Sudoc-PS
Centre du Réseau Sudoc-PS PACA/Nice

Le musée Masséna (Nice). Photo Jean-Pierre Dalbéra, Wikimedia Commons, CC-BY-2.0
La 7e Journée annuelle du Centre du Réseau Sudoc-PS PACA/Nice s’est déroulée le mardi 5 novembre dernier. Nous étions reçus par la Bibliothèque du Chevalier de Cessole, installée dans les locaux du Musée Masséna à Nice. Toute l’équipe sur place s’est fortement mobilisée pour organiser l’accueil des membres du réseau et nous faire découvrir ce lieu magnifique.
La bibliothèque du Chevalier de Cessole étant particulièrement riche en unicas et presse locale ancienne, les collègues ont partagé leur expérience de traitement et de valorisation de ces fonds précieux. Retrouvez ici leur présentation des collections de périodiques et leur travail de recensement. Elles repèrent également les titres qui pourraient faire l’objet d’une numérisation, par exemple la revue Mediterranea. Cette belle revue a été plus spécifiquement présentée par notre collègue Dominique Laredo (SCD de Nice) qui a publié à ce sujet un article accessible en ligne.
L’application Unicas/Presse locale ancienne, développée par notre collègue Géraldine Geoffroy et le Centre du Réseau Sudoc-PS, a été dévoilée aux participants. Cet outil de visualisation et d’amélioration des données de signalement est désormais accessible en ligne. Une page dédiée sur notre blog résume toutes les informations la concernant. Retrouvez aussi ici la présentation de Géraldine Geoffroy sur la genèse de l’appli et son fonctionnement.
Les participants ont pu manipuler ce nouvel outil d’exploration des données au cours d’un atelier. Nous en avons profité pour noter les suggestions d’améliorations, toujours les bienvenues (n’hésitez pas à nous contacter par mail).
Au cours de la journée, les participants ont également bénéficié de 2 visites guidées pour découvrir les trésors de la bibliothèque du Chevalier de Cessole, ainsi que les collections permanentes du Musée Masséna qui l’héberge.
Notre enquête de satisfaction est toujours accessible en ligne. Merci à celles/ceux qui l’ont déjà complétée pour vos commentaires utiles et positifs, et vos souhaits de thématiques à aborder pour une prochaine Journée Sudoc-PS.
Toute l’équipe du Centre du Réseau Sudoc-PS Paca/Nice remercie les collègues qui nous ont accueillis si chaleureusement. La journée a rassemblé 62 participants venus de 30 établissements des Alpes-Maritimes, du Var et de Monaco. Nous espérons vous retrouver tout aussi nombreux lors de notre prochaine édition en 2020 !

Les participants 2019 (photo A. Pandelé)
L’application Unicas/Presse locale ancienne a été dévoilée lors de la 7e Journée du réseau Sudoc-PS Paca/Nice.
Pour faciliter son accès et son utilisation, nous lui avons consacré une page spécifique sur notre blog, à côté des autres outils Colodus et Cidemis. Vous pouvez dès à présent la consulter.
Développée en interne, cette application permet d’explorer directement les données des collections de périodiques du Centre du Réseau Sudoc-PS PACA/Nice.
Elle a plusieurs finalités :
Enfin, des liens cliquables permettent de rebondir sur le catalogue national Sudoc, sur le site Presse locale ancienne de la BnF ou de renvoyer vers des numérisations existantes.
Suite à l’atelier de manipulation de la Journée du réseau, nous allons travailler à intégrer les améliorations suggérées.
Bonne exploration !
Pour aller plus loin : billets techniques ou « comment s’est construit l’application » :

A vos agendas ! La 7e Journée des bibliothèques du réseau SUDOC-PS du Centre régional PACA/Nice aura lieu le mardi 5 novembre 2019, de 9h à 16h. Vous êtes cordialement invité·e·s à participer à cette journée d’information et d’échanges sur les actualités du Centre Régional et nos pratiques professionnelles.
Cette année c’est la Bibliothèque du Chevalier de Cessole qui nous accueille, au sein du Musée Masséna, 65 rue de France à Nice. La journée se partagera entre informations professionnelles, ateliers pratiques, et visites guidées. Afin de faciliter l’organisation de cette rencontre, merci de bien vouloir confirmer votre participation en complétant le formulaire d’inscription en ligne avant le 6 octobre.
Le musée Masséna (Nice). Photo Jean-Pierre Dalbéra, Wikimedia Commons, CC-BY-2.0
Déroulement de la journée :
9h00 : Accueil des participants à la Villa Masséna autour d’un petit-déjeuner.
9h30 : Début des interventions, introduction de la Journée.
10h00 : Intervention autour du traitement des périodiques de la Bibliothèque du Chevalier de Cessole et du projet de numérisation de la revue Mediterranea.
