Sudoc-PS
Centre du Réseau Sudoc-PS PACA/Nice
La dernière journée du réseau Sudoc-PS PACA/Nice a eu lieu le mardi 18 novembre 2025, au Musée International d’Art Naïf Anatole Jakovsky. Elle a réuni l’équipe Sudoc-PS, la direction de la DiBSO d’Université Côte d’Azur et une quarantaine de participants – un pour chaque année d’existence du réseau !

Journée Sudoc-PS 2025
L’introduction de la journée par Sarah Hurter-Savie (directrice de la DiBSO d’Université Côte d’Azur), ainsi que les actualités du Centre régional présentées par Emmanuelle Rauzy (responsable du Centre régional), ont été l’occasion d’échanger sur la fin du Sudoc-PS.
Pour les bibliothèques municipales, de laboratoires, de musée, d’écoles étrangères, de centres d’archives ou de documentation…, un nouveau dispositif de signalement des périodiques dans le Sudoc débute au premier janvier 2026. La description exhaustive des collections est remplacée par la participation de certains titres à des plans de conservation partagée des périodiques :
Le support détaillé de présentation de ces changements est disponible sur cette page. Vous pouvez également consulter cette publication de l’ABES, qui détaille les impacts de ces changements pour les bibliothèques.
Après une démonstration de l’outil Colodus pour les collègues intéressés, la suite de la journée a été consacrée à la (re)découverte du Musée d’Art Naïf. L’équipe nous a présenté le Projet Scientifique et Culturel de l’établissement. Nous avons ensuite visité la nouvelle exposition « Mondes Parallèles », qui fait dialoguer les collections du musée avec celles du MAMAC. Pour les amateurs de Niki de Saint-Phalle, Séraphine de Senlis, Eva Lallement…, l’exposition est visible jusqu’au 31 mars 2026.

Exposition « Mondes parallèles »
Nous avons eu la chance de passer l’après-midi dans les coulisses du musée : Olivier Ghiringhelli nous a présenté la nouvelle muséographie, qui doit beaucoup à l’artiste Ben. Charlotte Congard nous a permis de découvrir les réserves. Et Frédérique Olivier-Ghauri nous a fait découvrir le Centre de Documentation du musée, et exposé quelques pièces du fonds Anatole Jakovsky (dont les cartes de voeux annuelles envoyées par le couple Jakovsky). Nous avons également eu droit à un aperçu de la future résidence d’artiste du Musée.
Nous remercions l’équipe du Musée d’Art Naïf de nous avoir accueilli pour cette dernière journée, ainsi que notre responsable Emmanuelle Rauzy, qui a porté le réseau Sudoc-PS depuis ses débuts. Un grand merci également à tous les participants à cette dernière journée !

Le Musée d’Art Naïf de Nice, n.d. / Roger BOISSIER.
Crédit photo : Ville de Nice – Muriel Anssens
L’équipe du Sudoc-PS organise actuellement la 11ème et dernière journée du réseau, tel qu’il existe actuellement.
Cette journée aura lieu le mardi 18 novembre 2025 de 9h à 16h au Musée International d’Art Naïf Anatole Jakovsky de Nice.
Nous vous espérons nombreux à y participer !
Le formulaire d’inscription est disponible en ligne jusqu’au 15 octobre.
Merci aux collègues du Musée pour leur accueil ; découvrez sur ce billet de blog le compte-rendu de notre visite de 2022 au Musée.
Programme de la journée :
9h : Accueil café/viennoiseries
9h30 :
Introduction de la journée
(Sarah Hurter-Savie, directrice de la DiBSO d’Université Côte d’Azur)
9h45 :
Actualités du Centre régional Sudoc-PS
(Emmanuelle Rauzy, responsable du Centre Régional)
10h15 :
Présentation du Projet Scientifique et Culturel (P.S.C.) du Musée International d’Art Naïf Anatole Jakovsky
(Olivier Ghiringhelli, adjoint de la directrice du Musée ; Charlotte Congard, chargée des collections du Musée)
10h50 : Pause café
11h15 :
Atelier au choix :
– Démonstration de Colodus
– Visite de l’exposition « Mondes Parallèles » (les collections du Musée entrent en dialogue avec celles du MAMAC)
(Marie-Laëtitia Antonio, médiatrice culturelle au Musée)
12h : Pause déjeuner (buffet offert)
14h-16h :
Trois visites simultanées de 40 minutes, en petits groupes. Chaque participant.e pourra participer aux trois visites :
– Visite des réserves du Musée International d’Art Naïf Anatole Jakovsky
(Charlotte Congard, chargée des collections au Musée)
– Visite de la nouvelle muséographie du Musée
(Marie-Laëtitia Antonio, médiatrice culturelle au Musée)
– Visite du centre de documentation et de la résidence d’artiste du Musée
(Frédérique Olivier-Ghauri, directrice du Musée)
16h : Fin de la journée
N’hésitez pas à nous contacter à l’adresse mail sudoc-ps.paca-nice@univ-cotedazur.fr pour toute question.
Lors de la révision des inventaires de la bibliothèque du Chevalier de Cessole, nous avons trouvé dans un tiroir des numéros de la revue Les Procédés Modernes d’Illustration et les Industries qui s’y rattachent, en excellent état. Certains numéros n’avaient jamais été ouverts, des pages étaient encore scellées avec des coupons d’abonnement à l’intérieur.

