HTTBU
Le blog des BU sur les publications électroniques et les données de la recherche
ISTEX (dont il a déjà été question ici) est un projet, un dispositif, un ensemble de ressources et de services. C’est également une plate-forme.

La Bibliothèque scientifique numérique est un dispositif visant à faire collaborer les grands acteurs du monde académique autour des enjeux forts de la documentation scientifique aujourd’hui. 9, puis 10 « segments » (groupes de travail) œuvrent à apporter des réponses nationales à des problématiques communes.
ISTEX est le produit d’un de ces segments : cette plate-forme vise à donner accès de manière pérenne aux ressources (articles) acquises dans le cadre de licences nationales.
Par voie de conséquence, ISTEX engrange donc une masse de documentation scientifique qu’il peut être intéressant de considérer comme un corpus de textes.
Dans cette perspective, un appel à propositions est lancé par ISTEX pour initier des chantiers thématiques d’exploitation du plein texte des corpus, considérés comme données source pour la fouille de texte.
8 à 10 projets dans des thématiques différentes devraient être soutenus financièrement, avec une enveloppe globale de 400 k€ pour l’ensemble des projets.
La date limite de soumission est le 15 octobre minuit, pour un début de mise en place en janvier 2016, et un rendu des résultats au second trimestre 2017.
Ces projets devront être accompagnés en termes d’expertise et de conseil par des spécialistes de l’IST. L’appel à proposition précise qu’une interaction avec l’équipe de développement de la plateforme Istex et/ou les projets de services généraux à valeur ajoutée en cours de définition serait un plus (voir les pages présentant « les services de base » et « les services avancés« ).
Le Service commun de documentation se met à la disposition des laboratoires et des chercheurs pour les accompagner dans la définition et la réalisation de ces projets (informations sur les corpus concernés, informations sur la plateforme et les projets de services généraux d’Istex, fourniture de prestations de manipulation et de visualisation de données).
Si cet appel à proposition vous intéresse, vous pouvez contacter donnees-scd@unice.fr à partir du 1er septembre.

![]() Sur commande du gouvernement visant à produire une stratégie globale concernant le numérique et internet, le Conseil National du Numérique (@CNNum, et non pas CNN), organisme indépendant, a lancé dans les derniers mois une large consultation, auprès d’acteurs du numérique, mais également sous forme d’ateliers divers, visant à recenser, arbitrer et synthétiser des propositions pour une politique démocratique du numérique.
Sur commande du gouvernement visant à produire une stratégie globale concernant le numérique et internet, le Conseil National du Numérique (@CNNum, et non pas CNN), organisme indépendant, a lancé dans les derniers mois une large consultation, auprès d’acteurs du numérique, mais également sous forme d’ateliers divers, visant à recenser, arbitrer et synthétiser des propositions pour une politique démocratique du numérique.
Le rapport Ambition numérique de 399 pages (plus court qu’un gros polar, donc), est téléchargeable en PDF, en ODT (format LibreOffice), et permet d’avoir une approche politique et stratégique (et non technique), de questions sociétales, économiques, concernant l’avenir d’internet tel qu’il se dessine (ou pas).

L’été vient à point pour s’y intéresser, et comprendre les enjeux qui vont bien au-delà des conditions de consultation de notre mail ou de notre compte Facebook mais de pans entiers de nos vies comme la santé ou la recherche d’emploi.
Votre été est déjà bien chargé ? Vous savez que vous n’aurez pas le temps de lire les 70 propositions ?
D’abord, vous pouvez n’en lire que quelques-unes, prendre le temps de vous rappeler pourquoi la neutralité du net, c’est important, ou ce que sont les communs.
Ensuite, vous pouvez en faire un survol en 5 minutes (vidéo).
Il n’est pas impossible que ces 5 minutes vous incitent, finalement, à trouver le temps pour lire le rapport complet. Les enjeux qu’il contient le mérite.
Le numérique nous concerne tous par cnnumeriquefr
Si la lecture complète du rapport vous semble encore un peu trop ambitieuse, attardez-vous sur les vidéos présentant chacune des quatre parties :
Concernant plus spécifiquement le monde de l’enseignement supérieur et de la recherche : le volet 2 aborde la question de l’ouverture des données ; le volet 3 une politique de l’innovation et un rapprochement entre monde académique et entreprises ; le volet 4 enfin (qui traite de pédagogie et de formation) aborde la question de l’exception des usages pédagogiques pour les ressources numériques, ainsi que des conditions de certification. Dans ce dernier volet, la proposition 53 s’intitule : « Faire de la publication ouverte une obligation légale pour la recherche bénéficiant de fonds publics ». Une occasion aussi de se replonger dans les enjeux de l’open access.
Découvrez jusqu’à la fin mai, la collection Social Science Journals d’Oxford University Press.
![]()
61 titres en économie et science politique sont en test pour l’Université Nice Sophia Antipolis (voir le détail des titres).
Cette collection vous intéresse ? Faites nous le savoir en remplissant ce court questionnaire
![]()
J’ai décrit dans un précédent billet le contenu de HAL-Unice, en terme de volumétrie.
Rappelons que les constatations sont faites pour le corpus constaté, c’est-à-dire les archives déposées dans HAL, et les articles signalés par les chercheurs dans HAL. Ce corpus ne prend donc en compte
Par ailleurs les disciplines sont inégalement représentées du fait aussi des pratiques de publication des chercheurs, directement liées aux conditions d’évaluation (ex : publier un ouvrage compte-t-il ou non ?) et aux pratiques des communautés scientifiques et des maisons d’édition.
Pour les archives qui y sont déposées ou signalées, HAL-Unice constitue-t-il un bon corpus pour donner à voir toutes les collaborations entre laboratoires et structures de recherche ? On peut toujours essayer.
