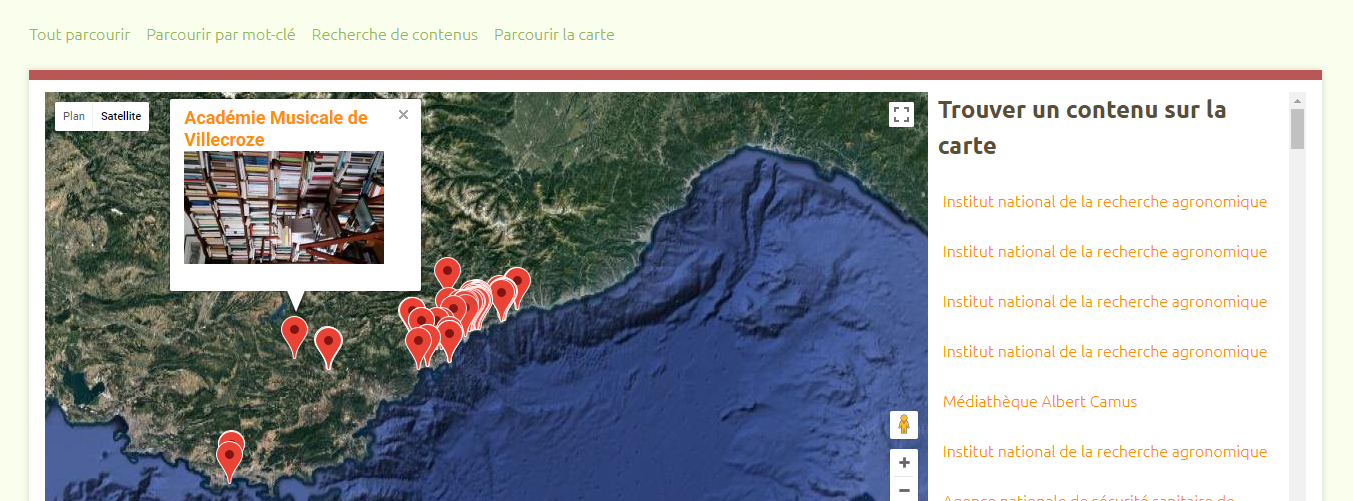
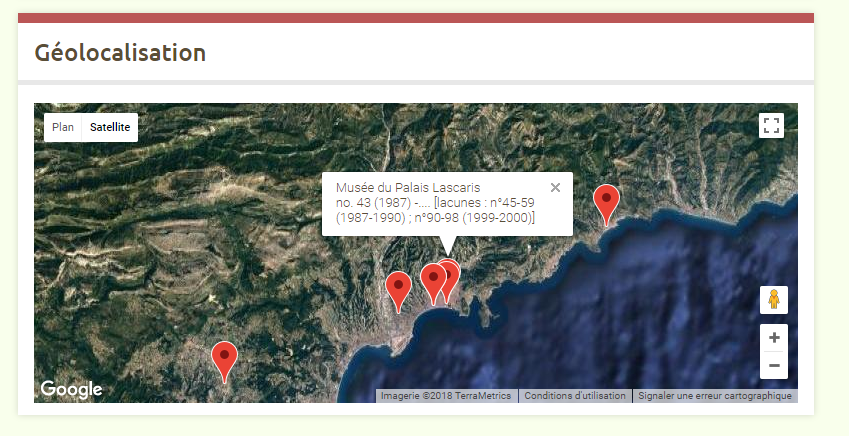
Centre du Réseau Sudoc-PS PACA/Nice
Articles taggés visualisation des données
Application Unicas / Presse locale ancienne : grosse actu ! (5/5)
Il y a 4 ans
Car il faut bien l’avouer, depuis sa présentation lors de la 7ème journée annuelle du réseau et sa mise en production dans la foulée, l’application était un peu restée « dans son jus » : pas totalement finalisée dans sa partie documentation, soumise à quelques bugs techniques sur les visualisations en graphe, un code source indisponible etc…
Cela ne nous a pas empêché de l’utiliser, comme prévu, en tant que base de travail pour l’amélioration de la qualité des métadonnées durant les 4 derniers mois de 2020 (comme décrit dans ce précédent billet), mais une petite remise à niveau s’imposait tout de même.
Outre les améliorations portant sur l’architecture de l’application elle-même, l’interface web présente elle aussi quelques mises à jour ayant pour but d’améliorer l’expérience des utilisateurs :
- sur les vues spécifiques dédiées aux unicas et aux titres de presse locale ancienne, les métadonnées se présentent désormais sous forme de tableaux web avec les principales fonctionnalités nécessaires à leur manipulation : des tris par colonne en cliquant leurs entêtes, des filtres par colonne sur la base d’opérateurs textuels ou par valeurs uniques, un moteur de recherche global tous champs, une fonctionnalité de regroupement par ligne (donc notice) selon un critère commun, la possibilité d’export Excel etc…
- le changement de librairie graphique pour les visualisations en réseau a permis de stabiliser la page dédiée et d’améliorer la lisibilité des graphes produits, permettant au passage d’afficher des vues intéressantes sur les collections du CR, par exemple cette visualisation des localisations de titres de presse locale conservés (et souvent co-conservés sur plusieurs bibliothèques).

- Côté documentation enfin, notamment pour expliciter les modalités de redistribution par API des données stockées dans la base de données en graphe et faciliter leur éventuelle réutilisation dans d’autres contextes ou applications, cette nouvelle page a été ajoutée, qui décrit la structures et fonctions de l’API selon un standard Open source très largement connu et utilisé par les développeurs.
Concernant le code de l’application proprement dit, sa mise à disposition en open source était une spécification incontournable pour nous dès le début, à la fois par philosophie et pour tous les avantages induits par l’ouverture des codes (relecture, processus collectif d’amélioration, réutilisations… ). L’Abes s’étant de son côté lancé depuis plusieurs mois dans une politique de développement (au sens informatique du terme) centrée entre autres sur la mise en open source de leurs codes et l’impulsion d’une dynamique de co-construction avec les membres du réseau Sudoc, il nous est donc apparu naturel de libérer le code source de l’application en le déposant sur l’espace Github de l’Abes, le rendant accessible dans une version documentée ici : https://github.com/abes-esr/sudocps-graph-app. En accord avec l’Abes, nous avons d’ailleurs accompagné ce dépôt par la publication d’un billet sur Punktokomo, le blog technique créé et maintenu par l’Abes.
Enfin, en bonne place parmi les objectifs nous ayant guidé(e)s pour la réalisation et le développement de l’application, et en corollaire du point précédent, se trouve également la possibilité pour les autres Centres du réseau Sudoc-PS de reprendre à leur compte autant le workflow d’alimentation de la base de données que le code informatique de l’application, afin de pouvoir relativement facilement déployer leur propre version basée sur les données de leur périmètre. Et effectivement, le CR voisin PACA/AIx-Marseille, emmené par notre collègue du SCD de l’AMU Axelle Clarisse, nous a récemment contacté en ce sens, aboutissant dans une première étape à la mise en ligne d’un prototype exploitant les unicas et les titres de presse locale du CR Sudoc-PS marseillais, utile de leur côté afin d’avoir un premier aperçu de leurs données sans avoir à se lancer dans une procédure d’installation en dur, et indispensable pour nous afin de nous permettre de vérifier et ajuster la reproductibilité du dispositif.
Et puis dans la région PACA, Nice et Marseille qui collaborent, c’est assez remarquable pour être remarqué !
L’application Unicas / Presse locale ancienne est désormais accessible
Il y a 6 ans
L’application Unicas/Presse locale ancienne a été dévoilée lors de la 7e Journée du réseau Sudoc-PS Paca/Nice.
Pour faciliter son accès et son utilisation, nous lui avons consacré une page spécifique sur notre blog, à côté des autres outils Colodus et Cidemis. Vous pouvez dès à présent la consulter.
Développée en interne, cette application permet d’explorer directement les données des collections de périodiques du Centre du Réseau Sudoc-PS PACA/Nice.
Elle a plusieurs finalités :
- Valoriser les collections anciennes et/ou rares des bibliothèques du CR
- Permettre aux établissements du réseau de lister leurs unicas (= les titres conservés dans un seul établissement)
- Rechercher facilement les titres de presse locale ancienne conservés dans les centres documentaires appartenant au CR
- Améliorer la qualité des données de ces collections spécifiques, en donnant à voir les manques dans les notices bibliographiques (absence d’ISSN, notamment)
- Exporter les données sous forme de tableaux Excel
- Visualiser les liens entre les bibliothèques et les collections sous forme de graphes
Enfin, des liens cliquables permettent de rebondir sur le catalogue national Sudoc, sur le site Presse locale ancienne de la BnF ou de renvoyer vers des numérisations existantes.
Suite à l’atelier de manipulation de la Journée du réseau, nous allons travailler à intégrer les améliorations suggérées.