Numéros de Procédés modernes d’illustration et les industries qui s’y rattachent
Cette revue professionnelle est produite par la SADAG (Société Anonymes Des Arts Graphiques), une entreprise suisse créée par l’alpiniste et photographe Frédéric Thévoz et son ami Louis Chauffat. À la pointe des techniques de procédés d’impression photomécaniques, la SADAG a eu, au pic de son activité, trois grandes usines à travers l’Europe. Elle produisait des catalogues et des affiches pour les musées d’Europe, des menus pour les grands restaurants, et imprimait des illustrations pour des monographies et des périodiques.

Page d’un numéro des Procédés modernes d’illustration et les industries qui s’y rattachent
Stoppée dans les années 1930 avec la crise économique, elle multiplie les fusions, réduit son activité et existe encore aujourd’hui sous le nom d’Atar Roto Presse. Elle publie depuis 2000 le journal Le Courrier.
La revue rend compte des dernières avancées techniques et des productions de l’entreprise, à destination de clients potentiels ou fidèles. Jusqu’à sa cinquième année de parution, les couvertures changent à chaque numéro avec un style esthétique très différent, pouvant aller de la reproduction d’aquarelle à un effet « papier froissé » tout à fait bluffant. Nous pouvons trouver à l’intérieur des numéros des exploits techniques, comme cette double page avec une reproduction fidèle d’un vitrail d’église.

Pages de numéros de Procédés modernes d’illustration et les industries qui s’y rattachent
Vous pouvez consulter cette revue à la bibliothèque du Chevalier de Cessole.
Membres du réseau, n’hésitez pas à faire part de vos périodiques remarquables pour que nous les mettions en avant : écrivez-nous à sudoc-ps.paca-nice@univ-cotedazur.fr.

[Sans titre] / by De_mi_voz_voces (Pixabay, [CC0 Content])
Les objectifs de notre Centre Sudoc-PS PACA/Nice sont fixés dans la convention qui nous relie à l’ABES : nous avons rédigé un rapport d’activité pour l’année 2023, pour présenter les réalisations notables de l’année.
Pour notre objectif de valorisation des collections :
Nous avons amélioré 80% des notices d’unicas du réseau, et intégré dans le Sudoc les collections de l’Écomusée du Pays de la Roudoule, ainsi qu’un don conséquent de la bibliothèque du Chevalier de Cessole.
Des collections ont également été mises à jour, notamment aux Archives municipales de Nice, suite à un chantier de recotation.
Quant au nombre de demandes de numérotations ISSN, il a presque doublé depuis 2022.
Pour notre objectif d’animation du réseau :
Nous avons formé les membres du réseau à Colodus en nous rendant sur site, en invitant les collègues à des ateliers, et en proposant des visioconférences.
Nous nous sommes également rencontrés grâce à quatre déplacements sur site, entre autre au Centre de documentation du musée Terra Amata et à la bibliothèque du CEPAM ; avant de tous nous retrouver pour la 9ème journée annuelle du réseau à la Bibliothèque Lettres Art Sciences humaines d’Henri Bosco (Université Nice Côte d’Azur) puis aux Archives Nice Côte d’Azur.
Nous observons également une augmentation des visites virtuelles sur notre blog : plus de 3500 vues en 2023 pour 2300 en 2022.
> Nous sommes ravis de cette riche année 2023, et vous invitons à consulter le rapport d’activité complet.
Après le suicide tragique de l’artiste Ben Vautier le 5 juin dernier, peu de temps après la mort de sa femme Annie Vautier, les hommages à travers le pays et de la part du monde de l’art ont remis en lumière son travail. C’est ainsi qu’à la Bibliothèque du Chevalier de Cessole, à la demande d’un lecteur, a été sorti des magasins la revue boite aux lettres, compilation des newsletters accessibles sur le site internet de Ben, elles-mêmes des compilations de petites notes faite de manière impulsive, accompagnées de dessins et écritures inédites. Comme à son habitude Ben y laisse libre cours à toutes les réflexions qui traversent son esprit, de la plus futile à la plus intéressante. Il y commente aussi l’actualité culturelle locale, ou encore répond à certains des courriers qu’il recevait chez lui. Cette revue est une manière de conserver de manière pérenne une partie du contenu de site de Ben.

