exploitation : travailler sur l’évolution d’une discipline, sur l’usage d’un concept dans une discipline, récupérer l’ensemble des articles parus dans une revue, en afficher la distribution chronologique et thématique…
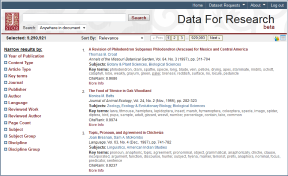
Fonctionnement de la recherche
La sélection se fait par restrictions successives. Par défaut l’ensemble des documents Jstor est sélectionné, et l’on peut ensuite rechercher des termes et/ou restreindre par les facettes proposées en colonne de gauche.
– Recherche : l’interface propose un champ de recherche unique, avec éventuellement une limitation sur les champs à interroger (titre, auteur, résumé, légende, mot-clé, citations).
Il est possible d’affiner sa recherche en construisant des équations, à l’aide d’opérateurs booléens et des codes de champs, visibles dans les URL, par exemple :
Recherche d’articles ayant le mot « Afrique » dans titre ou résumé : ((ta:afrique) OR (ab:afrique))
Récupération des articles de la revue Etudes rurales en se limitant au type « article » : (jcode:etudesrurales) AND (ty:fla)
– Facettes :
La facette Date affiche un graphique de distribution chronologique. La facette Key terms présente un nuage de mots. Les listes ou graphiques pour chaque facette sont exportables
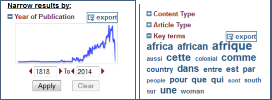
Comment récupérer le corpus de données ?
Il faut créer un compte et s’identifier (Log in/register).
Le corpus doit être inférieur à 1000 documents, sinon une sélection aléatoire sera faite lors de l’export. Il est possible de contacter Jstor pour lever cette limite. Il faut alors expliciter en détail son projet, comme le demandent aussi d’autres éditeurs pour la fouille de données. Toutefois, cette exigence peut sembler problématique (voir la question des données du data mining dans ce billet de Sciences Communes…).
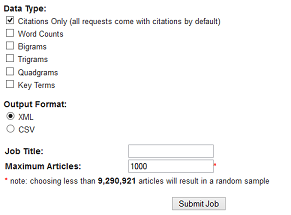
Une fois sa sélection faite, cliquer sur Datasets request, puis Submit new request.
Une fenêtre s’ouvre et vous indique le statut du traitement. Lorsque le résultat est prêt, un mail est envoyé à l’adresse de messagerie paramétrée. Aller sur « List prior requests » pour récupérer les résultats au format zip (full dataset) et un rappel des critères de recherche (summary file)
![]()
En cas de problème, l’assistance mail Jstor s’avère très réactive et efficace.
L’exploitation des résultats
L’ensemble des références bibliographiques est récupéré dans un fichier unique.
On peut par exemple importer ces données dans Excel (fonctionne bien pour l’export csv en choisissant le codage UTF8)
Pour les analyses linguistiques, on obtient un fichier par référence ; le liens avec les références se fait par l’identifiant du document.
On peut ensuite utiliser un outil d’analyse de texte (exemples trouvés – non testés – : JstorR, Paper Machines, Mallet…)
Pour les usages autorisés et la ré-exposition des données, voir les Terms and conditions (en particulier, l’incorporation dans des bases de données accessibles doit se faire avec l’accord de l’éditeur)
Quelques limites de DfR
- Contenu de la base JSTOR. Une grande partie des revues sont accessibles uniquement jusqu’à une certaine date ou après une période d’embargo de plusieurs années. Jstor est donc plus adapté à des recherches portant sur une vaste période chronologique ou l’antériorité, et pas sur les années récentes
- Complétude des données : les résumés par exemple ne sont pas nécessairement présents, surtout avant les années 70. La restriction d’une recherche sur ce critère présente donc un biais.
- La sélection « en entonnoir » est parfois frustrante ; si l’on n’utilise pas d’équation de recherche avancée, impossible par exemple de sélectionner plus d’une revue ou d’une discipline à la fois dans les facettes
- La restriction à 1000 documents s‘avère à l’usage assez contraignante
- Les mots clés ne sont pas toujours très pertinents dans les langues autres que l’anglais
- La recherche porte sur le texte intégral du document, ce qui génère parfois du bruit dans les recherches.
Malgré tout cet outil simple à prendre en main me semble ouvrir de nombreuses possibilités.
Joyeux anniversaire Revel, épisode 3 : le compte est bon !
012 années
par Magalie Prudon.
dans Zoom sur...
Revel est la plateforme de diffusion de revues électroniques en sciences humaines et sociales de l’université Nice Sophia Antipolis. Et elle fête cette année son dixième anniversaire !
On vous a parlé dans les billets précédents, ici et là, de l’aventure humaine qu’est Revel, et de l’implication des équipes de chercheurs et des documentalistes-bibliothécaires dans ce projet. Le résultat de cette aventure c’est la diffusion en ligne des revues et colloques en sciences humaines et sociales (SHS pour les intimes) de l’université Nice Sophia Antipolis, ce qui en chiffres donne la combinaison gagnante 15, 7, 8, 1, 2, 269, 3252, 40 000 :

15 revues en libre accès (parfois avec délai pour la mise en libre accès) :
- 7 sur Revel, plateforme pépinière pour les jeunes revues en SHS de l’UNS
- 8 sur Revues.org, site de diffusion en ligne de revues en SHS de la plateforme nationale OpenEdition
Dont 1 accessible par abonnement sur Cairn, plateforme commerciale de diffusion en ligne de revues en SHS sur abonnement
Et 2 autres qui proposent (ou proposeront bientôt) leurs anciens numéros sur Persée, plateforme nationale de diffusion en ligne des anciens numéros de revues en SHS
Et pour ces 15 revues réunies, c’est aujourd’hui :
- 269 numéros de revues
- 3252 articles
- et plus de 40 000 consultations par mois en moyenne
sans oublier la partie réservée aux colloques de l’UNS, qui héberge pour l’instant 8 espaces de colloques certains pour une unique manifestation, d’autre pour des collections d’actes de colloques.
N’hésitez pas à contacter l’équipe du pôle Publication des BU pour toute question relevant de la publications de revues scientifiques ou de colloques à l’UNS à revel@unice.fr.
Les revues Revel en SHS de l’UNS
| Rursus sur Revues.org | Poiétique, réception et réécriture des textes antiques |
| Cycnos sur Revel | Etudes anglophones |
| Socio-Anthropologie sur Revues.org puis Mondes contemporains bientôt sur Revues.org |
Sciences sociales |
| Cahiers de l’Urmis sur Revues.org | Sciences sociales |
| Cahiers de Narratologie sur Revues.org | Analyse et théorie narratives |
| Cahiers de la Méditerranée sur Revues.org bientôt sur Persée |
Histoire et sciences sociales |
| Revue française de musicothérapie sur Revel | Musicothérapie |
| Oxymoron sur Revel | Psychanalytise et interdiscipline |
| Noesis sur Revues.org | Philosophie |
| Loxias sur Revel | Littératures française et comparée |
| Corpus sur Revues.org | Linguistique |
| ERIEP sur Revel | Economie industrielle |
| Revue d’économie industrielle sur Revues.org sur Cairn sur Persée |
Economie industrielle |
| Alliage sur Revel | Culture, sciences, techniques |
| Perspectives internationales et européennes (arrêtée) sur Revel | Droit international |