Bonne exploration !
Pour aller plus loin : billets techniques ou « comment s’est construit l’application » :
- Mission : enrichir et faire parler les données du CR (1/5)
- Enrichir et faire parler les données du CR (2/5) : focus sur les unicas
- 3/5 : Enrichir et faire parler les données du CR : la première brique est posée !
- Enrichir et faire parler les données du CR (4/5) : passage par la case modélisation

7e Journée du réseau SUDOC-PS Paca/Nice, le mardi 5 novembre 2019
Il y a 6 ans
A vos agendas ! La 7e Journée des bibliothèques du réseau SUDOC-PS du Centre régional PACA/Nice aura lieu le mardi 5 novembre 2019, de 9h à 16h. Vous êtes cordialement invité·e·s à participer à cette journée d’information et d’échanges sur les actualités du Centre Régional et nos pratiques professionnelles.
Cette année c’est la Bibliothèque du Chevalier de Cessole qui nous accueille, au sein du Musée Masséna, 65 rue de France à Nice. La journée se partagera entre informations professionnelles, ateliers pratiques, et visites guidées. Afin de faciliter l’organisation de cette rencontre, merci de bien vouloir confirmer votre participation en complétant le formulaire d’inscription en ligne avant le 6 octobre.

Le musée Masséna (Nice). Photo Jean-Pierre Dalbéra, Wikimedia Commons, CC-BY-2.0
Déroulement de la journée :
9h00 : Accueil des participants à la Villa Masséna autour d’un petit-déjeuner.
9h30 : Début des interventions, introduction de la Journée.
10h00 : Intervention autour du traitement des périodiques de la Bibliothèque du Chevalier de Cessole et du projet de numérisation de la revue Mediterranea.
10h30 : Démonstration de l’application du Sudoc-PS pour la visualisation des données et le signalement des unicas et de la presse locale ancienne.
11h15 : Pause café
11h30 – 12h15 : 3 groupes en alternance participeront aux activités suivantes :
* Atelier de manipulation de l’application Unicas/Presse locale ancienne
* Visite guidée de la Bibliothèque du Chevalier de Cessole et ses réserves
* Visite guidée du Musée Masséna et ses collections permanentes
12h30 – 14h : Pause déjeuner (buffet offert).
14h-14h45, puis 15h-15h45 : reprise des 3 groupes du matin en alternance : atelier de manipulation de l’application, et visites guidées. Au fil de la journée chaque groupe suivra l’atelier de manipulation et les 2 visites.
16h : Fin de la Journée.
◊ Accès en transports publics : tramway ligne 2, arrêt Alsace-Lorraine. Parking (payant) : Palais Masséna. Voir ici l’ensemble des transports en commun disponibles aux alentours.
◊ N’hésitez pas à nous contacter pour toute demande de renseignements complémentaires.
Enrichir et faire parler les données du CR (4/5) : passage par la case modélisation
Il y a 6 ans
par Géraldine Geoffroy
dans Trucs & Astuces
Début mars 2019 s’est tenu à Berlin un Workshop du W3C autour de la structuration des données en graphe et de leur intégration dans le web. Présentée ainsi, la problématique paraît triviale puisque le W3C est justement l’organisme qui gère et promeut ce qu’on appelle le web de données, c’est-à dire l’adoption des standards de la modélisation en RDF (qui est par nature un graphe) pour « pousser », lier et ouvrir les données sur le web. En fait, ce Workshop est le résultat d’un constat : d’une part il y a les modélisations de type web de données donc, avec leurs univers de données identifiées par des URIs sémantiquement décrites et connectées entre elles grâce à des ontologies (et il est vrai que le Linked Open Data Cloud ne cesse de s’étendre), mais à côté on constate également l’utilisation croissante par des acteurs divers et variés (économiques, institutionnels…) de bases de données non-relationnelles dites orientées graphe dans des logiques de curation et visualisation de données décorrélées des problématiques du web.
De quoi s’agit-il ? Il s’agit de structurer ses données comme un ensemble de noeuds (dotés d’attributs sous forme de paires clé-valeur pour les décrire) liés entre eux par des relations (elles-mêmes qualifiées par d’autres attributs) , tout en étant complètement libre dans la détermination des entités, du type de leurs liens et de la nature de leurs propriétés*. Ces modélisations dites de type property graph, jugées à l’usage très performantes pour traiter des masses exponentiellement croissantes de données plus ou moins structurées (le fameux Big Data, qui s’ouvre désormais aux objets connectés !), répondent donc à un besoin auquel la modélisation type RDF répond mal :
- de la flexibilité et de la souplesse dans la création et l’annotation des entités et de leurs connexions,
- un stockage des données de ce fait optimisé par des graphes beaucoup moins verbeux,
- des langages d’interrogation spécifiques à chaque base de données mais relativement simples (toujours plus simples que du SPARQL de toute façon !) et très puissants pour parcourir des chemins dans le graphe.
On comprend donc mieux la teneur du Workshop qui visait en fait à établir des ponts entre deux technologies, l’une dédiée à l’ouverture et l’échange de données, l’autre au stockage et à la navigation dans les données, mais utilisant toutes deux des modélisations en graphe (en sous-texte, « ça sent le roussi » pour le RDF qui pour x raisons reste une technologie de niche, tandis que parallèlement se développe le property graph pour des raisons de pragmatisme et d’efficience).
Pour donner une idée de la diversité des cas d’usages où l’approche property graph se révèle pertinente, on peut mentionner le Consortium International des Journalistes d’Investigation qui a travaillé sur les Panama papers en recourant à une base de données orientée graphe, et ce dans une démarche heuristique pour mettre à jour les connexions dans les 11,5 millions de documents non-structurés qui avaient fuités. Pour ceux que cela interesse, une brève news ici et un billet plus complet ici
Et donc ??? Pourquoi cette loooongue introduction et quel est le rapport avec l’application sur les données de périodiques du CR dont on vous parle depuis 3 billets maintenant (sachant qu’à l’échelle du CR on ne se trouve pas vraiment des problématiques de Big Data) ?
Le lien se trouve dans la modélisation : nous en étions à la fin du billet précédent sur une mini app en tant que preuve de concept sur les données des unicas, il s’agit maintenant de passer à l’échelle sur l’ensemble des données d’unicas et de presse locale au niveau du CR, et de construire les traitements de données au coeur de l’application, afin de créer et automatiser les workflows qui permettront de passer de listing de données issus du Sudoc et du catalogue général de la BnF à une interface web où chaque bibliothèque du réseau pourra visualiser et interroger ses collections, et disposer des métadonnées. La difficulté de l’exercice tient alors à la variabilité des périmètres (CR/RCR) et la multiplicité des sources d’enrichissement des données. En effet, si les trois sources primaires sont bien identifiées et (manuellement mais) facilement récupérables :
- une liste de ppn de tous les unicas de toutes les bibliothèques du CR -> récupérés à partir de Self Sudoc,
- une liste des identifiants ark de tous les titres de presse locale ancienne sur les deux départements Alpes-Maritimes et Var + Monaco référencés sur le site http://presselocaleancienne.bnf.fr/accueil -> récupérés à partir de la fonction d’export en csv par lots du catalogue général de la BnF (voici par exemple un lien profond permettant d’isoler ces titres pour les Alpes-Maritimes : https://catalogue.bnf.fr/search.do?mots1=ALL;2;0;devenu&mots0=GES;-1;0;bipfpig06&&pageRech=rav),
- une liste les bibliothèques de l’ILN 230 du CR -> issue du web service iln2rcr.
Il faut ensuite requêter plusieurs services d’exposition des données mis à disposition par l’Abes et la BnF pour construire le corpus de métadonnées (ce billet précédent détaille par exemple une méthode d’interrogation de web services et de traitement des résultats dans Excel pour les unicas *)
*A noter qu’entre temps un nouveau web service a été mis en place par l’Abes qui permet d’obtenir les notices complètes en Unimarc/Xml à partir de l’extension .xml ajoutée aux urls pérennes du Sudoc (par exemple https://www.sudoc.fr/156143453.xml), plutôt que les notices incomplètes exposées en RDF. A noter également que désormais les champs ISSN sont exposés dans les notices. Gros avantage enfin, outre la complétude des données bibliographiques, les données d’exemplaires sont également délivrées en fin de notice, ce qui à première vue économise des appels au web service multiwhere pour retrouver les bibliothèques localisées sous les notices. Mais à première vue seulement, car les données d’exemplaires ne contiennent « que » le rcr des bibliothèques : si l’on souhaite des données plus riches (nom et géolocalisation de l’établissement), il faut de toute façon revenir à l’API multiwhere, puisqu’il n’existe pas (à ma connaissance tout du moins) de web service permettant d’obtenir des notices RCR en Unimarc/xml à partir du numéro RCR (les accès aux web services d’Idref qui exposent les données d’autorités en Unimarc/xml se font sur la base du ppn).
