HTTBU
Le blog des BU sur les publications électroniques et les données de la recherche
Le blog HTTBU arrête son activité éditoriale à partir de septembre 2019. Nous avons pris cette décision suite à la refonte du site des BU qui permettra de réunir les sujets sur les ressources en ligne dans la partie Actualités. Nous vous attendons nombreux sur le site des BU de Nice bu.univ-cotedazur.fr.
Les informations relatives aux projets portés par les bibliothèques universitaires seront basculées dans le carnet Hypothèses fraîchement ouvert Doc d’Azur.
HTTBU restera cependant disponible pour consultation pendant encore une année.

Pendant tout le mois d’Octobre, vous pouvez consulter la bibliothèque numérique Dalloz (si vous n’êtes pas automatiquement reconnu comme « BU Nice », cliquez en haut à droite sur connexion).
Cette bibliothèque numérique contient plus de 1000 livres de l’éditeur feuilletables en ligne. Les nouveautés et nouvelles éditions sont disponibles dès leur parution. Les grandes collections sont accessibles :
 des
desDonnez nous votre avis sur cette ressource en répondant à ce court questionnaire.
Pour plus d’informations, vous pouvez écrire à docelec@unice.fr.
Bonne navigation.
A l’occasion du passage à une nouvelle version, modernisée et enrichie, de la base Frantext, nous vous proposons un focus sur cette base de données textuelle.
![]()
Tout d’abord, qu’est-ce que Frantext ?
Quelles nouveautés grâce à Frantext 2 ?
La version 2 de Frantext remplacera définitivement la 1ère version à partir du 30 juin. Pour vous aider à utiliser cette nouvelle version, une documentation est disponible ici.
Les BU de l’Université vous propose actuellement un test à la nouvelle version de CAS/SciFinder, intitulée SciFinder-n. L’éditeur CAS met en avant une amélioration sensible de l’ergonomie ainsi que l’intégration des bases MethodsNow sur la méthodologie et PatentPak sur les brevets pour justifier une hausse de prix conséquente.
Vous pouvez consulter cette ressource en local depuis les postes et le Wifi de l’Université mais aussi à distance depuis chez vous. Attention, cette base de données nécessite la création d’un compte au préalable avant de pouvoir bénéficier de son contenu. Si vous avez déjà utilisé SciFinder par le passé, vous n’avez rien à faire, il vous suffit pour SciFinder-n de saisir vos identifiants déjà créés.
Si ce n’est pas le cas, vous devez procéder à la création d’un compte sur la version classique de SciFinder, à cette adresse. Une fois votre compte créé, vous pourrez tester la nouvelle version librement (jusqu’au 10 juillet).
Pour toute demande de précision vous pouvez nous écrire à docelec@unice.fr.
Nous souhaitons recueillir vos avis sur cette nouvelle version, par le biais de cette enquête.
Merci pour votre participation, vos retours nous sont indispensables !
Réalité virtuelle, réalité augmentée, réalité mixte… autant de termes qui passent petit à petit dans le langage courant, autant d’applications pratiques de ces concepts qui sortent de la confidentialité et intègrent de plus en plus notre quotidien.
Or il se trouve qu’il en va de ces technologies comme de la plupart des outils de développement (web) en général : présentant à leur début, pour qui souhaite se les approprier, un ticket d’entrée technique assez conséquent (connaissance de langages informatiques « lourds » type Java ou C++, frameworks peu documentés, …), leur prise en main progressive par une communauté grandissante favorise la démocratisation de leur accessibilité, parfois même jusqu’à finalement intégrer les standards du web via de nouvelles API pour navigateurs spécifiées par le W3C (voir par exemple ce billet sur le blog du W3C à propos des modalités de prise en compte du « web immersif » dans les travaux du consortium).