Boite aux lettres n°10 juin 2022_Ben
Véritable objet de patrimoine numérique qui ne peut exister que sous cette forme, le site internet de Ben est un espace chaotique et vivant où l’internaute se perd, étourdi par tant d’éléments à l’écran. Rejetant les conventions esthétiques et techniques attendues d’un site web, la plupart des pages sont des blocs de textes, mais nous pouvons trouver également un enregistrement du répondeur téléphonique de l’artiste, des dessins cachés et autres fantaisies. Certaines pages ne sont déjà plus disponibles car les noms de domaines ont expiré, et il est légitime de se poser la question de la conservation de ce site à l’avenir maintenant que l’artiste est décédé.

Copie d’écran site web ben-vautier.com
Sans doute ce site fait-il partie des 4 millions de sites et 2 milliards de pages web que la BnF collecte et archive par le dépôt légal numérique chaque année. En effet, la BnF les collecte de manière automatique, à l’aide d’un robot qui détecte les sites hébergés en France. Compte tenu du nombre massif de sites ayant une adresse numérique française la BNF ne vise pas l’exhaustivité dans son procédé d’archivage, mais elle effectue une curation qui tend vers la meilleure représentativité possible de l’internet français.
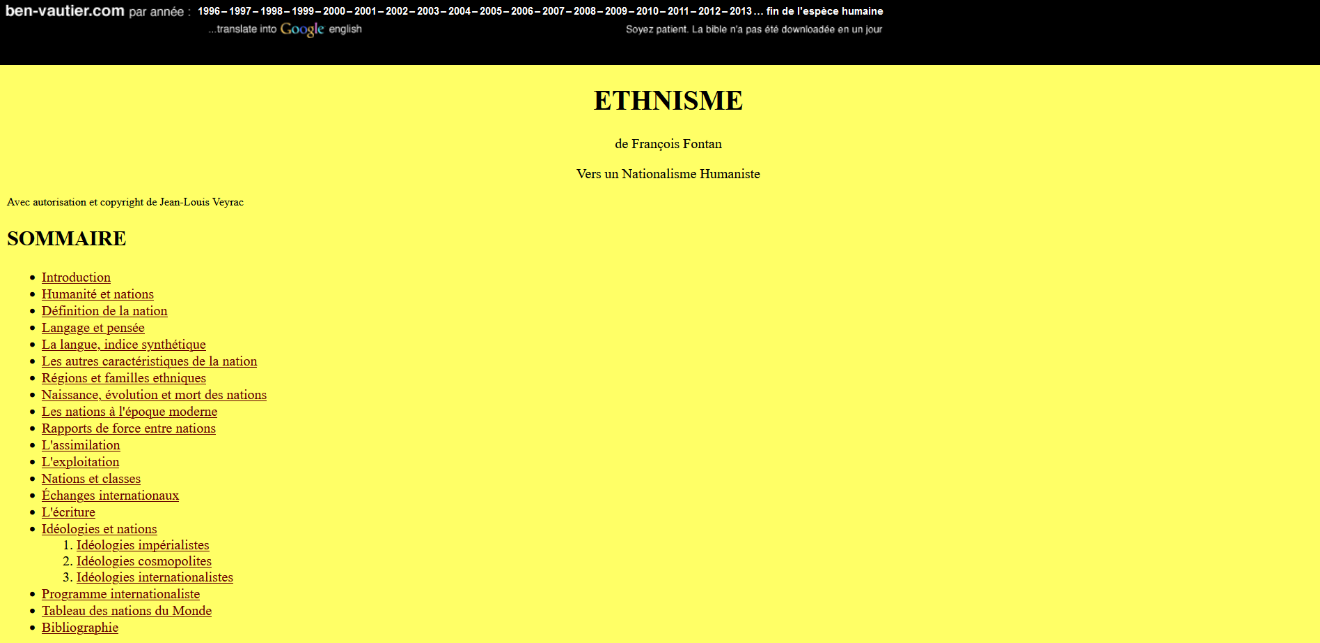
Copie d’écran site web ben-vautier.com
Le magazine de Ben « boite aux lettres » est disponible à la Bibliothèque du Chevalier de Cessole et à la Bibliothèque Romain Gary à Nice.
Membres du réseau, n’hésitez pas à nous signaler vos périodiques remarquables pour que nous les mettions en avant : écrivez-nous à sudoc-ps.paca-nice@univ-cotedazur.fr