Ce qui donne schématiquement si on se concentre sur le côté traitement de données :
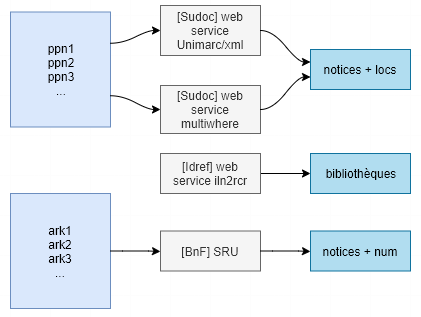
mais qui n’est qu’une partie du schéma global du projet :
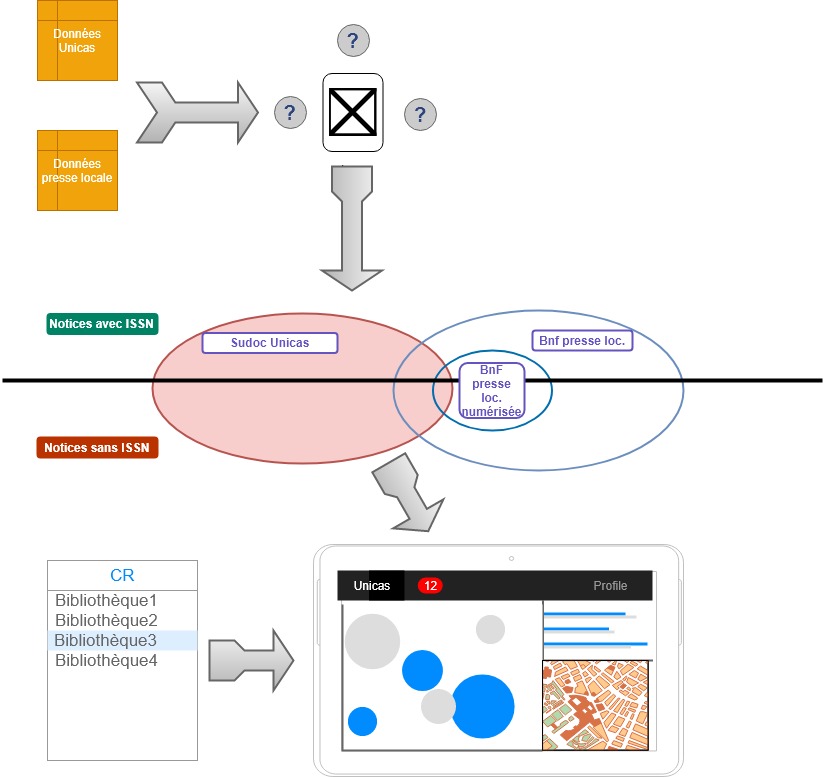
Il s’agit donc de trouver la modélisation, le stockage et le chaînage des traitements de données adéquats qui permettent de déterminer précisément le périmètre des unions et intersections entre « blocs de données » représentés par les cercles au centre du schéma, autrement dit de trouver un moyen de pouvoir répondre aux questions à la fois au niveau global du CR et particulier de chaque RCR : combien unicas ? Parmi ceux-ci quelles notices n’ont pas d’ISSN et peuvent faire l’objet d’une demande via Cidemis ? Quelle est la répartition territoriale et par bibliothèque des titres de presse ? Parmi les titres de presse concernant les AM, lesquels sont également des unicas ? Quels sont les unicas détenus par les bibliothèques monégasques pour lesquels une version numérisée est accessible ? Bref, comment NAVIGUER dans les données ?
C’est ici que l’on retrouve nos graphes : quand il s’agit de parcours dans les données, autrement dit ici de requêtes croisées entre sources distinctes, il est avantageux de sortir de la logique relationnelle de jointures entre fichiers plats et de passer à une modélisation type graphe. Ainsi, en décidant d’adopter une base de données orientée graphe (Neo4j en l’occurence) basée sur une modélisation property graph, le coeur du travail consiste à bien déterminer (et ce en fonction des questions auxquelles on veut pouvoir répondre) :
- les types d’entités à modéliser (les noeuds du graphe et leurs attributs),
- les liens entre les entités et les propriétés (caractéristiques) de ces liens,
- parmi ces connexions, celles que l’on connait de par la structure des sources de données, et celles que l’on crée dans la base de données par algorithme d’alignement entre noeuds.
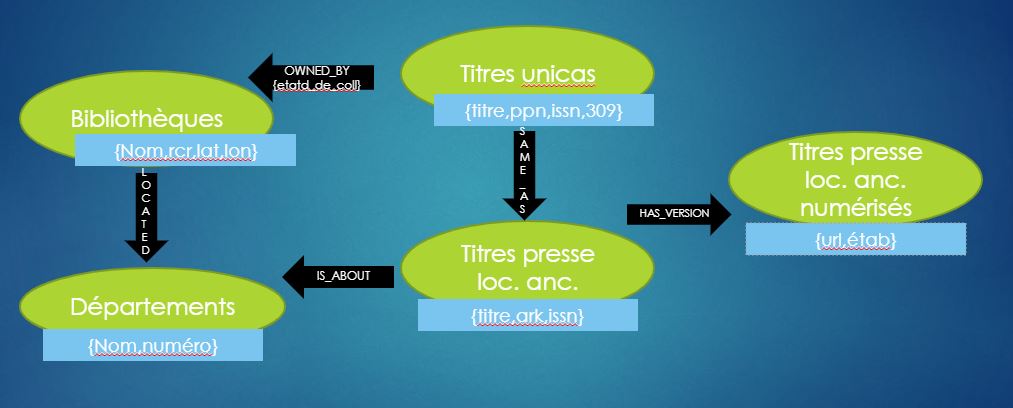
Si on « recolle » à nos données Sudoc et BnF, voici ce que cela donne en substance :
– on créé des noeuds de type Bibliothèques qualifiés par des attributs de nom, RCR, latitude et longitude et des noeuds de type unicas caractérisés par quelques éléments extraits de la notice Sudoc (titre, ppn, issn, zone 309) ; ces noeuds peuvent être connectés par une relation illustrant la localisation du périodique, ce lien étant créé à partir à partir du web service multiwhere.
– On créé également des noeuds représentant les titres de presse locale définis par les métadonnées de titre, identifiant ark et issn; on définit une relation d’équivalence « same_as » avec les noeuds unicas quand l’attribut issn est le même.
– On ajoute des noeuds qui représentent les versions numérisées des titres de presse locale quand le champ correspondant est présent dans la notice Unimarc/xml renvoyée par le SRU de la BnF, et on les relie aux noeuds de type presse locale ancienne représentants les versions imprimées
– etc…
[Cliquer sur l’image pour voir l’animation]
Voilà pour le modèle de données… Évidemment l’alimentation du graphe dans la base de données ne s’effectue pas manuellement, l’ensemble du workflow est automatisé (notamment pour faciliter les mises à jour et favoriser la reproductibilité du processus). La démarche est la suivante :
- on effectue un chargement initial à minima dans la base de données en important uniquement les listes de ppn d’unicas et d’ark de presse locale,
- on automatise les enrichissements (ajouts des attributs et des liens) par des requêtes aux API précédemment explicitées directement dans la base de données (grâce à une librairie de fonctions et procédures nommée Apoc intégrée comme un plugin à Neo4j). La succession des requêtes utilisées en langage Cypher est disponible sur ce Gist https://gist.github.com/gegedenice/c7e53cc4c3d65b8bc1639d4b55a90be6,
- on développe l’application au-dessus de la base de données pour proposer une interface web de visualisation et redistribuer les données du graphe par des API et des exports en Excel.
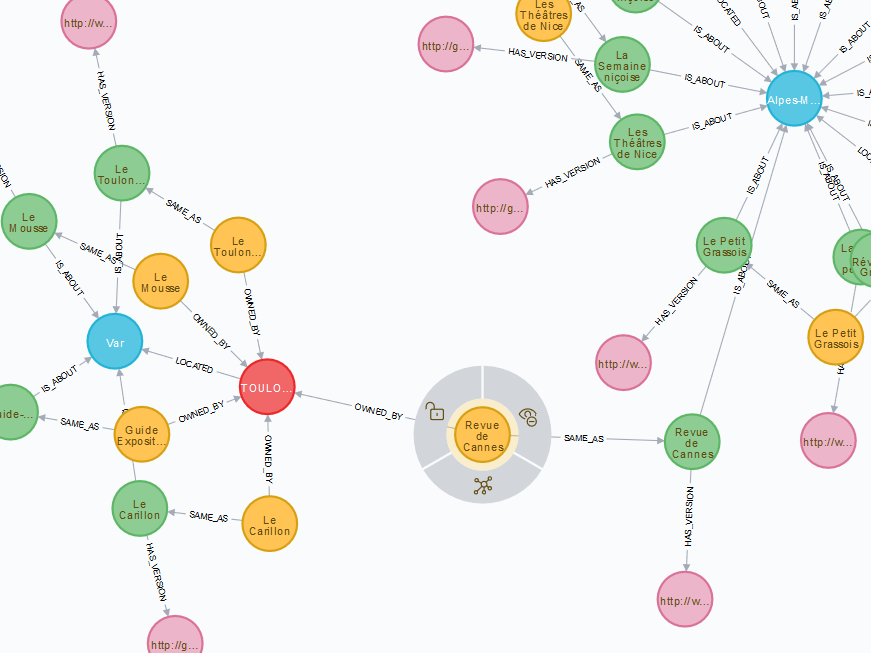
Voici un extrait du graphe final dans l’interface graphique de la base de données qui illustre exactement à quel point la dimension exploratoire est facilitée dans ce genre de visualisation et comment elle aide à mettre à jour des connexions qu’il serait extrêmement laborieux de mettre en évidence par des techniques plus classiques de jointures.