10h30 : Démonstration de l’application du Sudoc-PS pour la visualisation des données et le signalement des unicas et de la presse locale ancienne.
11h15 : Pause café
11h30 – 12h15 : 3 groupes en alternance participeront aux activités suivantes :
* Atelier de manipulation de l’application Unicas/Presse locale ancienne
* Visite guidée de la Bibliothèque du Chevalier de Cessole et ses réserves
* Visite guidée du Musée Masséna et ses collections permanentes
12h30 – 14h : Pause déjeuner (buffet offert).
14h-14h45, puis 15h-15h45 : reprise des 3 groupes du matin en alternance : atelier de manipulation de l’application, et visites guidées. Au fil de la journée chaque groupe suivra l’atelier de manipulation et les 2 visites.
16h : Fin de la Journée.
◊ Accès en transports publics : tramway ligne 2, arrêt Alsace-Lorraine. Parking (payant) : Palais Masséna. Voir ici l’ensemble des transports en commun disponibles aux alentours.
◊ N’hésitez pas à nous contacter pour toute demande de renseignements complémentaires.
Logo Mir@bel (via Wikipedia.org)
Le réseau Mir@bel
Créé en France en 2009 par des professionnels des bibliothèques et de la documentation, Mir@bel (pour « Mutualisation d’informations sur les revues et leurs accès dans les bases en ligne ») a pour vocation de valoriser les contenus de périodiques scientifiques accessibles en ligne gratuitement, principalement en SHS. Pour chaque revue, Mir@bel propose des liens vers le texte intégral en ligne, les sommaires, les résumés ou l’indexation des articles et vous permet de rebondir sur de nombreux sites complémentaires.
Projet vivant, évolutif, mêlant veille documentaire partagée et récupération automatique à la source, ce corpus de revues évolue également, à l’image du réseau. Il recense à ce jour plus de 6000 revues. Les modes de recherche classiques sont proposés, mais aussi thématiques par discipline, chronologie, ou géographie.
Projet collaboratif
Un réseau d’institutions partenaires assure la veille collaborative et le traitement des données sur les revues. Les partenaires formalisent leur engagement dans le réseau en signant une Convention de partenariat. Le réseau Mir@bel souhaite poursuivre son développement et accroître le nombre de revues répertoriées en s’ouvrant à de nouveaux partenaires en France et dans le monde (appel à partenariat).
Dès les débuts de Mir@bel, des partenariats ont également été mis en place avec les principaux portails de revues francophones en sciences humaines et sociales. Par ailleurs, depuis 2017 des partenariats sont également proposés aux éditeurs (communiqué).
Au total, 125 professionnels de l’information interviennent directement pour mettre à jour les données de Mir@bel.
Début mars 2019 s’est tenu à Berlin un Workshop du W3C autour de la structuration des données en graphe et de leur intégration dans le web. Présentée ainsi, la problématique paraît triviale puisque le W3C est justement l’organisme qui gère et promeut ce qu’on appelle le web de données, c’est-à dire l’adoption des standards de la modélisation en RDF (qui est par nature un graphe) pour « pousser », lier et ouvrir les données sur le web. En fait, ce Workshop est le résultat d’un constat : d’une part il y a les modélisations de type web de données donc, avec leurs univers de données identifiées par des URIs sémantiquement décrites et connectées entre elles grâce à des ontologies (et il est vrai que le Linked Open Data Cloud ne cesse de s’étendre), mais à côté on constate également l’utilisation croissante par des acteurs divers et variés (économiques, institutionnels…) de bases de données non-relationnelles dites orientées graphe dans des logiques de curation et visualisation de données décorrélées des problématiques du web.
De quoi s’agit-il ? Il s’agit de structurer ses données comme un ensemble de noeuds (dotés d’attributs sous forme de paires clé-valeur pour les décrire) liés entre eux par des relations (elles-mêmes qualifiées par d’autres attributs) , tout en étant complètement libre dans la détermination des entités, du type de leurs liens et de la nature de leurs propriétés*. Ces modélisations dites de type property graph, jugées à l’usage très performantes pour traiter des masses exponentiellement croissantes de données plus ou moins structurées (le fameux Big Data, qui s’ouvre désormais aux objets connectés !), répondent donc à un besoin auquel la modélisation type RDF répond mal :
On comprend donc mieux la teneur du Workshop qui visait en fait à établir des ponts entre deux technologies, l’une dédiée à l’ouverture et l’échange de données, l’autre au stockage et à la navigation dans les données, mais utilisant toutes deux des modélisations en graphe (en sous-texte, « ça sent le roussi » pour le RDF qui pour x raisons reste une technologie de niche, tandis que parallèlement se développe le property graph pour des raisons de pragmatisme et d’efficience).