A chaque notice est associée l’affiliation du ou des auteurs. Cette affiliation est presque toujours exprimée de manière double, quand elle désigne le nom du labo et l’université de rattachement de celui-ci ; ou triple quand il s’agit d’une UMR, rattachée à la fois au CNRS et à l’Université.
En moyenne, une ressource est affiliée à 6 structures de recherche, avec un maximum de 56 pour l’ensemble étudié…
On peut donc considérer que chaque article est le fruit d’une collaboration entre les structures de recherche auxquelles appartiennent leurs auteurs. Chaque article donne à voir une collaboration entre deux structures de recherche.
De manière plus globale (c’est-à-dire en regardant les liens entre les structures de recherche, non pas notice par notice mais pour l’ensemble du corpus), on découvre tout un réseau continu entre les établissements.

Les données qui ont permis de générer ce graphe :
A chaque article est associé un ou plusieurs « sets ». Quand il y a plusieurs affiliations d’établissements, cela apparaît sous la forme :
<collection>UNICE</collection> <collection>SHS</collection> <collection>EPHE</collection> <collection>INRAP</collection> <collection>CNRS</collection> <collection>UNIV-TLSE2</collection> <collection>CEPAM</collection> <collection>TRACES</collection> <collection>CBAE</collection> <collection>UNIV-MONTP3</collection> <collection>UMR5140</collection> <collection>UNIV-AMU</collection> <collection>MMSH</collection> <collection>LADIR</collection> <collection>UPMC</collection>
On a considéré qu’à travers cette liste, chaque structure de recherche était liée à chacune des autres, ce qui a généré toutes les paires possibles :
UNICE;SHS / UNICE;EPHE / UNICE;INRAP / UNICE;CNRS / UNICE;UNIV-TLSE2 / UNICE;CEPAM / UNICE;TRACES / UNICE;CBAE / UNICE;UNIV-MONTP3 / UNICE;UMR5140 / UNICE;UNIV-AMU / UNICE;MMSH / UNICE;LADIR / UNICE;UPMC / SHS;EPHE / SHS;INRAP / SHS;CNRS / SHS;UNIV-TLSE2 / SHS;CEPAM / SHS;TRACES / SHS;CBAE / SHS;UNIV-MONTP3 / SHS;UMR5140 / SHS;UNIV-AMU / SHS;MMSH / SHS;LADIR / SHS;UPMC / EPHE;INRAP / EPHE;CNRS / EPHE;UNIV-TLSE2 / EPHE;CEPAM / EPHE;TRACES / EPHE;CBAE / EPHE;UNIV-MONTP3 / EPHE;UMR5140 / EPHE;UNIV-AMU / EPHE;MMSH / EPHE;LADIR / EPHE;UPMC / INRAP;CNRS / INRAP;UNIV-TLSE2 / INRAP;CEPAM / INRAP;TRACES / INRAP;CBAE / INRAP;UNIV-MONTP3 / INRAP;UMR5140 / INRAP;UNIV-AMU / INRAP;MMSH / INRAP;LADIR / INRAP;UPMC / CNRS;UNIV-TLSE2 / CNRS;CEPAM / CNRS;TRACES / CNRS;CBAE / CNRS;UNIV-MONTP3 / CNRS;UMR5140 / CNRS;UNIV-AMU / CNRS;MMSH / CNRS;LADIR / CNRS;UPMC / UNIV-TLSE2;CEPAM / UNIV-TLSE2;TRACES / UNIV-TLSE2;CBAE / UNIV-TLSE2;UNIV-MONTP3 / UNIV-TLSE2;UMR5140 / UNIV-TLSE2;UNIV-AMU / UNIV-TLSE2;MMSH / UNIV-TLSE2;LADIR / UNIV-TLSE2;UPMC / CEPAM;TRACES / CEPAM;CBAE / CEPAM;UNIV-MONTP3 / CEPAM;UMR5140 / CEPAM;UNIV-AMU / CEPAM;MMSH / CEPAM;LADIR / CEPAM;UPMC / TRACES;CBAE / TRACES;UNIV-MONTP3 / TRACES;UMR5140 / TRACES;UNIV-AMU / TRACES;MMSH / TRACES;LADIR / TRACES;UPMC / CBAE;UNIV-MONTP3 / CBAE;UMR5140 / CBAE;UNIV-AMU / CBAE;MMSH / CBAE;LADIR / CBAE;UPMC / UNIV-MONTP3;UMR5140 / UNIV-MONTP3;UNIV-AMU / UNIV-MONTP3;MMSH / UNIV-MONTP3;LADIR / UNIV-MONTP3;UPMC / UMR5140;UNIV-AMU / UMR5140;MMSH / UMR5140;LADIR / UMR5140;UPMC / UNIV-AMU;MMSH / UNIV-AMU;LADIR / UNIV-AMU;UPMC / MMSH;LADIR / MMSH;UPMC / LADIR;UPMC
L’ensemble de ces paires a ensuite été chargée dans Gephi, pour obtenir une clusterisation et une répartition spatiale qui a rapproché les établissements travaillant le plus souvent ensemble, et attribuant (ou tentant d’attribuer) des couleurs par sous-groupes.
Le corpus considéré de manière « brute » (sans sélection des données traitées) laisse entendre qu’il n’y a pas vraiment de sous-ensembles nets : aucun groupe de noeuds ne se détache vraiment des autres, il y a plutôt, dans l’activité de publication, un continuum de la recherche.
On peut voir d’emblée au moins 3 limites aux données en entrée :
Voici donc 2 autres tentatives pour voir si une visualisation différente pourrait se dégager :
Dans le graphe ci-dessous, les universités et le CNRS ont été retirées. Ne sont conservées que les structures de recherche de type Laboratoire ou Institut.