Au centre de l’image, le noeud jaune représente un unica (la Revue de Cannes), périodique également référencé comme un titre de presse locale ancienne (le noeud vert) concernant le département des Alpes-Maritimes (le noeud bleu) ayant fait l’objet d’une numérisation aux Archives municipales de Cannes (le noeud rose), mais dont la collection papier est détenue à la BM de Toulon (le noeud rouge).
Et la version web complète proposée dans l’application :
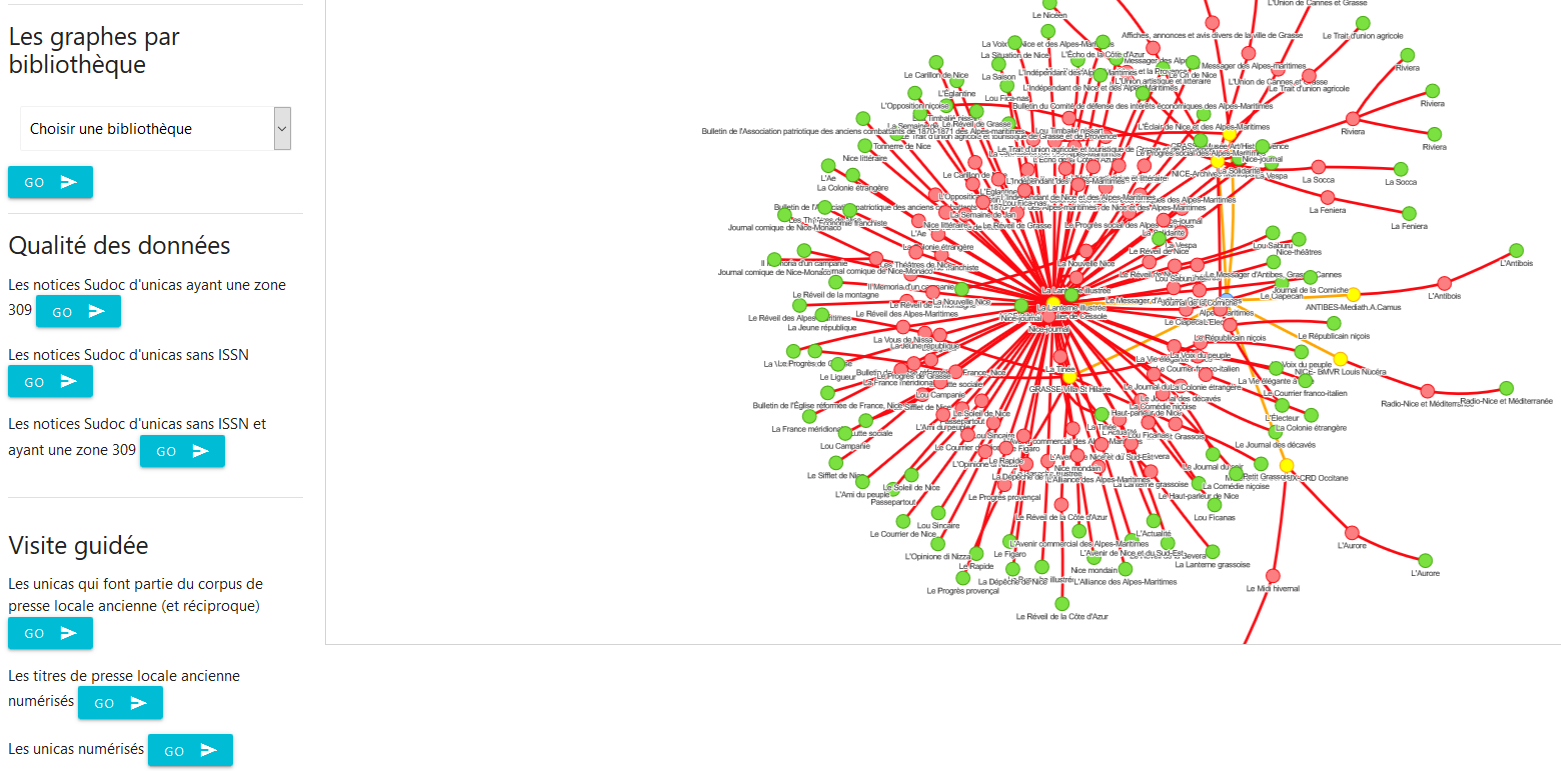
Comme prévu initialement, au-delà de la pure visualisation de parcours de graphe, l’application proposera des fonctionnalités de redistribution des données à destination des bibliothèques s’appuyant sur les traitements et appariements réalisés dans la base de données
| Sous forme d’API
(avec des urls paramétrables pour spécifier le rcr voulu) |
Par export Excel | Intégration de widget
sur une page web |
 |

|
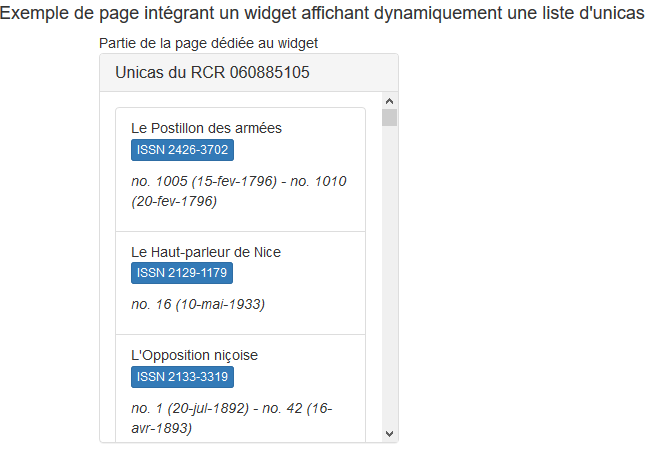 |

Quelques infos pratiques pour conclure (enfin !) en légèreté après cette avalanche de points techniques :
- l’application ouvrira en production à la rentrée universitaire 2019, elle sera présentée dans le détail lors de la prochaine journée annuelle du réseau le 5 novembre à la Bibliothèque du Chevalier de Cessole
- A la demande de l’Abes, nous l’avons déjà présentée le 27 mai 2019 à l’occasion de la journée Sudoc-PS qui se tient traditionnellement chaque année en marge des Journées Abes (programme). Le PowerPoint de notre présentation est accessible en ligne ici.
- Comme mentionné dans le billet, le code des requêtes utilisées pour alimenter le graphe est déjà disponible ici, le reste du code de l’application sera évidemment déposé en open source à l’ouverture.
* les seules conditions à remplir sont que le graphe doit être orienté et les nœuds labellisés
Retour sur la 6e Journée annuelle du Sudoc-PS Paca/Nice (novembre 2018)
Il y a 7 ans

Portrait. Thomas Leth-Olsen (Flickr, CC BY 2.0).
La 6e Journée annuelle du Centre du Réseau Sudoc-PS PACA/Nice s’est déroulée le mardi 6 novembre dernier. Nous étions reçus par la Bibliothèque Louis Nucéra (Bibliothèque Municipale à Vocation Régionale de Nice), où de nombreux collègues se sont mobilisés pour nous offrir le meilleur accueil. Merci à eux/elles !
La journée a rassemblé 54 participants venus de 28 établissements des Alpes-Maritimes, du Var, et de Monaco.
Après une présentation des actualités du Réseau, nous avons fait un point d’étape sur le projet de développement de notre interface de visualisation des données du réseau, pour une amélioration du signalement et une valorisation des collections de presse locales rares (unicas) et anciennes. Nous avions exposé les contours de ce projet lors de la Journée annuelle 2017, et depuis 3 billets ont été publiés sur ce blog pour vous tenir au courant de son évolution. Vous pouvez vous reporter au tout dernier billet (3/5) pour la synthèse de ce qui a été dit le 6 novembre.