Ce fut le cas pour le développement d’applications mobiles, avec au fil du temps la possibilité de développer des apps dites hybrides (en effet ce type d’applications se fondent sur des environnements web « classiques » encapsulés dans des webViews, et dont le comportement se rapproche de celui des apps natives). C’est aujourd’hui le cas aussi avec des frameworks de VR (réalité virtuelle) et AR (réalité augmentée) libres et/ou open source, et des navigateurs de plus en plus puissants gérant nativement le traitement de données de positions géographiques, d’images, de sons, etc…
Focus donc sur la réalité augmentée et deux exemples appliqués aux « nouveaux » types de services que les bibliothèques pourraient rendre avec ces technologies
… consiste à superposer des éléments virtuels à la réalité que nous percevons avec nos 5 sens, autrement dit à combiner en temps réel notre environnement habituel en 3D avec des données numériques virtualisées, si possible de manière interactive (l’utilisateur peut interagir avec cette sur-couche virtuelle) et contextualisée (les données qui apparaissent sont liées au contexte de l’environnement). Pour cela deux techniques permettent de lier le virtuel au réel : l’utilisation de données relatives à la position et aux mouvements de l’utilisateur (coordonnées GPS, accéléromètre, magnétomètre…) ou l’utilisation de la reconnaissance de formes pour la détection de « marqueurs ».
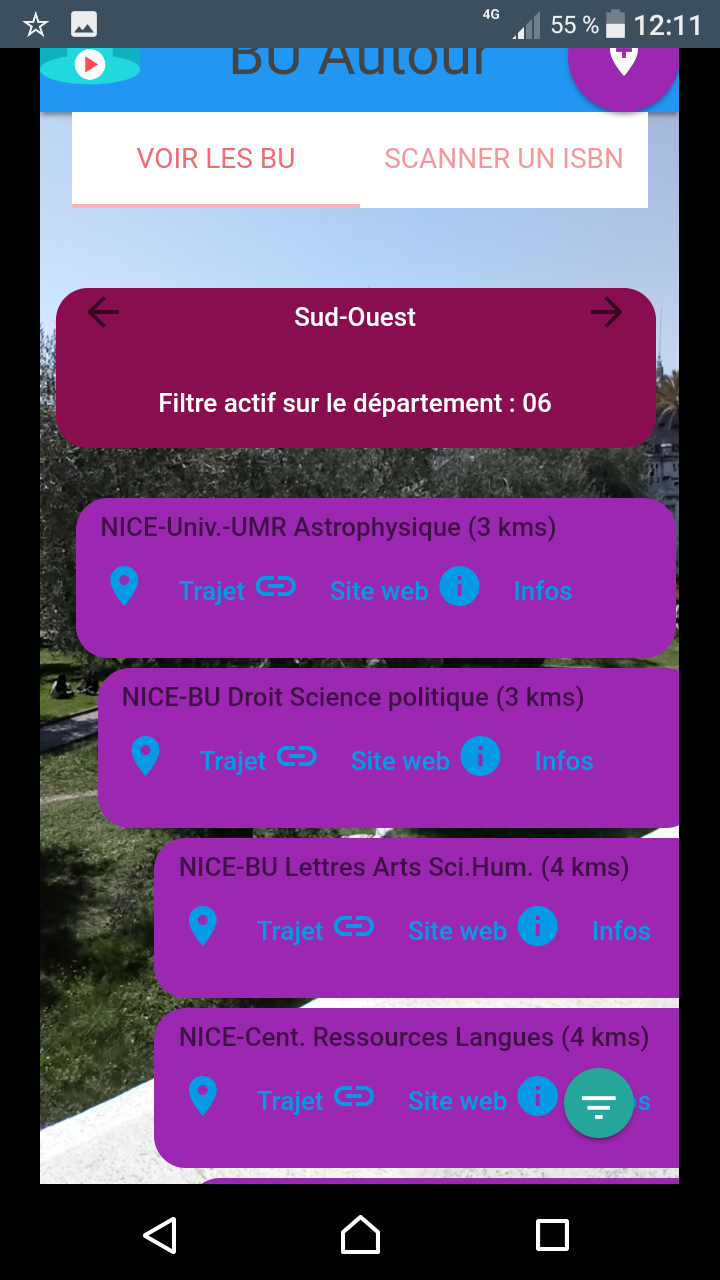
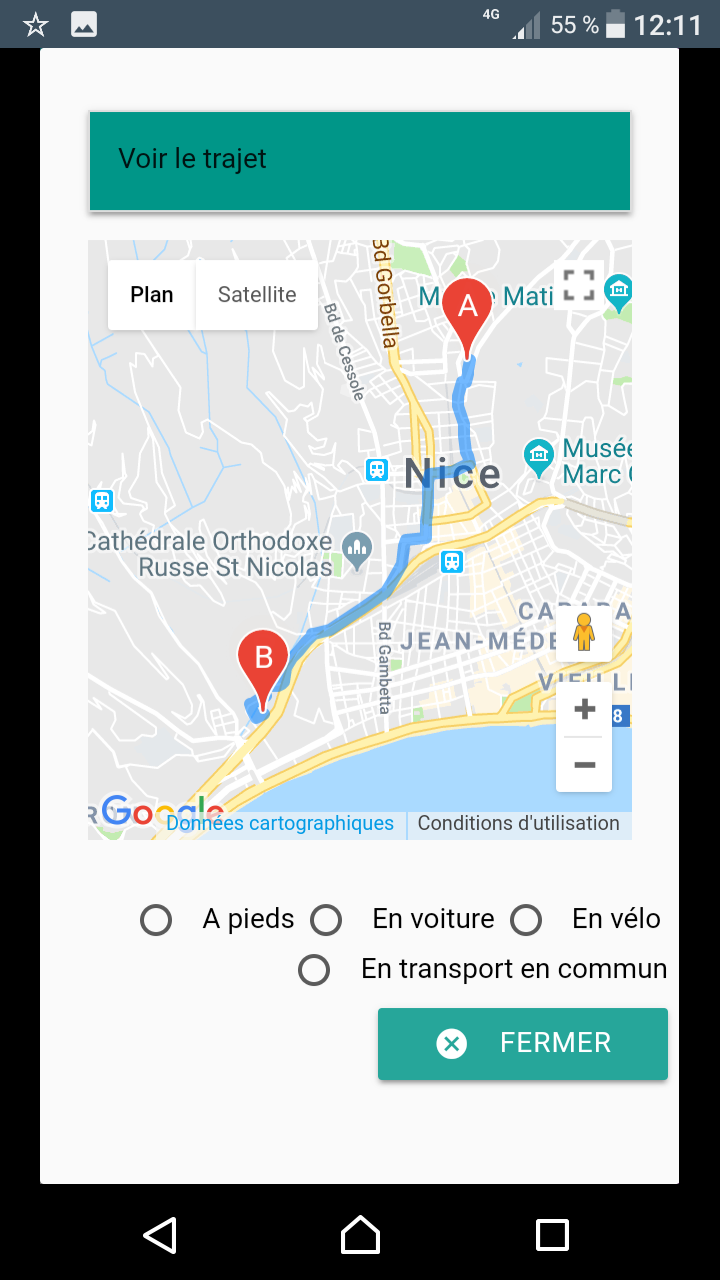
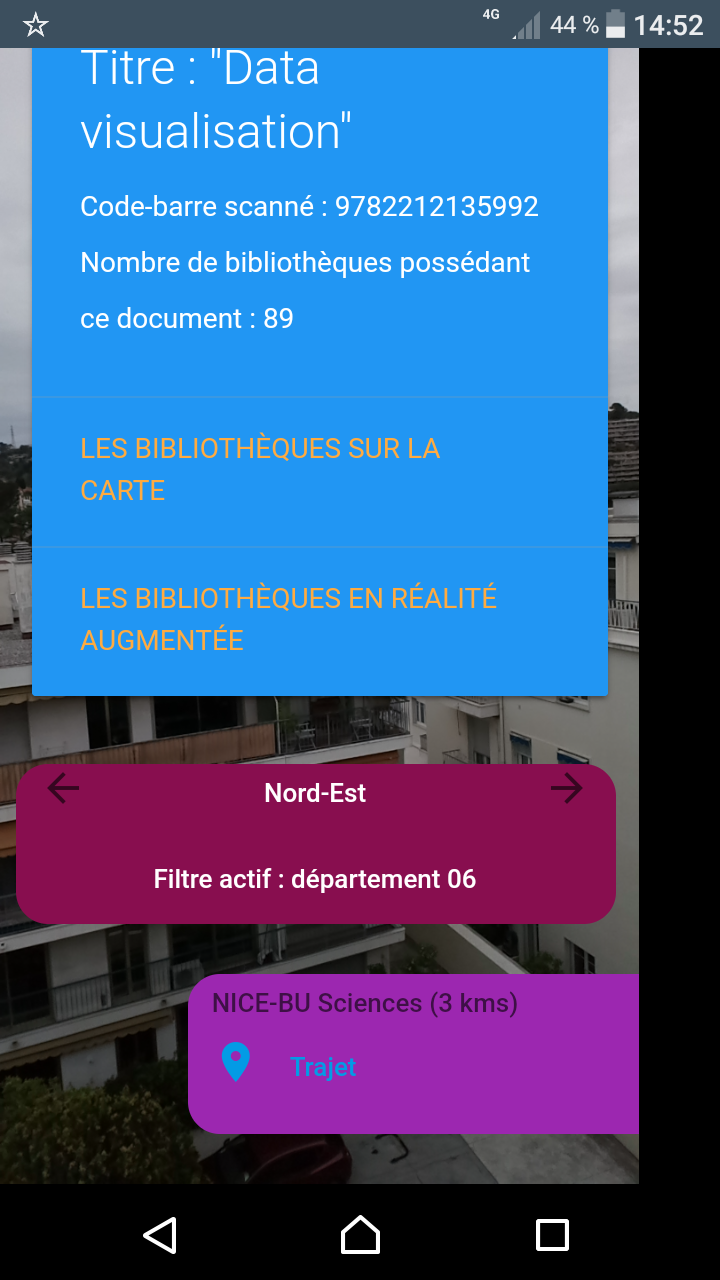
… sous forme d’application pour smartphone développée pour l’exemple (pour l’instant sous Android, installable via le Play Store) qui active la caméra du smartphone pour afficher en superposition les BU qui entourent l’utilisateur en fonction de l’orientation du mobile, calcule la distance qui les séparent de la position de l’utilisateur, cartographie les trajets, propose les liens vers leur site web… L’appli propose également une fonctionnalité de scan d’ISBN et de géolocalisation des bibliothèques qui possèdent le document selon le même procédé de réalité augmentée.