Pour donner une idée de la diversité des cas d’usages où l’approche property graph se révèle pertinente, on peut mentionner le Consortium International des Journalistes d’Investigation qui a travaillé sur les Panama papers en recourant à une base de données orientée graphe, et ce dans une démarche heuristique pour mettre à jour les connexions dans les 11,5 millions de documents non-structurés qui avaient fuités. Pour ceux que cela interesse, une brève news ici et un billet plus complet ici
Et donc ??? Pourquoi cette loooongue introduction et quel est le rapport avec l’application sur les données de périodiques du CR dont on vous parle depuis 3 billets maintenant (sachant qu’à l’échelle du CR on ne se trouve pas vraiment des problématiques de Big Data) ?
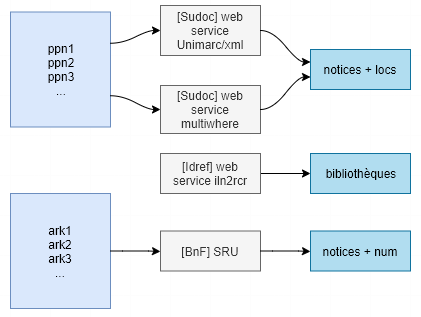
Le lien se trouve dans la modélisation : nous en étions à la fin du billet précédent sur une mini app en tant que preuve de concept sur les données des unicas, il s’agit maintenant de passer à l’échelle sur l’ensemble des données d’unicas et de presse locale au niveau du CR, et de construire les traitements de données au coeur de l’application, afin de créer et automatiser les workflows qui permettront de passer de listing de données issus du Sudoc et du catalogue général de la BnF à une interface web où chaque bibliothèque du réseau pourra visualiser et interroger ses collections, et disposer des métadonnées. La difficulté de l’exercice tient alors à la variabilité des périmètres (CR/RCR) et la multiplicité des sources d’enrichissement des données. En effet, si les trois sources primaires sont bien identifiées et (manuellement mais) facilement récupérables :
Il faut ensuite requêter plusieurs services d’exposition des données mis à disposition par l’Abes et la BnF pour construire le corpus de métadonnées (ce billet précédent détaille par exemple une méthode d’interrogation de web services et de traitement des résultats dans Excel pour les unicas *)