10e Journée Sudoc-PS CR Paca/Nice
La 10e Rencontre annuelle du Centre du Réseau Sudoc-PS PACA/Nice s’est déroulée le lundi 10 juin 2024 au Musée d’Anthropologie préhistorique de Monaco.
Le matin, après une introduction par Sarah Hurter-Savie, directrice du SCD d’Université Côte d’Azur, Elena Rossoni-Notter, directeur du Musée, et son équipe nous ont présenté leur établissement, son histoire et ses activités. (support de la présentation ici)
Ce musée, le plus ancien de Monaco (fondé en 1902), possède une documentation scientifique considérée comme de la recherche archéologique à part entière. Les publications scientifiques du musée étant aussi anciennes que le musée lui-même, elles sont également précieuses pour l’histoire des sciences. Le musée participe a un réseau international d’échanges de publications. Quiconque souhaite recevoir/échanger le Bulletin du musée ou ses autres publications peut prendre contact.
Dans un 2e temps Fanny Clerissi, responsable du Dépôt légal de la Principauté de Monaco, et Flore Bugnicourt, responsable du fonds précieux, ont présenté les spécificités et l’actualité de la Médiathèque de Monaco (support de la présentation en pdf ici). Cet établissement déménagera prochainement dans de nouveaux locaux de 2000 m2 au sein d’un grand complexe monégasque en construction, l’îlot Pasteur (vidéo de présentation sur YouTube), dont l’ouverture est prévue en 2025.
Pour clore la matinée, la parole était au Centre régional Sudoc-PS Paca/Nice :
– Emmanuelle Rauzy, responsable du CR, a présenté un bilan et les perspectives des activités du CR (support en pdf ici). On notera notamment les perspectives de profonde évolution des activités du Centre régional à la faveur de la prochaine convention avec l’Abes, bien que de nombreuses incertitudes subsistent pour l’instant.
– Benjamin Person a présenté un bilan de son travail sur l’amélioration du signalement des périodiques du réseau (support en pdf ici).
L’après-midi tous les participants ont pu bénéficier de 5 courtes visites préparées par toute l’équipe du Musée : présentation de la bibliothèque du Musée, de l’atelier de restauration, de l’exposition temporaire Monaco d’autrefois, de Jean-Pierre Debernardi, sur la terrasse panoramique (des photographies inédites datant du début du XXe siècle), de l’exposition Lascaux à Monaco qui présente de véritables pièces archéologiques prêtées par Lascaux, et la « visite guidée » de la grotte de Lascaux grâce à un casque de réalité virtuelle. Si vous ne l’avez pas vue, ne manquez pas cette exposition passionnante présentée jusqu’au 21 novembre 2024 !
Tous nos remerciements à l’ensemble de l’équipe du Musée d’Anthropologie préhistorique de Monaco pour leur accueil chaleureux, ainsi qu’à tou·te·s les intervenant·e·s et guides pour cette belle journée instructive.