 |
 |
 |
Cette application, perfectible à bien des égards, a pour but d’illustrer l’intérêt de ces technologies en terme d’offre de services contextualisés, que ce soit en lien avec des informations pratiques (quelle est la BU la plus proche de moi, comment m’y rendre en bus, à quelle heure ferme-t-elle ?) ou les collections. Soyons réalistes : en soi scanner un ISBN et visualiser les BU qui possèdent le document n’est pas d’une utilité folle (qui a besoin de connaitre les BU qui possèdent le document qu’il tient en main ?), mais l’intérêt sous-jacent est de proposer un cas d’école des possibilités de croisement entre :
Quelques exemples à la volée de « mashups » virtuels possibles sur la base d’un ISBN ou d’un code-barre : superposer au document, si elles existent, les publications dans HAL de l’auteur, sa biographie ou sa photo Wikipedia, des critiques de livres pour des romans, des vidéos de l’INA sur le même sujet, des données locales comme le nombre de prêts, la date d’entrée dans les collections,…
Pour résumer, tout le travail d’ouverture et de liage des données bibliographiques ayant pour but de pousser leur intégration dans le web pourrait ainsi trouver un nouveau « débouché » clairement orienté services à l’utilisateur dans le monde des applications mobiles, qui sera lui aussi un jour, n’en doutons pas, indexé par les moteurs de recherche.
… plus accessible car ne nécessitant aucune installation (tout se passe dans le navigateur) et se basant sur le recours à un marqueur :



vous verrez apparaître cette forme en 3D, visez-là avec le pointeur, tapez sur l’écran : celle-ci pointe alors vers un lien profond dans notre catalogue sur les ressources électroniques en sociologie.