*A noter qu’entre temps un nouveau web service a été mis en place par l’Abes qui permet d’obtenir les notices complètes en Unimarc/Xml à partir de l’extension .xml ajoutée aux urls pérennes du Sudoc (par exemple https://www.sudoc.fr/156143453.xml), plutôt que les notices incomplètes exposées en RDF. A noter également que désormais les champs ISSN sont exposés dans les notices. Gros avantage enfin, outre la complétude des données bibliographiques, les données d’exemplaires sont également délivrées en fin de notice, ce qui à première vue économise des appels au web service multiwhere pour retrouver les bibliothèques localisées sous les notices. Mais à première vue seulement, car les données d’exemplaires ne contiennent « que » le rcr des bibliothèques : si l’on souhaite des données plus riches (nom et géolocalisation de l’établissement), il faut de toute façon revenir à l’API multiwhere, puisqu’il n’existe pas (à ma connaissance tout du moins) de web service permettant d’obtenir des notices RCR en Unimarc/xml à partir du numéro RCR (les accès aux web services d’Idref qui exposent les données d’autorités en Unimarc/xml se font sur la base du ppn).
Ce qui donne schématiquement si on se concentre sur le côté traitement de données :
mais qui n’est qu’une partie du schéma global du projet :
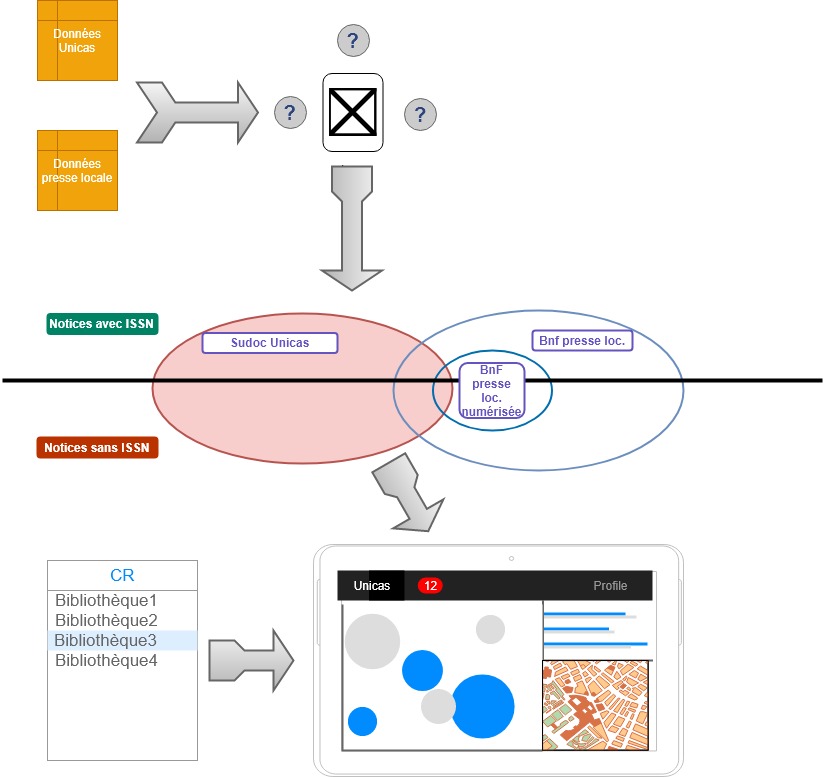
Il s’agit donc de trouver la modélisation, le stockage et le chaînage des traitements de données adéquats qui permettent de déterminer précisément le périmètre des unions et intersections entre « blocs de données » représentés par les cercles au centre du schéma, autrement dit de trouver un moyen de pouvoir répondre aux questions à la fois au niveau global du CR et particulier de chaque RCR : combien unicas ? Parmi ceux-ci quelles notices n’ont pas d’ISSN et peuvent faire l’objet d’une demande via Cidemis ? Quelle est la répartition territoriale et par bibliothèque des titres de presse ? Parmi les titres de presse concernant les AM, lesquels sont également des unicas ? Quels sont les unicas détenus par les bibliothèques monégasques pour lesquels une version numérisée est accessible ? Bref, comment NAVIGUER dans les données ?
C’est ici que l’on retrouve nos graphes : quand il s’agit de parcours dans les données, autrement dit ici de requêtes croisées entre sources distinctes, il est avantageux de sortir de la logique relationnelle de jointures entre fichiers plats et de passer à une modélisation type graphe. Ainsi, en décidant d’adopter une base de données orientée graphe (Neo4j en l’occurence) basée sur une modélisation property graph, le coeur du travail consiste à bien déterminer (et ce en fonction des questions auxquelles on veut pouvoir répondre) :