On passe ainsi à 1063 établissements (nœuds) et 18.000 liens :

Certains sous-ensembles se dégagent mieux (le graphe est moins uniforme) : SophiaTech et l’INRIA avec le labo de math J.A. Dieudonné ; les laboratoires de l’OCA (en vert) – et juste à côté, dans un vert légèrement différent, des structures de recherche en SHS (la plus visible sur le graphe étant le CEPAM).
Pourtant de nombreux liens existent manifestement entre ces groupes, et on continue d’observer le continuum évoqué plus haut.
Une méthode supplémentaire pour « nettoyer » les données consiste à évacuer toutes les collaborations trop ponctuelles (1 à 5 occurrences), pour ne conserver que celles qui se sont répétées pour la rédaction de plusieurs archives déposées.
Ci-dessous le graphe exploitant les collaborations répétées au moins 6 fois dans le corpus étudié (404 structures de recherche, 2830 liens) :

Le risque est évidemment de faire disparaître des laboratoires très présents dans le corpus initial, mais qui travaillent ponctuellement avec un grand nombre d’autre laboratoires très diversifiés : chaque lien concernant ce labo apparaissant peu de fois, il finit par disparaître complètement du graphe…
661 structures sont évacuées suite à ce filtre supplémentaire, mais aucune ne relève de l’Université Nice Sophia Antipolis (qui est le sujet de ce billet).
Ultime remarque : les SHS semble avoir disparu dans la masse. Du coup, voici un graphe rien que pour eux.

Celui-ci est dynamique et permet notamment de filtrer sur le nom d’un labo (via le petit moteur de recherche dans l’en-tête), pour voir identifier ses partenaires et sa position dans le réseau.
Pourquoi dans le graphe global ne voit-on presque plus que des structures de recherche en sciences ? Parce que dans les archives déposées ou signalées dans HAL-Unice, les SHS indiquent beaucoup moins d’affiliations : les collaborations entre labos sont en moins grand nombre :
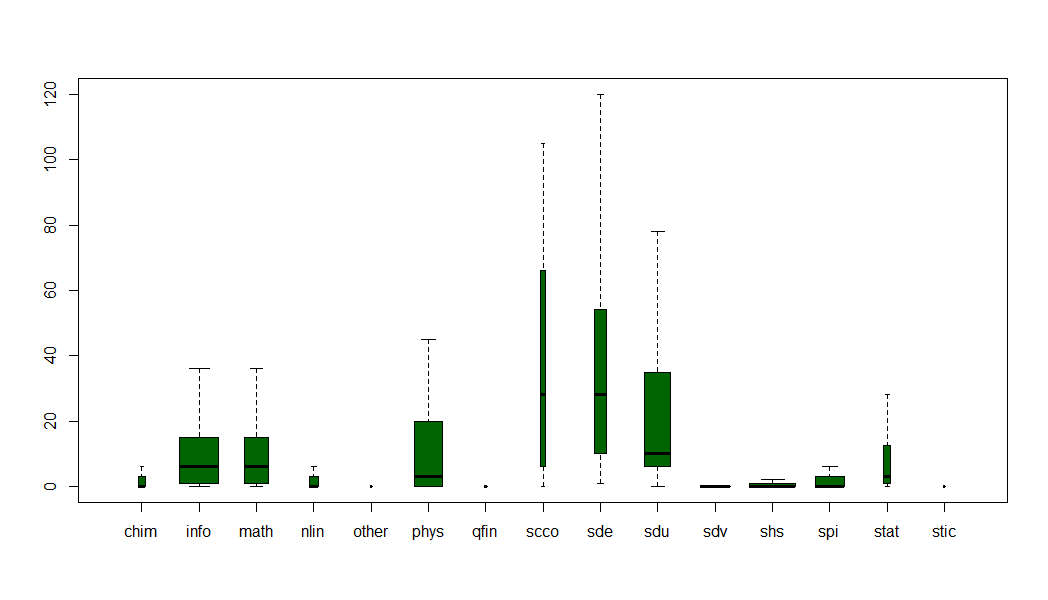
Comment lire ce graphique ?
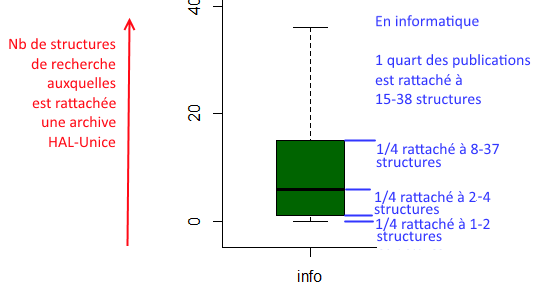
Les archives en SHS contiennent moins de liens entre structures de recherche que celles en informatique, ce qui permet d’expliquer en grande partie leur « disparition » dans le graphe globale des collaborations
Si la démarche est intéressante (et justifie la publication de ce billet), les observations ci-dessus sont trop tributaires de la source des informations, qui est très partielle. J’ai déjà signalé que le corpus n’était ni exhaustif ni représentatif.
Il y a un autre biais, tout aussi gênant : le champ « setSpec » où sont stockées les informations exploitées ci-dessus est uniquement la mention des tampons associés à chaque ressource. Donc si un laboratoire de recherche n’a pas choisi de demander l’activation d’un tampon pour ses publications, il n’est pas mentionné dans ces setSpec.
Peut-on exploiter une autre source d’informations pour rattacher chaque archive déposée à des structures de recherche ? 2 autres sources seraient envisageables :
La première piste est bloquée du fait que, contrairement au champ setSpec, l’information n’y est pas normalisée : sur 22295 « contributeurs » dans le corpus, il y a 8244 formes différentes, ce qui ne veut pas dire 8244 structures de recherche : l’INRIA de Sophia-Antipolis apparaît sous 75 formes différentes.
La seconde piste serait plus prometteuse, s’il n’y avait le problème des homonymes, et des affiliations multiples (qui sont parfois en fait la même structure bénéficiant de plusieurs « fiches » dans HAL) ou successives.