Cette page web (en pur html/javascript) a un fonctionnement on ne peut plus simple : le navigateur détecte la forme du marqueur (qui peut être n’importe quoi grâce à ce petit utilitaire en ligne de générateur de marqueur) et lui associe une forme en 3D (qui peut également être n’importe quoi, la seule limite étant l’imagination), qui réagit au toucher pour ouvrir une nouvelle page web à l’instar d’un lien hypertexte sur une page web (mais que l’on peut programmer pour réagir de n’importe quelle manière).
Bref on imagine immédiatement les possibilités en terme de signalement des ressources électroniques se juxtaposant « dans la réalité » aux collections imprimées, la contextualisation de l’offre de tutoriels vidéos, de nouvelles réponses à la question « où sont les livres sur… ».
Sans parler des expériences de réalité virtuelle qui elles aussi vont pouvoir démultiplier les possibilités de navigation dans les collections quelles qu’elles soient (http://www.bnf.fr/fr/evenements_et_culture/expositions/f.bibliotheque_la_nuit.html) …
L’application mobile Bu Autour
la réalité augmentée par détection de marqueur
Trois nouvelles ressources sont en test pendant le mois de mai :
![]()
 itish online library : bibliothèque numérique de sources primaires et secondaires imprimées sur l’histoire de la Grande-Bretagne et de l’Irlande, avec un accent sur la période entre 1300 et 1800. La collection comprend plus de 1280 volumes. Une partie de la British online library est en libre accès. Un abonnement Premium permet d’accéder à 134 volumes supplémentaires.
itish online library : bibliothèque numérique de sources primaires et secondaires imprimées sur l’histoire de la Grande-Bretagne et de l’Irlande, avec un accent sur la période entre 1300 et 1800. La collection comprend plus de 1280 volumes. Une partie de la British online library est en libre accès. Un abonnement Premium permet d’accéder à 134 volumes supplémentaires.