Si on « recolle » à nos données Sudoc et BnF, voici ce que cela donne en substance :
– on créé des noeuds de type Bibliothèques qualifiés par des attributs de nom, RCR, latitude et longitude et des noeuds de type unicas caractérisés par quelques éléments extraits de la notice Sudoc (titre, ppn, issn, zone 309) ; ces noeuds peuvent être connectés par une relation illustrant la localisation du périodique, ce lien étant créé à partir à partir du web service multiwhere.
– On créé également des noeuds représentant les titres de presse locale définis par les métadonnées de titre, identifiant ark et issn; on définit une relation d’équivalence « same_as » avec les noeuds unicas quand l’attribut issn est le même.
– On ajoute des noeuds qui représentent les versions numérisées des titres de presse locale quand le champ correspondant est présent dans la notice Unimarc/xml renvoyée par le SRU de la BnF, et on les relie aux noeuds de type presse locale ancienne représentants les versions imprimées
– etc…
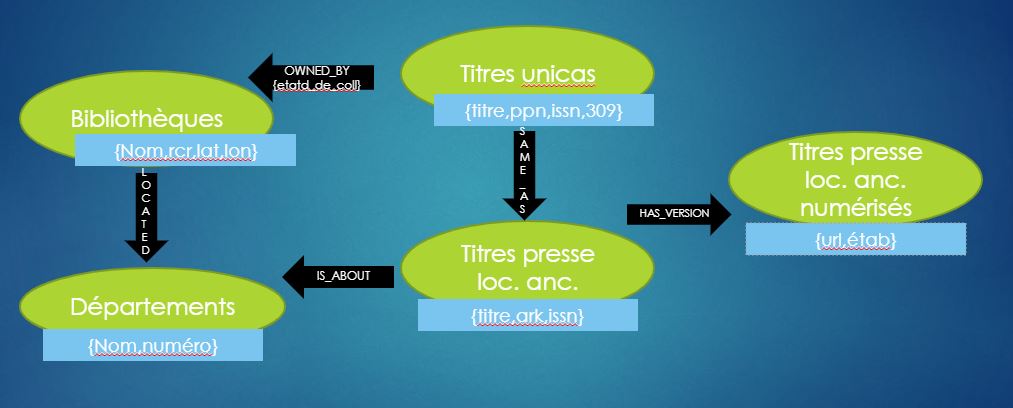
[Cliquer sur l’image pour voir l’animation]
Voilà pour le modèle de données… Évidemment l’alimentation du graphe dans la base de données ne s’effectue pas manuellement, l’ensemble du workflow est automatisé (notamment pour faciliter les mises à jour et favoriser la reproductibilité du processus). La démarche est la suivante :
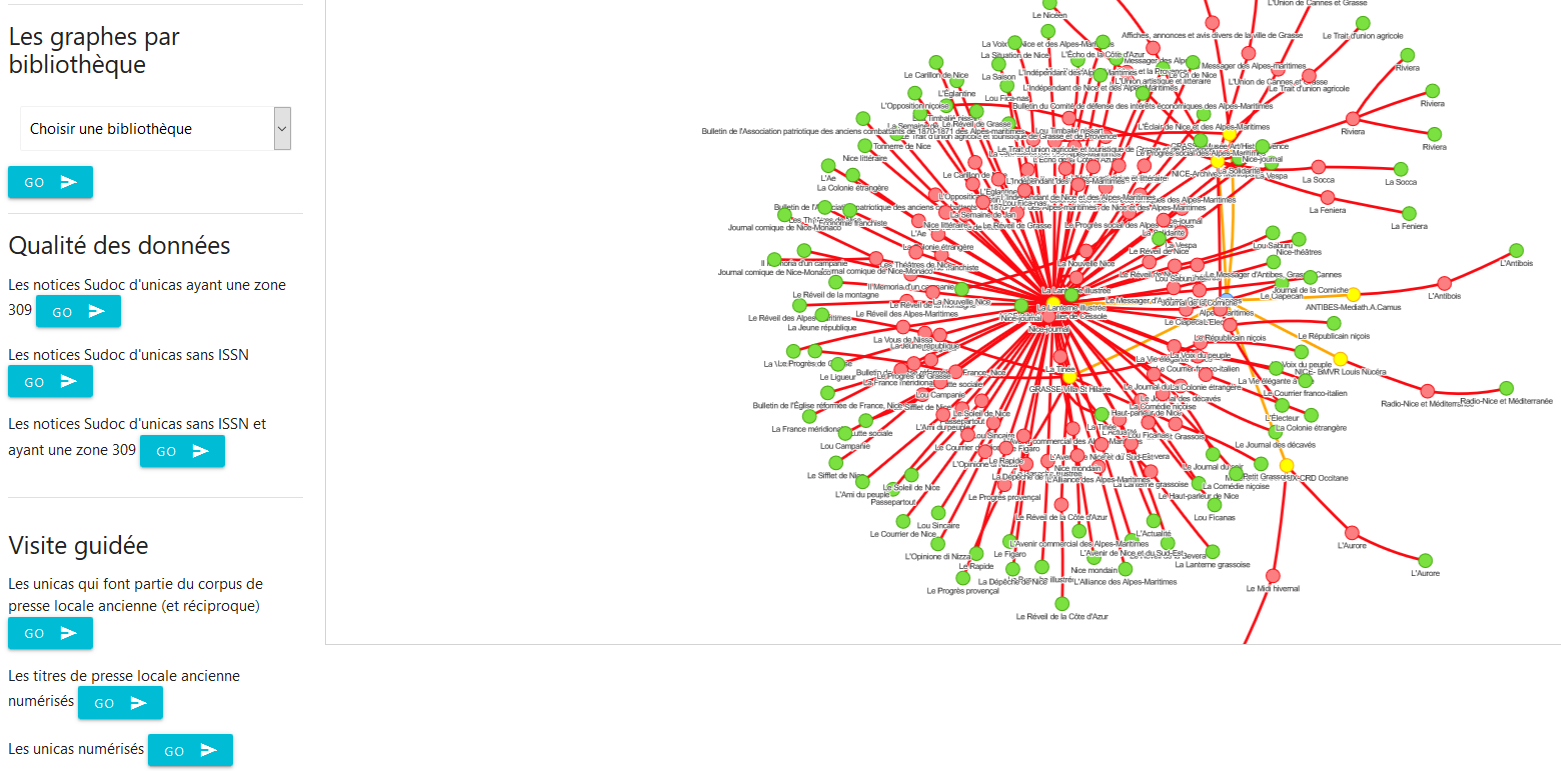
Voici un extrait du graphe final dans l’interface graphique de la base de données qui illustre exactement à quel point la dimension exploratoire est facilitée dans ce genre de visualisation et comment elle aide à mettre à jour des connexions qu’il serait extrêmement laborieux de mettre en évidence par des techniques plus classiques de jointures.
Au centre de l’image, le noeud jaune représente un unica (la Revue de Cannes), périodique également référencé comme un titre de presse locale ancienne (le noeud vert) concernant le département des Alpes-Maritimes (le noeud bleu) ayant fait l’objet d’une numérisation aux Archives municipales de Cannes (le noeud rose), mais dont la collection papier est détenue à la BM de Toulon (le noeud rouge).