Ensuite, les participants ont pu assister à une table ronde « retours d’expériences » autour de 3 projets régionaux de numérisation de collections :
- la numérisation du Bulletin de la Société d’études scientifiques et archéologiques de Draguignan et du Var, en collaboration avec la BnF (support de présentation)
- le projet de bibliothèque numérique en cours de réalisation au SCD de Nice (support de présentation)
- la bibliothèque numérique Odyssée de l’Université d’Aix-Marseille (support de présentation)
Chaque intervenant a pu aborder les questions de choix et de préparation des collections, de procédure en lien avec le prestataire, de mise à disposition du public via une interface en ligne, etc.
L’après-midi, les participants ont pu visiter les locaux de la Bibliothèque Nucéra (Tête carrée, salles de lecture, bibliobus, magasins et collections…), mais aussi la Bibliothèque d’étude et du patrimoine Romain Gary (bd Dubouchage), tout récemment rénovée.
Toute l’équipe du Centre du Réseau Sudoc-PS Paca/Nice espère vous retrouver nombreux lors de notre prochaine édition en 2019 !
Pour ceux/celles qui ne l’ont pas encore complété, notre enquête de satisfaction est toujours accessible. Vous pouvez aussi exprimer vos souhaits de thématiques à aborder pour la prochaine Journée Sudoc-PS. Merci d’avance !

3/5 : Enrichir et faire parler les données du CR : la première brique est posée !
Il y a 7 ans
par Géraldine Geoffroy
dans Trucs & Astuces
… et a été présentée à l’ensemble des bibliothèques du réseau à l’occasion de la journée annuelle du Centre du Réseau Sudoc-PS PACA/Nice le 6 novembre dernier. Cette journée fera l’objet d’un compte-rendu détaillé très prochainement sur ce blog, mais d’ici là arrêtons-nous un peu plus en détail sur l’application telle qu’elle commence à se dessiner.

Parce qu’il faut bien commencer quelque part, nous avons choisi de nous concentrer tout d’abord sur la mise à disposition du réseau d’une application « professionnelle » qui, par le biais notamment de la visualisation, se positionne comme un outil d’aide à la gestion des collections à destination des bibliothèques du réseau, et d’aide à la décision relative à cette gestion, notamment en apportant une vision consolidée de données relatives aux périodiques.
En cohérence avec l’axe « Valorisation des collections » de la convention 2018-2020 qui guide l’activité de notre Centre du Réseau Sudoc-PS PACA/Nice, l’application propose des points d’entrée ciblés dans la masse des 13 300 titres de périodiques du périmètre du CR, c’est-à-dire des accès via des sous-corpus pré-déterminés que sont les unicas et la presse locale ancienne (pour commencer, d’autres viendront peut-être plus tard). Pour rappel, l’objectif final est de valoriser ces sous-ensembles, et parallèlement de travailler très précisément sur la qualité de leur signalement.
Du point de vue des bibliothèques du réseau, les vues proposées dans l’interface sont censées leur permettre de répondre à 2 types de questionnement :
- identification : quels sont mes unicas (ou mes titres de presse locale ancienne) et comment puis-je les récupérer facilement ? En l’état, cette étape d’identification du périmètre et de collecte des données peut se révéler quasi impossible pour les bibliothèques (en tout cas sous forme automatisée). En tant qu’intermédiaire entre l’ABES (et la BnF pour la presse locale) qui exposent les données sous des formes variées (interfaces publiques, données en rdf, web services, SRU…) et les bibliothèques du réseau qui possèdent et gèrent les collections, le CR collecte les données en amont (voir ce billet pour la récupération des données des unicas) et les redistribue dans l’application.
- analyse : comment appréhender la nature de ces corpus (nombre de titres, répartition territoriale, etc) ? Comment disposer de manière consolidée un maximum de données relatives à mes titres de périodiques ?
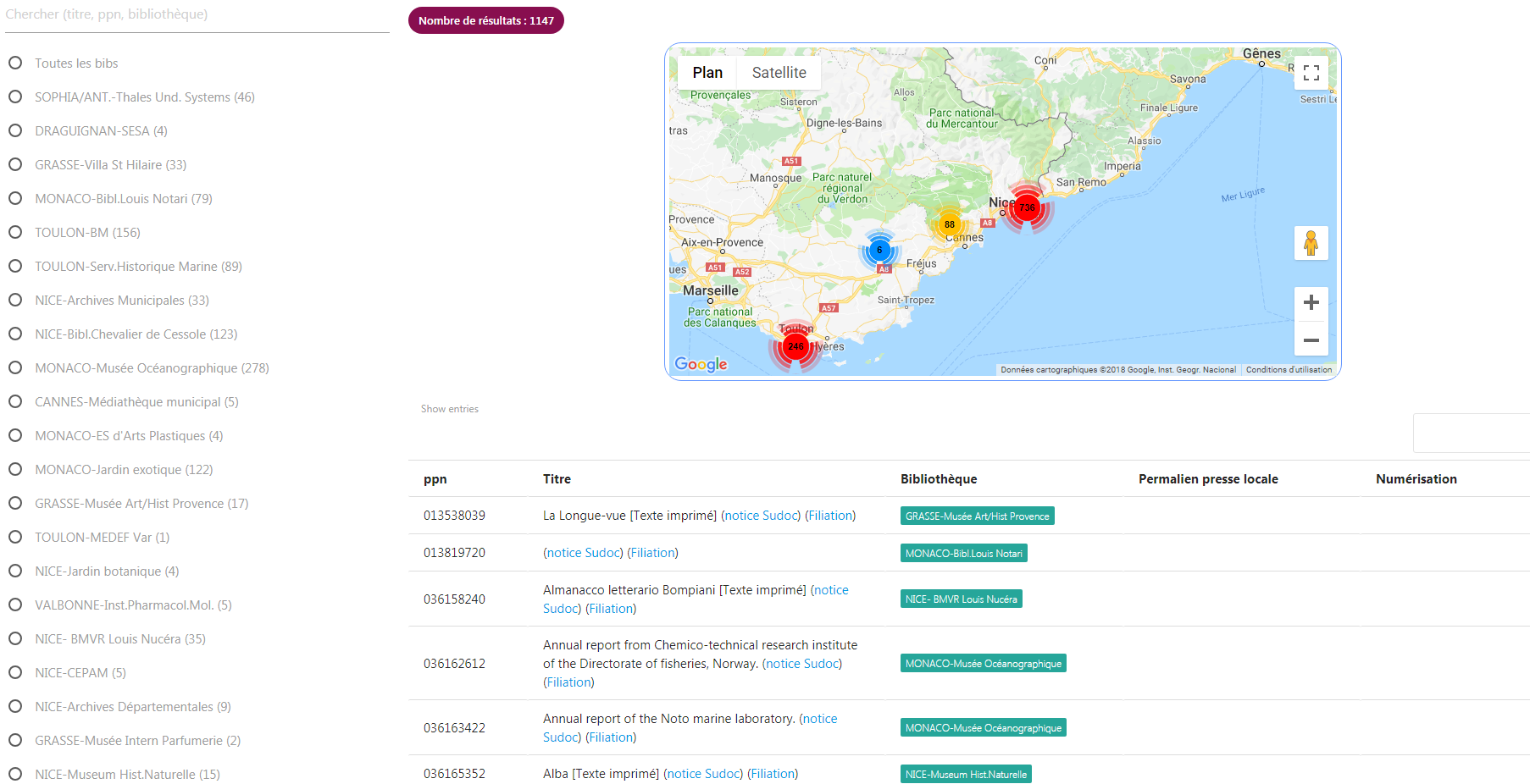
Cette page de l’application présentant la liste des 1147 unicas du CR avec un filtre par bibliothèque et un moteur de recherche est une première réponse.
A noter : au moment de l’export des données au mois d’avril dernier via le service en ligne SelfSudoc de l’ABES, le nombre d’unicas était de 1147. Aujourd’hui il est de 1176, ce qui soulève la question de la fréquence de mise à jour des données quand l’interface sera en production.
Mais il nous a aussi paru essentiel d’expérimenter une visualisation consolidée, fluide et dynamique de ce qui fait la spécificité de la description des périodiques, à savoir l’ensemble des filiations liées à chacun des titres et les localisations afférentes (ainsi que les états de collection via Périscope). Là encore l’idée est de fournir une visualisation qui permette de répondre rapidement à la question : si je possède une revue, quelle est sa continuité (territoriale notamment) de conservation sur toute son histoire et ses variantes ?