L’analyse des collaborations entre structures de recherche, au travers du cas du corpus de HAL-Unice, donne à voir (à visualiser) le réseau de la recherche française, à travers le prisme de leur activité dans HAL (nombre de dépôts et tampon).
On pourrait pousser cependant plus loin l’analyse, pour calculer, par exemple en fonction des disciplines, le nombre de structures de recherche (moyen, médian) auquel un laboratoire (ou l’un de ses chercheurs) de l’Université s’associe.
Une évolution sur la durée pourrait aussi se révéler intéressante, mais sur un autre corpus : celui de HAL-Unice, pour cela, est sans doute trop concentré sur le XXIe siècle.
En revanche une projection cartographique, avec des données de géolocalisation, donnerait à voir l’extension de ces collaborations, et le poids des partenariats locaux. Il faudrait pour cela lier chaque structure à ces informations.
Pour avoir une vision plus satisfaisante, il faudrait entreprendre un gros travail de reprise des données disponibles, en systématisant par exemple la constitution de « collections » (tampons) par structure de recherche.
Le travail d’analyse est aussi très tributaire des données : et telles qu’elles sont il n’est pas toujours simple de distinguer automatiquement les structures UNS des autres, de les rattacher à une ou plusieurs disciplines. On pourra donc envisager des opérations de nettoyage et d’amélioration de la base initiale, pour pouvoir ensuite l’exploiter un peu mieux.
Ces 2 billets étaient surtout l’occasion de donner à voir ce que contenait HAL-Unice, comme reflet d’une partie de la production scientifique de l’Université.
Les thèses, produites elles durant 5 décennies, en sont un autre volet au moins aussi intéressant. Il en sera donc bientôt question.
Depuis plusieurs années (pas depuis 50 ans : les archives ouvertes n’existaient pas à l’époque), l’Université dispose d’une archive ouverte afin que ses chercheurs puissent y déposer leurs articles ou projets d’articles de manière rapide, efficace, et sans contrainte d’accès.
Actuellement, cela représente près de 13.000 archives décrites ou déposées dans HAL rattachées à une structure de l’Université. Cette masse constitue en soi une source d’information sur la production scientifique de l’établissement.
Ce n’est évidemment pas une source exhaustive sur la production scientifique de l’Université, et sa volumétrie (notamment par discipline) ne rend pas compte de l’activité de publication des chercheurs.
Néanmoins l’exploitation de ces données peut nous apprendre pas mal de choses sur l’activité à l’UNS.
A l’issue du parcours, je vous parlerai de ceci :
Mais avant ça, commençons pas des considérations plus basses, sur ce que contient ce corpus.
Les plus anciens articles déposés datent de 1973. Ce n’est évidemment pas la date de leur dépôt, mais bien de leur rédaction
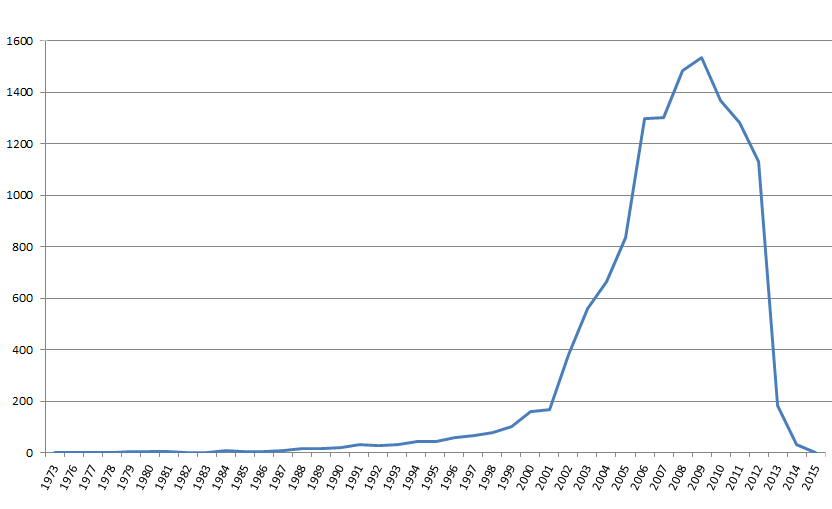
Voici la plus ancienne notice signalée dans HAL-Unice.
Car il s’agit bien là d’une notice. Et de manière générale, il y a chaque année près de 2 fois plus de notices déposées que d’archives en texte intégral :
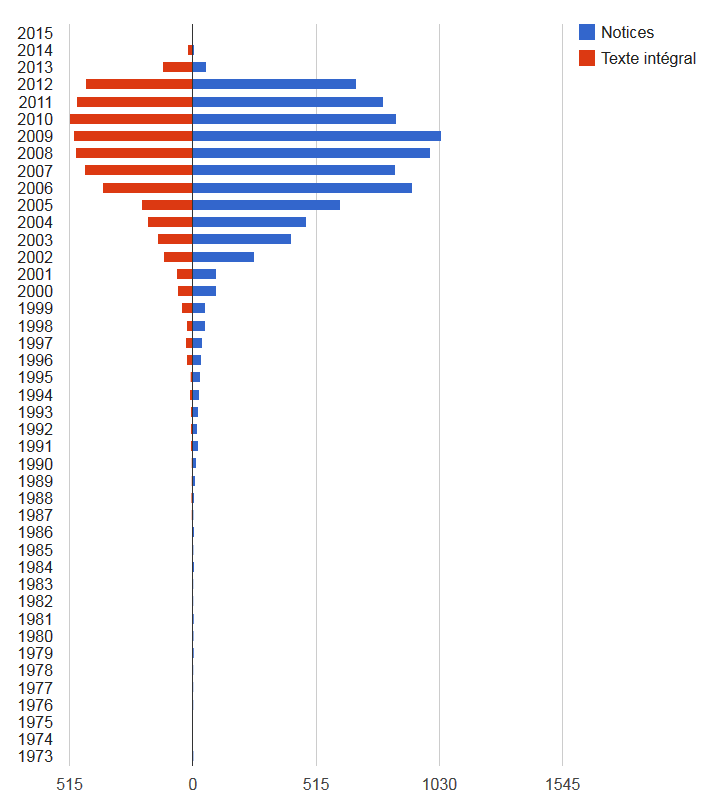
HAL-Unice sert donc aussi en grande partie, pour certains chercheurs à recenser leur production, notamment quand le dépôt ne leur semble pas possible (une hésitation sur ce qui est possible ou non ? suivez le guide).