Mapmc [CC BY-SA 4.0], from Wikimedia Commons
Ce jour-là nous serons accueillis par la Bibliothèque du Musée d’Anthropologie préhistorique de Monaco.
Afin de préparer au mieux cette journée merci d’enregistrer votre inscription via ce lien avant le 26 mai.
Programme de la journée
9h30 : accueil café/viennoiseries
10h : Introduction et annonce du programme de la journée (Sarah Hurter-Savie, directrice du SCD d’Université Côte d’Azur)
10h15 : Intervention du Musée d’Anthropologie préhistorique de Monaco (Elena Rossoni-Notter, Directeur du Musée d’Anthropologie préhistorique de Monaco, Olivier Notter et Jérôme Magail, Chargés de Recherches) : Présentation générale du Musée-institut de Recherches, l’axe « fouilles, recherches et documentation scientifique », l’axe « bibliothèque spécialisée-inventaire/numérisation »
10h45 : Intervention de la Médiathèque de Monaco (Flore Bugnicourt, responsable du fonds précieux, Nicolas Reclus, référent pour la presse du fonds régional, Fanny Clerissi, responsable du Dépôt légal de la Principauté de Monaco) : Présentation des collections patrimoniales, du fonds régional, du portail dédié au patrimoine de la Médiathèque de Monaco
11h15 : pause café
11h40 : actualités du réseau Sudoc-PS (Emmanuelle Rauzy) et bilan du travail local sur les unica et la presse ancienne par le CR Sudoc-PS (Benjamin Person)
12h : pause déjeuner, buffet offert
14h : début des visites en petits groupes. Chaque groupe bénéficiera d’une visite privilégiée de l’exposition Lascaux à Monaco, de l’exposition en terrasse sur les photographies d’antan, ainsi que du Laboratoire de recherches habituellement fermé au public (collections archéologiques, documentation scientifique, bibliothèque spécialisée, et atelier de restauration). Visites guidées par M. Moussous, Chargé de Médiation scientifique, Mme Huber, Guide-interprète, Mme Ampilhac, Agent guide, M. Burle, Commis-archiviste.
16h : fin de la journée
Comment venir ?
Le Musée d’Anthropologie préhistorique est situé juste à côté du Jardin exotique de Monaco.
Privilégiez les transports en commun :
En bus : par exemple le bus 602 depuis Nice, arrêt « Jardin exotique ».
En train : Gare Monaco Monte-Carlo, puis une vingtaine de minutes à pied jusqu’au Musée, ou un bus depuis la Gare (par exemple le 602), arrêt Villa Paloma.
Site des autobus de Monaco : https://www.cam.mc/
En voiture : parkings payants dans Monaco, par exemple celui du Jardin exotique de Monaco, ou encore L’Engelin, tous les deux à 5 minutes à pied.

Collections numérisées BSNum
Basée sur le logiciel Omeka S, la bibliothèque numérique patrimoniale BSNum donne accès à plus de 1400 documents , répartis en 4 collections principales :
1) Les films de la Cinémathèque Centrale de l’Enseignement public : un fonds de 2500 films, principalement documentaires et pédagogiques, réalisés entre 1920 et 1989 pour être diffusés de la maternelle à l’université. Plus de 1100 films ont actuellement été numérisés. Il s’agit principalement de films de courts-métrages sur des thèmes très variés. 2 sous-collections valorisent plus spécifiquement des films médicaux (Medfilm) ainsi qu’un corpus spécifique s’intéressant à la période coloniale et décoloniale (CCEP Kinopedia).
2) La collection italienne d’une centaine de monographies imprimées du XVIe au XXIe siècle, la plupart en langue italienne, issues des fonds rares et anciens de l’ancienne bibliothèque d’italien de l’Université Sorbonne Nouvelle. Leur numérisation s’inscrit dans le projet Fonte Gaia.
3) Une collection rare d’une trentaine de lithographies de la fin du 19ème siècle du monde Arabe, d’auteurs de corpus doctrinaux chiites.
4) Les monographies et revues de l’Institut des Hautes Études de l’Amérique Latine.
Voir ici pour exemple la fiche descriptive et l’accès à un document numérisé
En 2024 la collection va s’accroitre et de nouvelles fonctionnalités seront disponibles, dont la recherche plein texte et l’interopérabilité des images. A l’exception de certains films de la CCEP, les documents numérisés sont en accès ouvert à tous (il peut être nécessaire de se créer un compte visiteur). De nombreux documents appartiennent au domaine public est peuvent être réutilisés sous conditions. Une partie des collections numérisées est aussi référencée dans Gallica, la bibliothèque numérique de la BnF.
Bonne exploration !
Dans ce billet nous présentons 3 revues d’art éditées à Nice. Ce type de publication reproduit et assemble des créations artistiques, inédites ou reproduites, et sert de médiation entre artistes, et entre les artistes et le public. Il permet de créer du discours sur la culture et sa diffusion, et sur l’art en lui-même. Les revues choisies ici ont été publiées à 3 périodes différentes, et constituent un reflet des capacités éditrices de leur époque et des différents publics qu’elles visent.