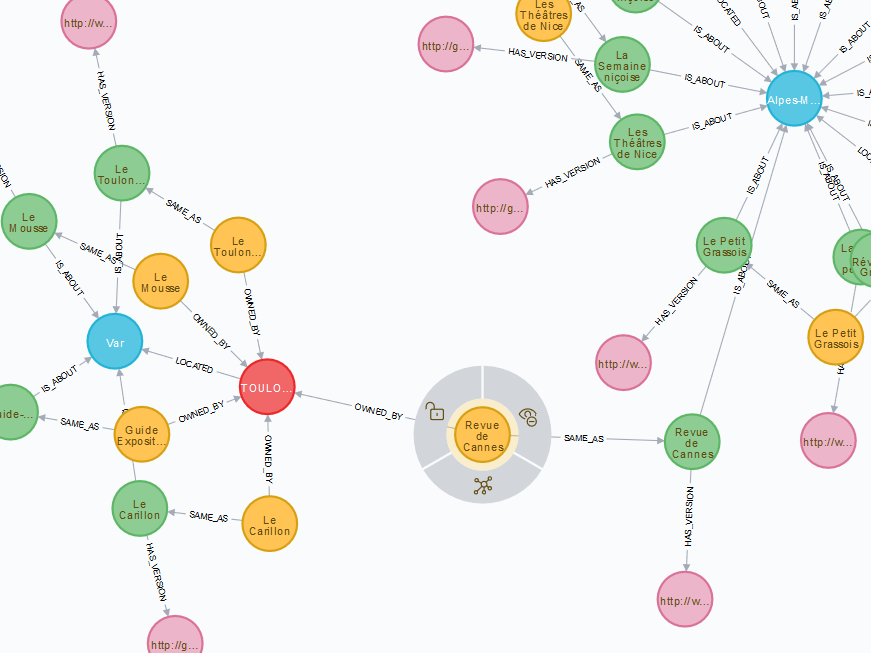
Et la version web complète proposée dans l’application :
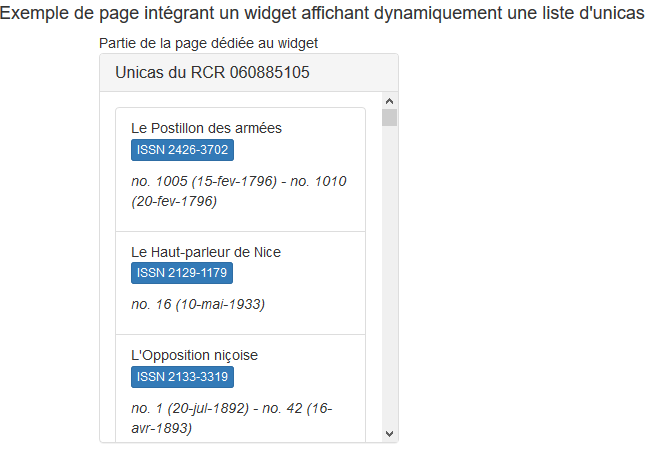
Comme prévu initialement, au-delà de la pure visualisation de parcours de graphe, l’application proposera des fonctionnalités de redistribution des données à destination des bibliothèques s’appuyant sur les traitements et appariements réalisés dans la base de données
| Sous forme d’API
(avec des urls paramétrables pour spécifier le rcr voulu) |
Par export Excel | Intégration de widget
sur une page web |
 |

|
 |
Quelques infos pratiques pour conclure (enfin !) en légèreté après cette avalanche de points techniques :
* les seules conditions à remplir sont que le graphe doit être orienté et les nœuds labellisés

Espace de l’art concret (Photo Sudoc-PS)
L’équipe Sudoc-PS a visité fin mars un établissement intéressé par l’intégration au réseau Sudoc-PS : la bibliothèque de l’Espace de l’art concret à Mouans-Sartoux. Nous avons été accueillis par Christine Jouffroy, chargée du fonds documentaire.
L’Espace de l’Art Concret (l’eac) a vu le jour grâce à la générosité de deux collectionneurs suisses : Gottfried Honegger et Sybil Albers. Commençant à collectionner des œuvres d’art dans les années 1960, ils mettent leur collection à disposition du public à partir de 1990, dans le château de Mouans-Sartoux. Au début des années 2000, ils poursuivent leur action philanthrope en faisant le choix de donner leur collection à l’État français. A cette occasion, un nouveau bâtiment est construit à proximité du château du XVe siècle, dans l’enceinte du parc. Il est inauguré en 2004. A la donation Albers-Honegger s’ajoutent les donations d’Aurélie Nemours, de Gilbert Browstone et de plusieurs autres artistes. La collection compte plus de 700 œuvres représentatives des multiples tendances de l’art concret et l’abstraction géométrique.
Selon les vœux de Gottfried Honegger, l’eac n’est pas seulement un lieu de conservation et de valorisation des œuvres, mais également un lieu de recherche, de rencontre, d’éducation et de sensibilisation à l’art de notre temps. Dans cette optique, l’eac organise des ateliers pédagogiques et permet également aux artistes de résider et créer sur place.