Ci-dessous une représentation des disciplines, dont les chercheurs déposent de manière assez différenciée.
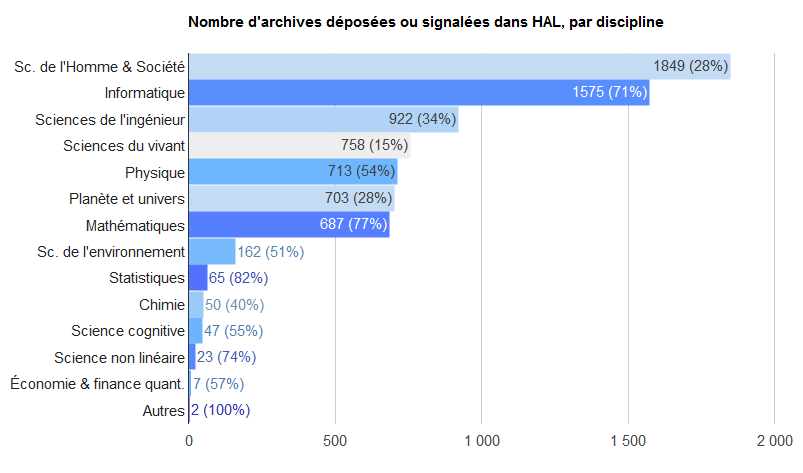
Les comportements des déposants dans HAL sont donc très diversifiés : HAL sert manifestement plus de base de signalement en SHS, où l’on sait par ailleurs que la démarche open access a une antériorité moindre que dans les sciences dures, qui ont initié ce mouvement avec ArXiv puis CiteSeer. La différence dans la proportion de texte intégral peut être liée aussi à la politique de certains laboratoires, plus incitatifs que d’autres.

Découvrez plusieurs produits électroniques édités par Masson :
– La plateforme E-ECN (l’interface demande de créer un compte à partir d’un poste connecté sur le réseau de l’université)
– Plusieurs collections d’ebooks sur l’interface E-Library (collection Gold-ECN, Gray’s Anatomie et les mémofiches anatomie Netter)
– Revues paramédicales et EMC soins infirmiers d’EM Premium (liste des revues spécialisées)
Le test est ouvert jusqu’au 31 mars. Votre avis nous intéresse, faites-nous un retour en remplissant notre questionnaire en ligne.
![]()
Vous recherchez des éléments sur un écrivain, un mouvement littéraire ou une période ? La Bibliographie de la Littérature française recense les études et articles sur la littérature française et francophone du XVIe siècle à nos jours, publiés depuis 1998 en France et à l’étranger. Plus de 150 000 notices détaillées sont disponibles, dont plus de 17 000 comptes rendus, et 72 000 articles issus du dépouillement des ouvrages collectifs.
La base s’enrichit quotidiennement, et une mise à disposition des années antérieures (1997-1979 et 1948-1894) est à l’étude.
Nous vous proposons de tester la BLF sur le site des Classiques Garnier du 2 au 31 mars. Et n’oubliez pas ensuite de nous donner votre avis en remplissant cette mini-enquête !
![]()
L’API d’Isidore pour en explorer les données, c’est chouette. L’accès par un Sparql Endpoint, c’est encore mieux !
Mais avant toute chose, un petit crochet par les concepts et technologies de base du Linked Open Data s’impose (car c’est de cela qu’il s’agit).
Et commençons donc par le formalisme RDF (pour Resource Description Framework) qui ne désigne rien de moins que le modèle de description et de publication des ressources et des métadonnées sur le web. Cette modélisation s’appuie sur 3 fondamentaux :
<http://www.sudoc.fr/180856936/id> <dc:title> “Merci pour ce moment" <http://www.sudoc.fr/180856936/id"> <marcrel:aut> <http://www.idref.fr/115490108/id>
L’ensemble des triplets constitutifs d’une base de données RDF (Isidore, le Sudoc, l’INSEE, DBPedia…) sont stockés dans un triplestore et forment donc un graphe qu’il est possible de requêter grâce au langage Sparql (assez similaire au SQL, le langage de requête des bases de données relationnelles) via un point d’accès web, un Sparql Endpoint.
Retour donc à Isidore dans le web de données : Isidore moissonne ses diverses sources selon le protocole OAI-PMH, c’est-à dire rapatrie des sets de données en format Dublin Core, les convertit en triplets RDF, les enrichit par croisement avec des référentiels externes, puis stocke tout ça dans un triplestore accessible avec Sparql par le Sparql Endpoint Virtuoso d’Isidore.
Et illustration de l’intérêt de tout ça avec un cas pratique : comment exploiter les données d’Isidore afin d’obtenir et étudier un corpus constitué de composants Calames et de publications autour des fonds patrimoniaux que possède ma BU (par exemple Henri Bosco, Gabriel Germain, Georges Perros, Samivel… et Michel Butor tant qu’on y est) ?