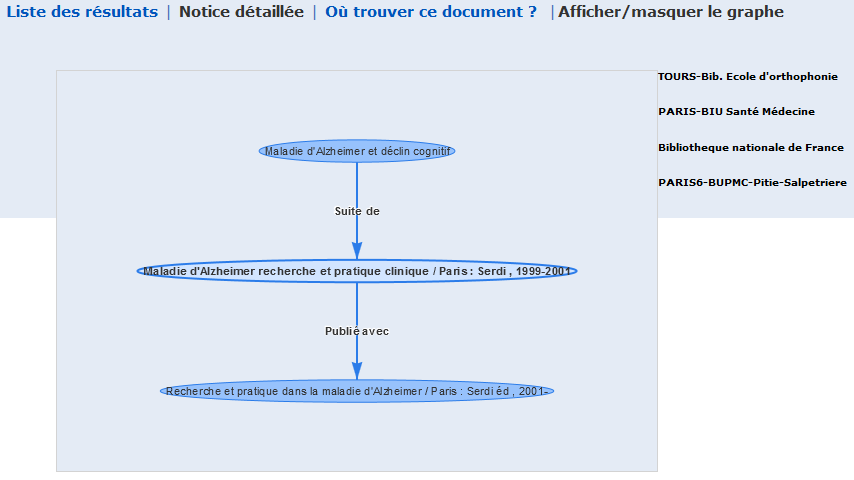
La réponse est une visualisation en graphe de la grappe des notices en lien avec chaque titre (par les zones 4XX de la notice, enfin plus précisément les propriétés équivalentes de la modélisation en rdf), à l’image de ce que renvoie le web service métarevues, mais avec une touche d’interaction : au survol de chaque nœud représentant une notice liée à la notice de départ par une relation de type « Suite de », « Devient », etc, les localisations correspondantes s’affichent, et surtout chaque clic sur chaque nœud déploie à son tour le graphe des notices liées, permettant ainsi de naviguer dans l’ensemble de la filiation qui caractérise l’histoire de la revue (comme montré dans la captation ci-dessous).

L’application est en développement mais une version bêta est néanmoins déployée sur la plateforme Cloud Heroku, et consultable ici : https://sudocpsproapp.herokuapp.com
Des améliorations restent à apporter au niveau graphique mais le principe est là, et il nous a semblé qu’il pouvait être intéressant de le proposer au-delà du contexte du CR PACA/Nice. C’est pourquoi nous l’avons également développé sous la forme d’une extension pour le navigateur Firefox téléchargeable sur le Marketplace des Add-ons Firefox ici https://addons.mozilla.org/fr/firefox/addon/sudocfiliation/.
Une fois installée, l’extension interagit uniquement dans l’interface publique du Sudoc lorsqu’on affiche une notice de périodique. Un onglet « Afficher/masquer le graphe » s’ajoute au menu de navigation, qui permet de proposer dans l’interface publique du Sudoc le même type de graphe dynamique.
Concernant l’application, les prochaines étapes sont les suivantes :
- proposer un volet de visualisation lié à la qualité des données de signalement, en jointant l’accès par corpus à la visualisation sur la qualité de ces groupes de notices (sur ce modèle mais en plus abouti)
- proposer des fonctionnalités d’export de lots de notices (donc probablement ajouter un module d’authentification)
- développer la partie liée au corpus presse locale ancienne, et représenter les jointures entre les 2 corpus
Le point technique
- réalisée avec le framework Angular
- Environnement Node.js
- créée avec le générateur d’application Yeoman
- utilise Grunt en task runner
- graphe réalisé avec la librairie vis.js
Une fois finalisé, le code source de l’appli sera évidemment disponible sur Github.
Le code source de l’extension pour Firefox est ici.
Enrichir et faire parler les données du CR (2/5) : focus sur les unicas
Il y a 8 ans
par Géraldine Geoffroy
dans Trucs & Astuces
Les unicas sont des titres (de périodiques dans le contexte du Sudoc-PS) qui ne sont détenus que par une seule bibliothèque du réseau Sudoc. Bien évidemment le signalement et la conservation de cette frange de notre patrimoine éditorial revêt une importance toute particulière.
Au-delà du signalement, la visualisation apporte également des possibilités de valorisation, et c’est tout l’objet de ce billet un peu technique que de proposer une solution d’extraction de données et de visualisation, tout en restant dans un environnement largement connu et utilisé : Excel.
Première étape : les sources de données
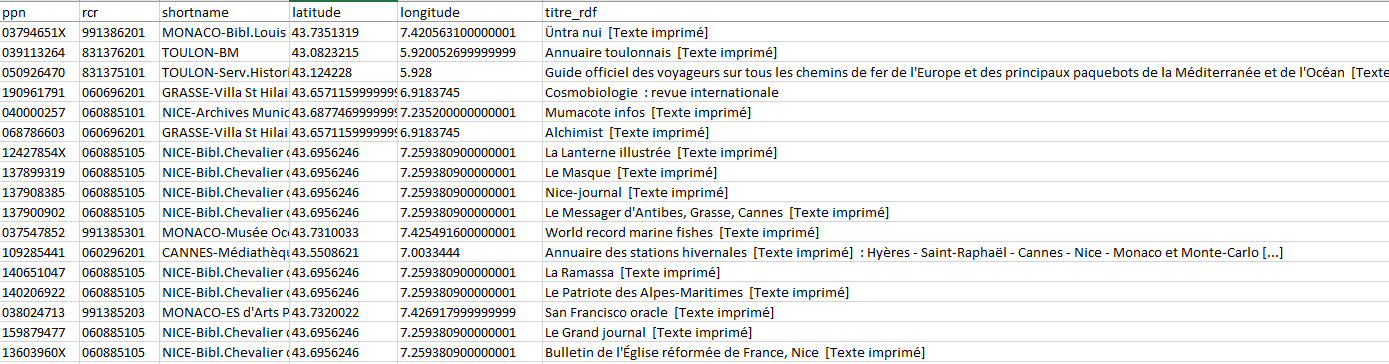
Via les services en ligne et en libre service Self Sudoc mis en place par l’Abes, chaque Centre Régional Sudoc-PS peut récupérer la liste des ppn (= l’identifiant unique d’une notice bibliographique dans le catalogue Sudoc.fr) des unicas de ressources continues détenus par les bibliothèques de son périmètre. Le fichier de ppn extraits est un fichier brut du type :
039113582
037935526
040303241
040160297
039004864…
Des ppn, c’est peu en terme d’information, et cependant c’est beaucoup puisqu’on peut ensuite choisir dans l’ensemble des web services développés autour de l’environnement Sudoc au sens large pour enrichir ces ppn avec des informations supplémentaires. Ce qui nous intéresse ici c’est par exemple d’extraire des données de localisation (quelle bibliothèque possède tel titre ?) et bibliographiques (de quelle ressource s’agit-il ?).
Deuxième étape : l’extraction de données
Pour obtenir la localisation des unicas dans notre réseau nous utilisons le web service multiwhere. Celui-ci renvoie le nom de l’établissement (RCR) localisé sous la notice interrogée via son ppn, ainsi que quelques éléments de la notice RCR : le nom court de l’établissement et ses données de géolocalisation (latitude-longitude). La requête se construit ainsi : url racine « http://www.sudoc.fr/services/multiwhere/ » + ppn (par exemple https://www.sudoc.fr/services/multiwhere/040269302) et renvoie par défaut dans le navigateur un résultat sérialisé en xml :
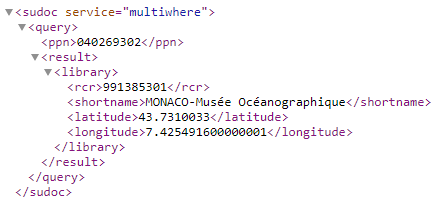
La petite complication tient à la connaissance nécessaire du langage xpath pour pouvoir naviguer dans ce flux xml et en extraire les portions souhaitées, à savoir le nom de la bibliothèque dans la balise <shortname> et ses coordonnées géographiques dans les balises <latitude> et <longitude>. Par exemple pour le nom court, en xpath et à partir de la balise racine <sudoc>, le chemin de localisation s’écrira */query/result/library/shortname.
En ce qui concerne les données bibliographiques, nous nous appuyons sur l’accessibilité des données du Sudoc sur le Web de données, notamment grâce à la fourniture d’url pérennes construites sur les ppn et la modélisation des données en RDF, atteignables sur le web en ajoutant l’extension .rdf à l’url pérenne. Toujours formalisée en xml, voici par exemple la notice en RDF du titre The Quarterly report of the Inter-America Tuna Commission obtenue avec l’url http://www.sudoc.fr/040269302.rdf

(On notera au passage que l’exposition et la ré-utilisation des données selon les standards du Linked Open Data (données ouvertes et liées) s’arrête aux droits de propriétés d’ISSN sur les notices de périodiques.)
De la même manière, on atteint l’information de titre dans la balise <dc:title> avec le chemin complet rdf:RDF/bibo:Periodical/dc:title (l’impasse est volontairement faite sur les considérations de préfixes et de namespaces qui sont à prendre en compte avec des langages tels que le xslt ou php mais qui « magiquement » disparaissent avec l’interrogation d’API sous Excel).