Le fonds documentaire de l’eac est constitué d’environ 10 000 ouvrages et se veut exhaustif concernant l’abstraction géométrique. Mais il cherche à s’élargir aux arts plastiques dans toute leur diversité y compris dans le domaine de l’architecture, de la photographie, de la mode, du design etc.
Au départ il a été constitué avec les monographies et les catalogues d’expositions acquis par Sybil Albers et Gottfried Honegger. Par la suite il s’est enrichi par les dons d’artistes et des acquisitions régulières (notamment lors de la préparation de nouvelles expositions). A partir de 2004, une politique d’échanges de publications a été mise en place avec les centres de documentation, les centres d’art, les fondations et les écoles d’art.
A part les ouvrages généraux sur l’art des XXe et XXIe siècles et les catalogues d’expositions, le fonds contient aussi des livres d’artistes, des ouvrages rares et précieux, des documents audio-visuels et des abonnements de presse spécialisée (L’Œil, Journal des Arts, Art Forum, Art Press, etc.).
Christine Jouffroy constitue en outre des dossiers documentaires sur des artistes de la collection Albers-Honegger. Ils contiennent, entre autres, les dossiers de presse et les dossiers pédagogiques d’expositions monographiques, la biographie, la bibliographie, la filmographie, les articles de presse collectés – en bref toutes sources documentaires disponibles sur l’artiste. Elle consacre quelques heures par jour à la bibliothèque partageant son temps de travail pour l’accueil du public et la médiation avec le reste de l’équipe. Actuellement, 14 personnes travaillent à l’eac.
Le catalogue des collection de l’eac est informatisé, on peut faire des recherches via le catalogue de la médiathèque de Mouans-Sartoux. En passant par la recherche avancée, il est possible de sélectionner directement le site de l’Espace de l’art concret. Le fonds est ouvert à tout public sur rendez-vous (en s’adressant à christine@espacedelartconcret.fr ) et consultable uniquement sur place.
Nous remercions chaleureusement Christine Jouffroy pour son accueil et espérons travailler bientôt avec la bibliothèque de l’eac dans le réseau Sudoc-PS.

Le château de Mouans-Sartoux, qui accueille l’Espace de l’art concret dans son parc (photo Sudoc-PS)

Hupao « Dreaming of the Tiger », Spring in Hangzhou, China. Crédits : Sh1019 [Wikimedia Commons, CC BY-SA 3.0].
Les points forts présentés dans ce rapport sont :
Le rapport présente également les objectifs pour l’année 2 de la convention 2018-2020 signée entre le CR et l’Abes, et notamment les prochaines étapes du projet de valorisation et visualisation des données du CR.
Merci à toutes et à tous pour votre participation active au réseau Sudoc-PS PACA/Nice !
L’équipe Sudoc-PS a visité le Centre Régional de Documentation Occitane (CRDO) à la Médiathèque de Mouans-Sartoux en février. Nous avons été accueillis par Michel Gourdon, principal initiateur de la création du fonds occitan et son responsable actuel.
Le CRDO a été créé en 1981. Il est géré par le Centre d’Activités culturelles occitanes, association créée à Mouans-Sartoux en 1977, dont la vocation est la reconnaissance et la mise en valeur de l’identité culturelle occitane. Si vous l’ignoriez, l’occitan est une langue romane qui regroupe six grands dialectes : l’auvergnat, le gascon, le languedocien, le limousin, le provençal et le vivaro-alpin. Il est parlé dans le tiers sud de la France, les Vallées occitanes et Guardia Piemontaise en Italie, le Val d’Aran en Espagne.

Parçans e regions d’Occitània. Pèir Eravathnauta [CC BY-SA 4.0]
Le CRDO regroupe la documentation sur le domaine occitan de Bordeaux à Nice et également les vallées occitanes d’Italie. Les fonds sont actuellement hébergés dans les locaux de la Médiathèque de Mouans-Sartoux : les ouvrages édités après 1960 sont en accès direct dans la salle (classement Dewey) ; les ouvrages anciens, les périodiques et les photos sont conservés dans les réserves et consultables sur rendez-vous en contactant Michel Gourdon. La totalité du fonds est en consultation sur place et les collections sont décrites via le logiciel Filemaker et consultables en ligne via ce lien.
Le fonds du CRDO est composé de :
Ce fonds très riche a pu être créé grâce à l’aide de la commune, de la région, du CNL (Centre national du livre) et, bien sûr, aux dons de particuliers (Claude Barsotti, Gérard Gouiran, Paul Castela, Sylvain Joseph, Michel Gourdon et autres).