Pour commencer, on formule sa requête dans le Sparql Endpoint, ici une requête de type CONSTRUCT qui permet d’obtenir un set de résultats formant lui-même un graphe « personnalisé » à partir du graphe d’Isidore, puis on choisit la sérialisation (le format de sortie, RDF/XML en l’occurence) de ce nouveau graphe :
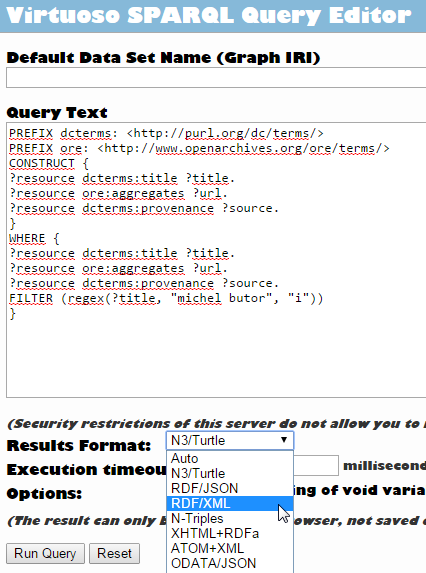
Graphe que l’on peut donc visualiser comme tel :
Ou plus joli, plus dynamique et en ligne :
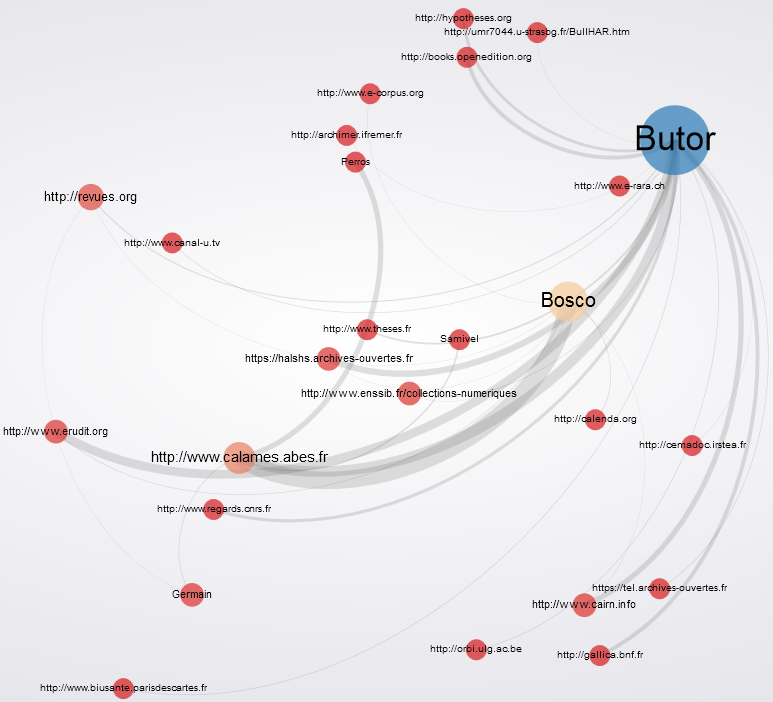
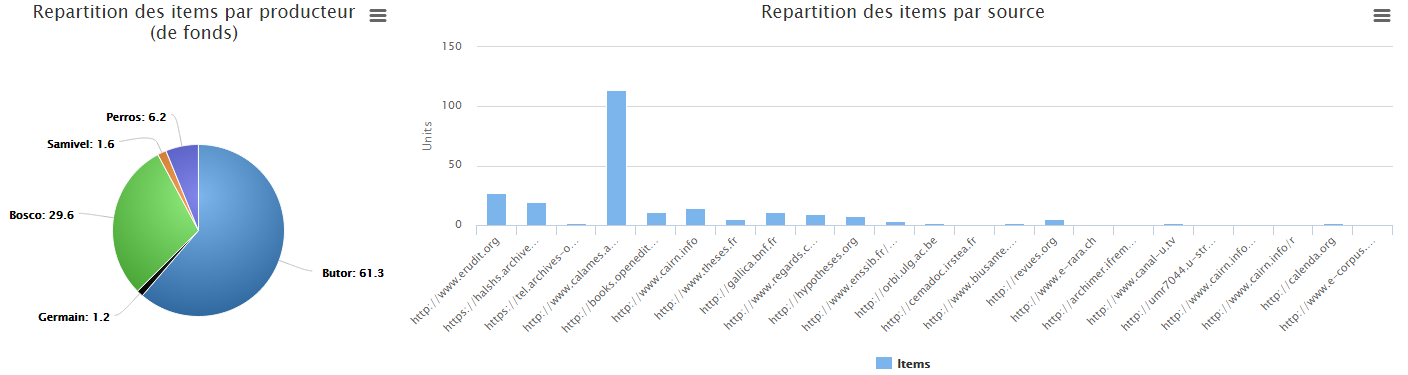
On peut aussi (essayer de) faire de jolis graphiques de visualisation statistique du corpus constitué : poids relatifs de chaque auteur dans les résultats, répartition par source de données…
Dans la même lignée, puisque Isidore enrichit ses données avec le référentiel Geonames, rien n’empêche de cartographier l’ensemble des résultats. Et puisque data.bnf propose aussi son Sparql Endpoint, pourquoi ne pas faire une réquête conjointe sur le graphe d’Isidore et celui de data.bnf afin de s’approcher d’une vue FRBRisée (hiérarchisée) des documents relatifs à ces fonds ? Par exemple pour le fonds Henri Bosco :
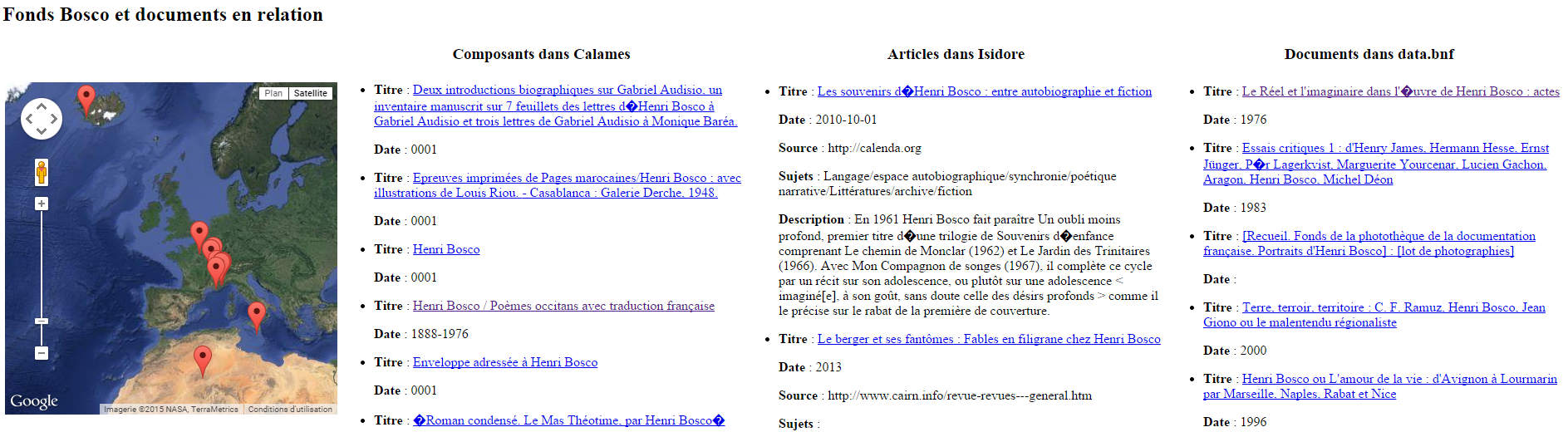
Pour visualiser la page web, c’est ici
Ainsi, les métadonnées d’Isidore formalisées en RDF, c’est la possibilité de :
Au-delà des formats et des normes, il est sans doute là l’enjeu pour nos données bibliographiques comme pour les autres (données de gestion , données de la recherche…) : s’inscrire dans cette nouvelle brique de l’architecture du web où ce ne sont plus les pages html ou les documents qui sont liés mais les données et participer à la constitution d’un graphe, un jour, devenu universel.
Logiciels libres utilisés : Rhizomik RedeFer (et ses supers API), gexf-js Viewer, Highcharts
NB : pour ceux qui la chercheraient, il y encore une culotte quelque part…

Quand la cuisine rencontre le numérique
Les BU de Nice aiment la cuisine ! Après avoir servi la Petite cuisine de la documentation électronique en 3 plats, nous proposons aujourd’hui la recette du dépôt d’article sur son lit d’archives ouvertes, et sa sauce Creative commons, accompagnés de vraies bonnes recettes à télécharger, et à faire mijoter en même temps que vous déposez votre article… Mais pourquoi des recettes de cuisine sur un blog dédié aux publications scientifiques électroniques ?