A noter à propos d’Excel : depuis Office 2013 Excel intègre un nouveau type de formules, dites « formules Web », qui permettent précisément de consommer des API (formule SERVICEWEB) et d’extraire du contenu du flux de résultat (formule FILTRE.XML). Ainsi :
- =SERVICEWEB(« http://www.sudoc.fr/services/multiwhere/093354320 ») injecte dans une cellule le contenu en xml de l’url http://www.sudoc.fr/services/multiwhere/093354320, ou =SERVICEWEB(« http://www.sudoc.fr/services/multiwhere/ »&A2) si le ppn est dans la cellule A2
- =FILTRE.XML(SERVICEWEB(« http://www.sudoc.fr/services/multiwhere/ »&A2); »//query/result/library/shortname ») ouvre l’url http://www.sudoc.fr/services/multiwhere/093354320 et « navigue » jusqu’à la balise <shortname>
- =TEXTE(FILTRE.XML(SERVICEWEB(« http://www.sudoc.fr/services/multiwhere/ »&A2); »//query/result/library/shortname »); »000000000″) complète tout ça en assignant un format texte à 9 caractères au ppn (pour éviter les très irritants problèmes de 0 en début de chaine).
Notons également qu’une des limites à l’utilisation d’Excel dans ce cas de figure réside dans la non-gestion des boucles (par exemple avoir à récupérer tous les RCR localisés sous un ppn en une seule boucle), problème qui par définition ne se pose pas dans le contexte des unicas.
Similairement la formule =FILTRE.XML(SERVICEWEB(« http://www.sudoc.fr/ »&A2& ».rdf »); »//bibo:Periodical/dc:title ») permettra de récupérer l’élément titre de la notice en rdf.
Pour finir on peut donc relativement facilement se construire une feuille Excel qui automatise l’extraction des données sur la base d’une liste de ppn, et vous trouverez ici en téléchargement un modèle de fichier prêt à l’emploi avec les formules pré-rentrées :
Troisième étape : la visualisation avec Power Map
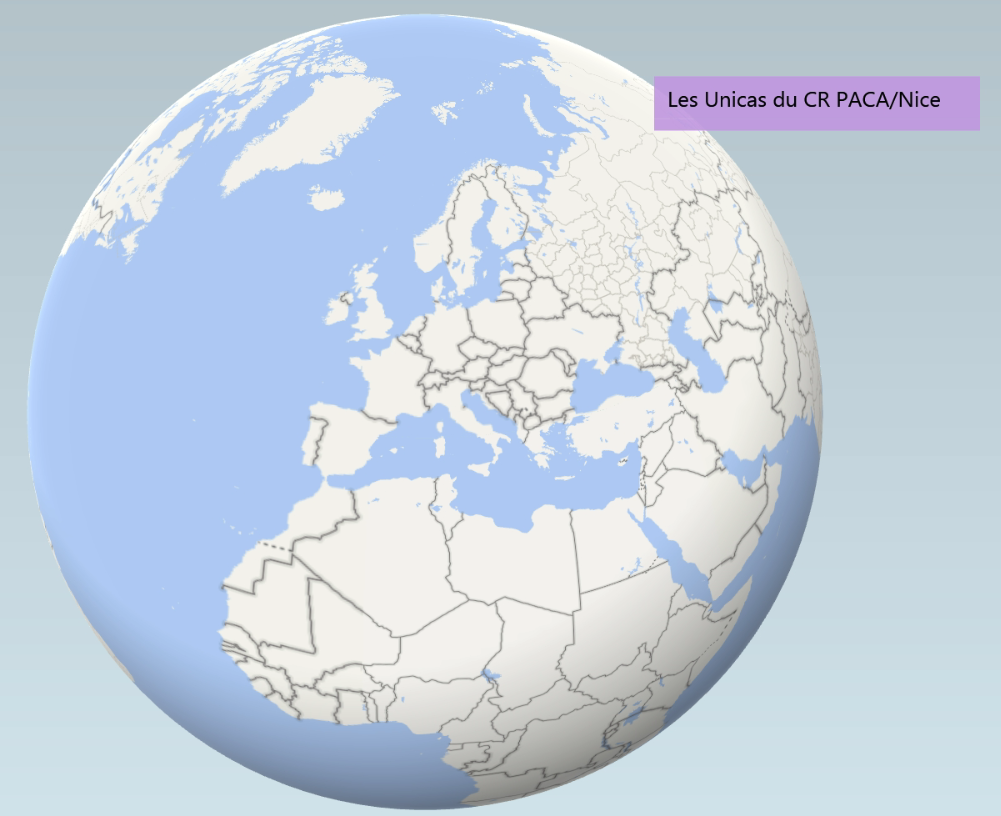
Power Map est un complément d’Excel qui se télécharge puis s’active manuellement, pour permettre de cartographier des données en 3D.
Il existe quelques tutoriels sur internet relatifs à l’installation et la prise en main. En voici un parmi d’autres, en français : https://www.excel-exercice.com/powermap/
Sans s’étendre sur cet outil, il est en tout cas assez pratique pour réaliser facilement des petites animations autour de données géolocalisées. En voici un exemple grâce aux données sur les unicas du Centre Régional PACA/Nice obtenues comme expliqué précédemment (cliquez sur l’image) :
Quatrième étape : le petit plus
Mais sortons des logiciels propriétaires : il est intéressant aussi de tenter d’exploiter le fichier Excel obtenu dans une visualisation interactive plus orientée web, en recourant à quelques unes des multiples librairies libres et open source existantes. En voici un exemple réalisé avec le framework Angular pour le binding de données et l’APi Google map pour la carte.
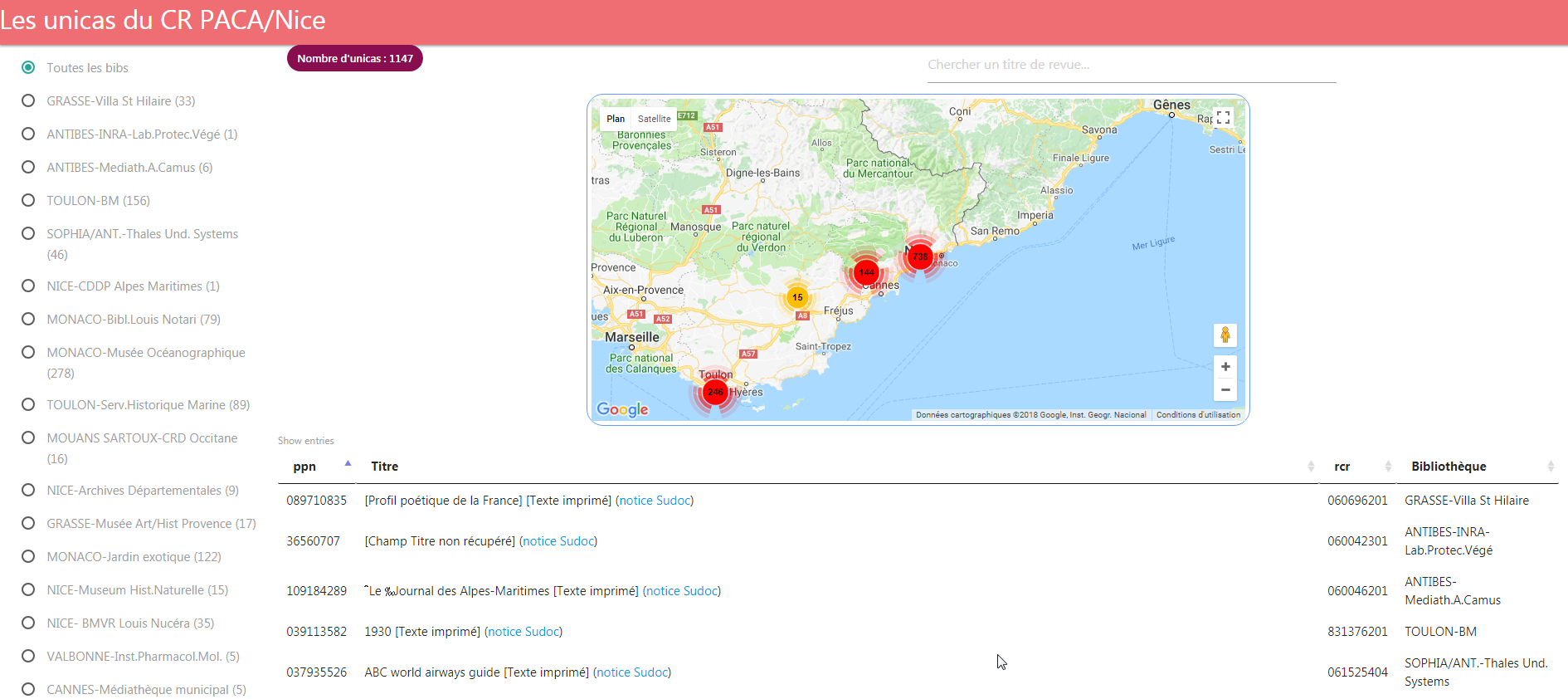
Pour ré-utiliser cette page web avec vos données (et/ou voir le code source pour les curieux), aucun problème : vous trouverez toute la documentation et les fichiers sur Github ici.