Un grand merci à Michel Gourdon qui nous a chaleureusement accueilli et a partagé avec nous sa passion pour l’histoire locale, si importante dans un monde toujours plus tourné vers l’avenir et la modernité.

Centre Régional de Documentation Occitane. Photo E. Rauzy.

Centre de documentation de l’Institut européen. Photo E. Rauzy
Dans le cadre de nos visites aux établissements du réseau Sudoc-PS, notre équipe a visité fin janvier le Centre de documentation de l’Institut européen, 81 rue de France à Nice.
Le Centre de documentation comprend un fonds spécialisé dans les relations internationales, l’intégration européenne, et le fédéralisme. Les étudiants ont à leur disposition plus de 6 000 ouvrages, de nombreux périodiques d’actualité, des périodiques en ligne, des mémoires d’étudiants, ainsi que des dossiers thématiques en ligne.
L’IE·EI, Institut européen·European Institute, est un département du CIFE (Centre international de formation européenne), établissement d’enseignement supérieur privé enregistré auprès de l’Académie de Nice.
Cet établissement s’attache à :
La 1ère promotion date de 1964, à Nice. Depuis, environ 2000 étudiants venus d’une centaine de pays ont obtenu leur diplôme. Ils sont désormais au service d’institutions européennes, d’organisations internationales, d’organisations non gouvernementales, d’universités, d’administrations publiques et d’entreprises.
Le Diplôme des Hautes Études Européennes et Internationales (DHEEI) s’adresse à des étudiants ayant terminé un 1er cycle d’études (Bac+3) et son objectif est de donner une vision des problèmes politiques, sociaux, économiques et culturels du monde d’aujourd’hui. Il est accessible sur dossier. Pour chaque filière, le programme d’études dure 1 an (avec production d’un mémoire) et se déroule dans plusieurs villes européennes. Les étudiants sont souvent inscrits dans la bibliothèque des campus qu’ils sont amenés à fréquenter durant leur cursus.
L’équipe du Sudoc-PS a visité la Bibliothèque spécialisée du Musée d’Anthropologie préhistorique (M.A.P.) de Monaco en décembre 2018. Cette bibliothèque fait partie du réseau depuis les origines, dans les années ’80. Nous avons été accueillis par François Burle[1] et Elena Rossoni-Notter[2] qui ont eu l’amabilité de rédiger un texte de présentation de leur établissement, retraçant son histoire de 1902 à 2018.

Mapmc [CC BY-SA 4.0], from Wikimedia Commons
La Bibliothèque du Musée d’Anthropologie préhistorique voit le jour à Monaco en même temps que le premier Musée d’Anthropologie préhistorique, fondé officiellement en 1902 sous l’impulsion du Prince Albert Ier. Spécialisée, sa fonction principale consiste à conserver et mettre à disposition des demandeurs (e.g. chercheurs internationaux, scientifiques et étudiants) toutes les publications en lien avec les recherches en Préhistoire-Archéologie.
Depuis sa création, de nombreux ouvrages sont venus enrichir le fonds existant. La bibliothèque inventorie à ce jour un fonds précieux, des monographies internationales, des actes de colloques et de congrès, des publications scientifiques, des périodiques, des revues et des magazines sur la recherche scientifique (français et étrangers), la géologie, la spéléologie, l’archéologie et la préhistoire, ainsi que des périodiques et des magazines sur l’actualité culturelle de Monaco.
Le M.A.P. est par ailleurs éditeur depuis 1954 ; il publie chaque année un bulletin scientifique constitué d’articles multilingues de référence, soumis à un comité de lecture international (reviewer).
Un système d’échange d’ouvrages a été mis en place avec des bibliothèques, des universités, des laboratoires et des associations afin de diffuser ces revues (n°58 en 2018) et Hors-séries (n=7). La Bibliothèque du Musée comptabilise à ce jour 134 institutions abonnées (i.e. 31 françaises et 103 internationales) en plus de ses ventes auprès de libraires et de particuliers.
En parallèle des travaux récents d’inventaire, de classification de conservation et de (re)conditionnement, un intérêt particulier a été apporté à la numérisation des ouvrages précieux/ anciens et autres documents-archives, à des fins de sauvegarde et de consultation. Une grande partie des bulletins du M.A.P. (premiers numéros) ont en ce sens également fait l’objet de numérisation.

Bulletin MAP No 58
Le M.A.P. accueille tous étudiants et stagiaires intéressés par la recherche, la communication/médiation et les archives.
[1] Commis-Archiviste, Musée d’Anthropologie préhistorique de Monaco, 56 bis bd du Jardin exotique, 98 000 Monaco, fburle@gouv.mc
[2] Directeur, Chercheur-Archéologue, Musée d’Anthropologie préhistorique de Monaco, 56 bis bd du Jardin exotique, 98 000 Monaco, erossoni-notter@gouv.mc