Couvertures de L’Olivier
La première revue est L’Olivier, publiée entre 1912 et 1914. Il s’agit d’une publication indépendante de 10 numéros par année contenant des poèmes, des critiques d’art et des publications inédites de correspondances entre artistes. Bien qu’ayant une publication courte, l’équipe de L’Olivier s’est donné les moyens de produire pour chaque numéro 25 exemplaires spéciaux imprimés sur papier Japon, plus coûteux, plus épais, mais aussi pour notre intérêt plus faciles à conserver. L’objectif était d’en faire un bel objet, dans la mesure de leurs moyens et avec la limitation d’une impression exclusivement textuelle. Comme dans la majorité des revues d’art, la rédaction est composée d’artistes, comme l’auteur Bernard Barbery ou le peintre Paul Audra, mais également de personnes impliquées dans la politique culturelle locale comme Joseph Levrot qui fut rédacteur en chef de Nice Historique de 1909 à 1914 et ayant travaillé au sein des bibliothèques et des archives de la ville de Nice. L’Olivier est aujourd’hui conservé dans un grand nombre d’établissements (dont 6 du réseau PACA/Nice) et un numéro est consultable sur Gallica.

Page d’un numéro de Méditerranéa
La deuxième revue présentée a fait l’objet d’un article dans Les Cahiers de la Méditerranée par notre collègue Dominique Laredo. Il s’agit de Méditerranéa, publiée de 1927 à 1940. Une revue qui a eu pour objectif de légitimer une culture méditerranéenne en promouvant les artistes locaux, mais également en se faisant le relais d’expositions à travers le monde par des reproductions d’œuvres. On y retrouve, en plus des reproductions citées, des textes inédits mais également des illustrations originales qui en font un objet de grande valeur. Son impression de qualité (bien que monochromatique) lui a permis de se bâtir une solide réputation et avoir la reconnaissance et l’appui de certains députés. Il parait évident que cette revue initiée par Paul François Castéla, qui n’en était pas à son coup d’essai, a créé une certaine effervescence, un mouvement qui coexista avec la création du Centre Universitaire Méditerranéen inauguré en 1933. Au vu de son intérêt, elle est conservée dans un grand nombre d’établissements (dont 5 du réseau PACA/Nice), et elle a également pu bénéficier d’une grande opération de numérisation à la BMVR de Nice, qui nous a été présentée pendant la journée professionnelle du Sudoc-PS de 2019, elle est consultable sur la plateforme patrimoniale NICEA. Certains numéros sont également sur Gallica et un numéro spécial dans les Fonds Anciens de Grasse.

Première page d’un numéro d’Evidence
La dernière revue est un objet particulier. Là où les deux précédentes revues voulaient se rendre légitimes et donc avaient un certain standard d’édition, Evidence est un périodique qui se rapproche plus du fanzinat, artisanal dans sa conception. Avec son arrangement à base de collages accompagnés de dessins d’artistes et de poèmes, avec en son cœur un mini-magazine à plier soi-même dans chaque numéro. Son esthétique punk a une origine évidente : il est édité par Bramstocker Association, fondée par les membres du groupe punk niçois Bramstocker, composé originellement de Fréderic Vidal (le rédacteur en chef), Jean-Paul Albert, Christian Leblond, Jean-Luc Zerbib et Patrick Douillon. Evidence a pour vocation de parler à la jeunesse de Nice (tirages importants à bas prix) pour promouvoir l’activité culturelle locale et porter également des revendications de démocratisation de la culture. Publié uniquement de 1981 à 1982, ce périodique est conservé dans 3 établissements du réseau et ne possède pas encore de version numérisée.
N’hésitez pas à aller consulter ces titres dans les établissements du réseau les possédant ou bien à accéder à leur numérisation. Chaque type de périodique a son histoire, ses variations, et peut inspirer aux lecteurs une curiosité ou des idées de recherches dans leurs domaines scientifiques. Evidence met d’ailleurs en avant l’idée d’Initiative Culturelle : l’accès à la culture est nécessaire pour que d’autres s’en saisissent et la fassent vivre.