Pour attirer les gourmands et leur expliquer comment déposer un article dans Hal, mais aussi pour éclairer sur la différence entre ce qui est LIBRE et ce qui est GRATUIT… valable aussi bien dans le domaine universitaire que dans le quotidien. On entend en effet très souvent « Moi je préfère ResearchGate à Hal… », « Je préfère Googledocs à Framapad… », « Je préfère Photofiltre à Gimp… », « Je préfère Internet Explorer à Firefox… », « Je préfère Facebook à Diaspora*… », « Je préfère Marmiton à Cuisinelibre... », avec toujours la même chute « C’est pareil, c’est gratuit ! »
On a le droit de préférer ce qu’on veut, mais en connaissance de cause, car non ce n’est pas pareil : ResearchGate, Googledocs, Photophiltre, Internet explorer, Facebook, Marmiton sont peut-être gratuits, mais pas libres. Ils imposent à tous ceux qui les utilisent et les alimentent des restrictions et des obligations, et privatisent les données. Ce qui n’est pas le cas de Hal, Framapad, Gimp, Firefox, Diaspora* et Cuisine libre, qui eux sont libres. Chaque outil mériterait un comparatif et un développement détaillé du point de vue juridique, philosophique, économique, technologique ou social, mais pour commencer simplement, petite explication en cuisine :
Il existe des sites de cuisines « collaboratifs », où sont disponibles gratuitement des recettes, déposées par les internautes. Gratuitement, mais pas librement ! En effet, ces sites imposent des conditions restrictives à ceux qui y publient et qui les consultent. C’est le cas par exemple de Marmiton. Les conditions d’utilisation des recettes sont strictement encadrées : on peut « utiliser toutes les recettes diffusées sur le site pour [un] usage privé : repas entre amis ou en famille » uniquement. Les professionnels ont un droit limité, ils sont obligés de mettre un commentaire sur le site et de l’indiquer sur leur menu. Les écoles de cuisines n’ont pas le droit d’utiliser les recettes. Et enfin les recettes deviennent la propriété du site. Sans remettre en cause le fonctionnement et les objectifs commerciaux légitimes de Marmiton, on constate qu’il y a une privatisation d’un savoir fourni par une communauté dont la première (seule ?) motivation est de partager leur goût pour la « bonne bouffe »… En d’autres mots, les recettes, les commentaires, toutes informations n’appartiennent plus à ceux qui les ont déposés, mais à l’entreprise, qui a déjà sorti un magazine imprimé payant, mais qui pourrait aussi par exemple décider de bloquer un jour l’accès à toutes les recettes pour uniquement les commercialiser.