Mission : enrichir et faire parler les données du CR (1/5)
Il y a 8 ans
Ce billet, introductif d’une série d’autres billets sur le sujet, vise à développer un des projets présenté dans la Convention sur objectifs 2018-2020 du Centre Régional Sudoc-PS Paca/Nice (CR).
Ce projet comprend la création de deux interfaces web :
* une interface publique destinée à présenter, visualiser, interroger (voire éditorialiser) les données des bibliothèques du CR.
* une interface à usage interne centrée sur la qualité des données dans une optique d’outil de pilotage et d’amélioration.
Au stade où nous en sommes, celui de la formalisation des besoins et de la spécification des fonctionnalités attendues, les contours du projet génèrent encore beaucoup de questions et de tâtonnements. C’est justement l’objectif de cette série de billets que de partager nos réflexions, tests, méthodes de travail, choix d’outils, calendriers, ratés… Toutes les étapes qui rythment le cycle de vie d’un projet.
Concernant le travail sur la qualité des données, l’idée est de se doter d’un tableau de bord de type web qui aura les caractéristiques suivantes :
* reproductibilité : mise à disposition du CR d’une page web dotée d’un formulaire d’injection d’une liste de ppn qui génère un tableau de résultats à la volée.
* interrogation en temps réel des notices du catalogue national Sudoc.
* informations synthétisées sur les critères de qualité retenus en amont par l’équipe (par exemple présence ou non d’un ISSN) et production de listes de titres servant de base de travail pour les corrections.
En résumé, un service de type AlgoSudoc personnalisé et adapté aux notices de périodiques. Techniquement parlant et à ce stade, les choix liés aux types de langages, environnements ou frameworks, ne sont pas arrêtés. Cependant cette partie du projet n’est pas la plus ambitieuse et ne nécessite pas forcément beaucoup de moyens. Voici par exemple une page html (en mode prototype bien sûr) que l’on peut produire avec une simple feuille de style xsl appliquée à une liste de 1000 ppn formatée en xml :
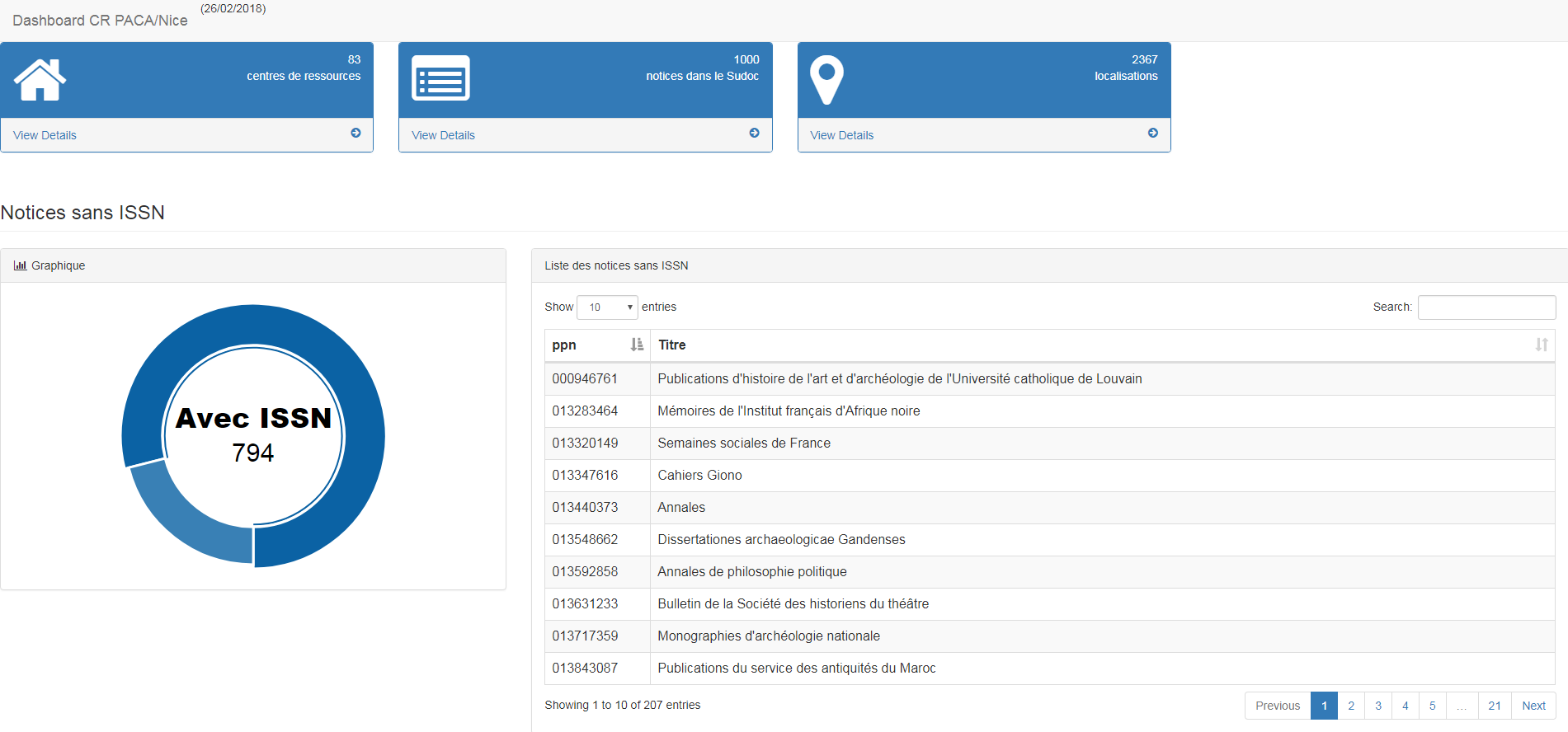
(librairie javascript utilisée pour les graphiques : morris.js)
En revanche le deuxième volet du projet s’annonce plus complexe, puisqu’il s’agit de proposer :
- une interface de visualisation (= de la dataviz),
- dotée d’un moteur de recherche (= de l’indexation),
- plutôt attractive (= du framework web),
- qui rende visible sur le web les données qu’elle intègre (= des données embarquées dans les pages web, s’appuyant sur du RDFa notamment), à l’instar, n’ayons peur de rien, de ce que propose data.bnf
- tout en proposant un type de navigation exploratoire (= de la modélisation en graphe, ou du moins une structuration de données autorisant un parcours de type graphe)
- donc par conséquent, s’appuyant sur des données modélisées selon le modèle LRM et les standards du web de données.
- sans oublier bien sûr de se raccrocher aux deux autres objectifs du CR : la valorisation des unicas et de la presse locale
Si on essaie d’articuler l’ensemble de ces éléments, certaines interrogations se posent d’emblée :
- quel périmètre de données ? Notre réflexe naturel est bien sûr de se concentrer sur les données bibliographiques, mais il y a un fort intérêt à également pousser au même niveau les données locales sur les exemplaires ainsi que les données sur les bibliothèques (= les notices RCR), notamment si l’on considère que le réseau du CR, par nature très hétérogène, comprend aussi des structures de tailles et moyens modestes qui ne sont pas dotées de site web et pour lesquelles une telle interface assurerait une présence et une indexation sur le web.
- quelles sources utiliser pour ces données (Sudoc, ISSN, databnf…), notamment en fonction des récentes évolutions du portail ISSN et des modalités d’exposition des données proposées par ISSN ?
- quel workflow peut-on mettre en place : extraction dynamique ou base de données avec mise à jour ? Et dans le cas de mises à jour, avec quelle fréquence ?
- quelle modélisation opérer, sachant qu’autant FRBR que LRM sont beaucoup moins opérants sur les publications en série que sur les monographies ?
- quelle interface côté utilisateur ? Du « fait maison », du framework web léger, du logiciel open source ?
- quelle articulation avec l’animation de réseau du CR : dans l’idéal le mode collaboratif est bien sûr plutôt envisagé, mais comment le mettre en œuvre ?
En résumé : un vaste et beau chantier devant nous !
Quoi qu’il en soit, pour illustrer notre propos lors de la présentation du projet à la dernière Journée du Centre Régional (Grasse, nov 2017), nous avons opté pour une visualisation expérimentale avec le logiciel Omeka (dans un usage quelque peu détourné de sa fonction principale d’outil de bibliothèque numérique), qui fournit d’ores et déjà une piste intéressante… A suivre !