Vous pouvez consulter ces ressources en local depuis les postes et le Wifi de l’Université. La collection Burney est également accessible à distance. Pour toutes précisions sur ces tests, vous pouvez écrire à docelec@unice et si vous êtes intéressés par un abonnement à une de ces ressources, faites le nous savoir en écrivant à cette même adresse.
La Fédération Francophone de Médecine Polyvalente (FFMP) et la BIU Santé organisent conjointement une enquête flash auprès des médecins et étudiants en médecine.
Ce questionnaire très rapide a pour objectif de permettre d’améliorer l’accès à la littérature médicale.
Pour participer, c’est ici !
D’autres enquêtes équivalentes seront lancées dans les prochains mois, vous trouverez les informations détaillées dans l’article complet de la BIU Santé, sur cette page.
Merci d’avance pour votre participation !
Plusieurs abonnements n’ont pas pu être maintenus en raison d’une baisse budgétaire : 
Quelques nouveautés tout de même pour 2018 :
Ces 3 ressources sont consultables via notre site web, onglet « Ressources ». Nous restons bien évidemment disponibles pour toute question ou précision nécessaire, n’hésitez pas à nous contacter via docelec@unice.fr !
Les BU de Nice vous proposent actuellement de tester la ressource S-ECN, plateforme d’entraînement au concours de l’internat proposée par l’éditeur S Editions, dont voici le mode d’emploi.
Une enquête d’intérêt est accessible ici. Vos retours nous sont indispensables, alors, d’avance, merci pour votre participation !
Pour toute question ou remarque sur ce test, vous pouvez vous adresser à docelec@unice.fr.
Rechercher des articles en ligne peut s’avérer parfois complexe. Pour vous aider, nous vous présentons 3 outils qui vont très certainement vous faciliter la vie. Il s’agit de 3 extensions à installer sur vos navigateurs (Mozilla Firefox ou Chrome). Une fois l’installation effectuée, l’utilisation est d’une grande simplicité et peut vous faire gagner un temps précieux dans vos recherches.
Télécharger l’extension pour Mozilla Firefox (ajout du 17/11/2017 : attention, la dernière version de Mozilla Firefox (Firefox 57 Quantum) n’est pas compatible avec LibX)
Télécharger l’extension pour Chrome
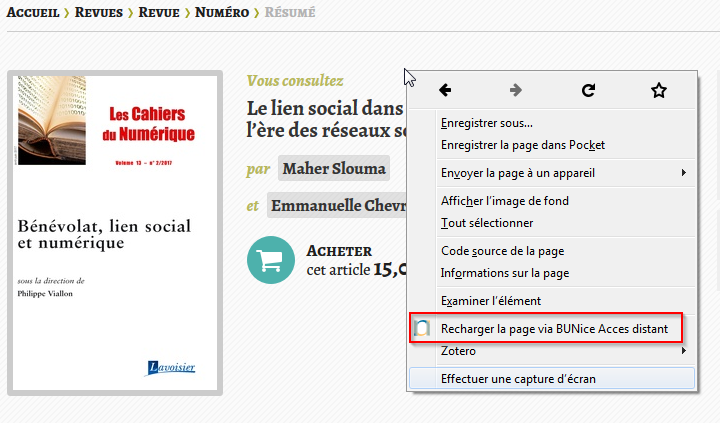
En un seul clic, vous pourrez savoir si les abonnements de la BU vous permettent de lire l’article dont vous avez besoin. Cette extension vous sera très utile lors vos recherches en dehors de l’université. En effet, pour accéder aux ressources de la BU lorsque vous êtes à l’extérieur de votre campus, il est nécessaire de passer par le site de la BU. LibX vous dispense de cette étape. Une fois l’extension installée, il vous suffira de recharger la page que vous consultez pour être automatiquement renvoyé vers le formulaire d’authentification de l’université. Si la ressource fait partie des abonnements de la BU, vous pourrez alors accéder à son contenu.