Il existe un site de cuisine libre, qui respecte le philosophie de partage et de diffusion du savoir (culinaire), Cuisinelibre.com. La licence Creative Commons CC BY SA appliquée aux recettes autorise leur réutilisation quel que soit l’environnement et le statut, amateur, professionnel, enseignant, avec comme seule limite celle de la licence. Il s’agit de citer l’origine de la recette et d’appliquer la même licence. On peut même les vendre si on veut, l’essentiel étant que ça ne limite pas la liberté des autres cuisiniers potentiels. C’est ce qui nous a permis de les reproduire, de les modifier, de les distribuer pendant l’Open Access Week, et de les diffuser sur ce blog.
Et le même raisonnement s’applique à tous les outils, réseaux et sites cités au début de ce billet. Même si ici la démonstration a ses limites : de toute façon, juridiquement les recettes de cuisines ne sont pas protégées en France par le droit d’auteur, vous pouvez donc faire ce que vous voulez de toutes les recettes trouvées sur le web… Mais on avait besoin de justifier pourquoi on travaillait sur la tarte à la bière et la tartiflette 🙂
Bon appétit et bon dépôt !
Les recettes sont là !
En octobre 2014, vous avez été près d’une cinquantaine à participer à l’Open Access Week. A Nice, nous avions proposé aux doctorants et aux chercheurs de venir partager un quart d’heure Open Access (QOA), autour d’un café. Certains ont ainsi pu déposer des articles dans Hal, dont la nouvelle version venait de sortir. Tous ont pu poser des questions sur l’open access, avec souvent les mêmes préoccupations.
Alors pour les graver dans le marbre, enfin dans les pixels, on prolonge le QOA ici avec des billets qui ne vous prendront pas plus d’un quart d’heure de lecture, promis ! Pour commencer, LA question la plus courante :
J’ai super méga envie de déposer mon article dans une archive ouverte, mais le problème, c’est qu’il est déjà publié dans une revue… Donc je peux pas le faire, parce que j’ai pas le droit de toute façon, hein ?
Eh bien détrompez-vous, vous avez le droit de déposer votre travail en archive ouverte dans la plupart des cas… Il faut seulement vérifier le cadre juridique, et si on oublie (juste un instant) toutes autres considérations ou motivations, ça donne ça :
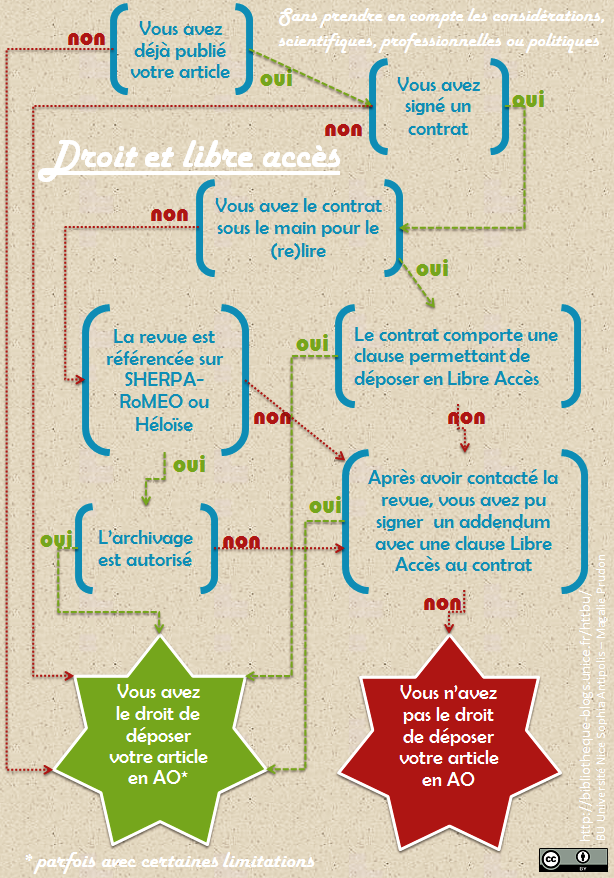
Les aspects juridiques du dépôt : droit ou pas droit de déposer en archive ouverte (AO) ?
Contrairement aux a priori, de nombreux éditeurs autorisent le dépôt en libre accès, même si c’est parfois uniquement pour le preprint (on distingue preprint, postprint ou reprint), ou parfois avec un embargo (un délai entre la date de publication dans la revue et celle dans une archive ouverte, délai pouvant être géré automatiquement par Hal).
Un dernier conseil : si vous n’avez pas encore publié l’article, et que vous êtes en phase de discussion avec un éditeur, c’est l’occasion de demander d’inclure une clause d’exception pour la diffusion en libre accès dans votre contrat !
Dans le cadre du projet d’investissement d’avenir Istex, quatre nouveaux corpus acquis en licence nationale sont disponibles pour la communauté scientifique de l’UNS.
 |
Près de 2 200 titres de revues scientifiques de l’éditeur Wiley, de 1791 à 2011. Ces périodiques couvrent des disciplines diverses dont l’écologie, les mathématiques,la chimie, la physique et les sciences de la santé. | Accéder au texte intégral Liste des titres |
 |
Accès à 64 titres médicaux, parus depuis le début des publications jusqu’à 2013 inclus. | Accéder au texte intégral des revues BMJ Liste des titres |
 |
Un peu plus de 500 titres De gruyter couvrant la période de 1826 à 2012. Ces archives de revues relèvent de domaines de recherche variés, incluant notamment des ressources en sciences humaines et sociales. | Accéder au texte intégral Liste des titres |
 |
Plus de 600 revues Sage couvrant l’ensemble des disciplines de recherche (STM et SHS), jusqu’en 2009. | Accéder au texte intégral Liste des titres |
Ils rejoignent les douze autres corpus déjà ouverts.
Bonnes explorations !
 SCD BU Université Nice Sophia Antipolis
2015 |
Propulsé par WordPress et Mystique thème par digitalnature
SCD BU Université Nice Sophia Antipolis
2015 |
Propulsé par WordPress et Mystique thème par digitalnature