Mini-magazine pliable dans chaque numéro d’Evidence

Vue de face de l’Exprimante – un distributeur de presse ancienne. Photo Atelier Regards.
Souvenez-vous, il y a deux ans nous vous présentions L’Exprimante, le distributeur de presse ancienne créé par l’Agence Auvergne-Rhône-Alpes Livre et Lecture, qui utilise la base documentaire de Lectura +.
Depuis cet outil de médiation a circulé dans différents établissements de la région Auvergne-Rhône-Alpes. L’Agence Auvergne-Rhône-Alpes Livre et Lecture a profité de son rendez-vous numérique mensuel « Le 11/12 » de décembre 2023 pour inviter Guénaël Borg (responsable du fonds Auvergne de la Bibliothèque du patrimoine de la métropole Clermont Auvergne), et Myriam Ikhlef (technicienne formation, recherche, documentation, à l’Établissement public local d’enseignement et de formation professionnelle agricole de Cibeins) afin de faire un retour d’expérience du passage de l’Exprimante au sein de leurs établissements.
Au Lycée agricole de Cibeins à Mizérieux, les élèves ont pu découvrir l’Exprimante avec curiosité avec un atelier d’Éducation aux médias et à l’information sur le thème « 100 ans de faits divers » où ils ont pu comparer en groupes la différence de traitements de faits similaires dans le passé et aujourd’hui.
À la Bibliothèque du Patrimoine de la métropole Clermont Auvergne c’est autour d’un atelier sur le thème « Comprendre l’évolution de la presse d’actualité depuis 150 ans à travers ses impacts sur la société » que les lecteurs ont pu se familiariser avec cet outil, et l’adopter au point de venir obtenir leur sélection quotidienne d’articles si souvent que la Bibliothèque a dû se fournir en rouleaux à papier pour recharger la machine (pourtant prêtée par l’Agence pour une durée de 2 à 4 mois avec 5 rouleaux fournis !).
Les ressources de ces ateliers sont à retrouver en libre accès sur Lectura +, qui propose des fiches méthodologiques pour mettre en place des actions culturelles autour du patrimoine écrit.
L’Exprimante est un outil très modulable : pas besoin de grandes compétences informatiques pour changer les articles et images présents dans la machine ou modifier certains paramètres d’impression. L’équipe de la médiathèque Jean-Jacques Rousseau, dans le cadre de leur exposition « Pop’ : un siècle de littératures & lectures populaires », a préparé une sélection personnalisée de récits courts, poèmes et feuilletons présents dans les titres disponibles sur Lectura +.
Une expérience qui rappelle les distributeurs éphémères d’histoires courtes installés par la SNCF dans les grandes gares de France en 2016 et ayant marqué le public, pour certains, non lecteurs, ayant pris le temps de lire quelques minutes un texte inattendu.
L’Exprimante est un outil stimulant qui valorise un patrimoine écrit et visuel et qui permet une approche ludique de la lecture à travers une consommation courte, ponctuelle et immédiate. Elle produit aussi un souvenir matériel que l’on peut conserver et qui peut devenir un objet de discussion. C’est un outil qui gagnerait à se développer. Les retours ont montré que la machine remplit tous les objectifs fixés au début du projet.
Si l’Exprimante est disponible à l’emprunt uniquement pour des établissements de la région Auvergne-Rhône-Alpes, l’entièreté des plans, listes de composants et programmes pour la fabriquer sont disponibles sur le site de Lectura + sous licence Creative Commons CC BY-NC-SA. Peu onéreuse, il ne tient qu’aux collectivités de construire leur propre machine pour mettre en valeur leur patrimoine ou l’utiliser à des fins de médiation diverses, tant l’outil est modulable.