Prenons comme exemple un article de CAIRN. Lors de votre recherche, vous arrivez sur cette page qui vous propose d’acheter l’article :
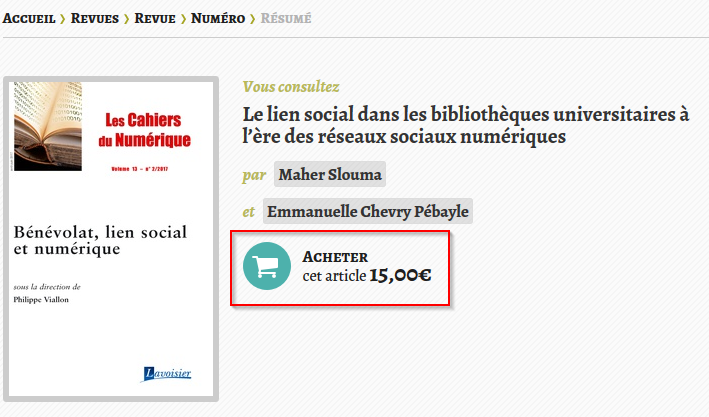
Afin de savoir si la BU est abonnée et vous permet d’accéder au texte intégral, faites un clic droit puis cliquez sur « Recharger la page via BUNice Acces distant ». Dans ce cas précis, vous pourrez accéder au texte intégral de l’article après authentification.
Télécharger l’extension pour Mozilla Firefox
Télécharger l’extension pour Chrome
![]() Cette extension vous permettra de savoir si l’article que vous souhaitez lire est accessible gratuitement sur le Web. Nos collègues de la BIU Santé de Paris Descartes vous expliquent tout ici.
Cette extension vous permettra de savoir si l’article que vous souhaitez lire est accessible gratuitement sur le Web. Nos collègues de la BIU Santé de Paris Descartes vous expliquent tout ici.
Lors de vos recherches, si une version en accès libre de l’article que vous trouvez existe, le logo ![]() apparaîtra. En cliquant dessus, vous accéderez directement au texte intégral de l’article en PDF. Voici un exemple avec un article de la revue Nature :
apparaîtra. En cliquant dessus, vous accéderez directement au texte intégral de l’article en PDF. Voici un exemple avec un article de la revue Nature :

Télécharger l’extension pour Mozilla Firefox et Chrome
Cette exte![]() nsion permet d’analyser les pages que vous visitez à la recherche d’identifiants documentaires (DOI, PMID (PubMed Unique Identifier)…) et d’ajouter un bouton
nsion permet d’analyser les pages que vous visitez à la recherche d’identifiants documentaires (DOI, PMID (PubMed Unique Identifier)…) et d’ajouter un bouton ![]() d’accès au plein-texte PDF lorsque celui est disponible. Ce bouton s’active notamment sur les pages Wikipédia, Google Scholar, Scopus, ou même HAL.
d’accès au plein-texte PDF lorsque celui est disponible. Ce bouton s’active notamment sur les pages Wikipédia, Google Scholar, Scopus, ou même HAL.
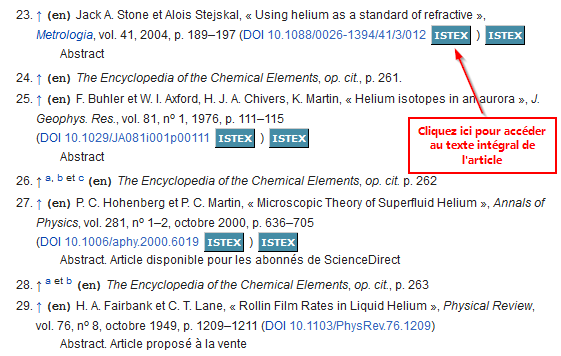
Par exemple, la bibliographie de l’article Helium de Wikipédia vous renvoie vers le texte intégral de plusieurs articles de revues acquises dans le cadre des licences nationales. Il suffit de cliquer sur le bouton![]() pour y accéder :
pour y accéder :
Pour plus de précisions sur ces outils, n’hésitez pas à nous contacter à cette adresse : docelec@unice.fr.
 SCD BU Université Nice Sophia Antipolis
2019 |
Propulsé par WordPress et Mystique thème par digitalnature
SCD BU Université Nice Sophia Antipolis
2019 |
Propulsé par WordPress et Mystique thème par digitalnature