Le blog des BU sur les publications électroniques et les données de la recherche
Mathieu Saby
Ingénierie documentaire pour la recherche
Articles par Mathieu Saby
Votre tableur atteint ses limites? Préparez vos données avec Openrefine
8 années
OpenRefine est un logiciel libre et gratuit permettant de nettoyer, préparer et enrichir des données. Il est utilisé dans le monde des bibliothèques mais aussi par des étudiants et chercheurs dans différentes disciplines.
![]()
Avant de pouvoir analyser des données, il est souvent nécessaire de les nettoyer (harmoniser des valeurs hétérogènes, repérer des anomalies, etc.), de les préparer (changement de format, réorganisation des colonnes, etc.), ou de les enrichir.
Vous avez certainement l’habitude de réaliser ces opérations avec un tableur (Excel, Libreoffice, Google Drive…), ou pour certains d’entre-vous avec des scripts rédigés dans différents langages informatiques (R, Python, Bash…). Mais il existe des outils spécifiques, plus simples d’utilisation que les langages de script, et possédant des fonctions absentes des tableurs traditionnels. Openrefine est l’un d’eux.
Ce 23 octobre, nous avons proposé un atelier de découverte de cet outil au LearningCentre SophiaTech. Pour toutes les personnes qui n’ont pas pu y assister, voici le support créé pour l’occasion :
Si vous souhaitez en savoir plus sur cet outil ou d’autres du même type, n’hésitez pas à nous contacter : donnees-scd@unice.fr
Gérer et diffuser les données de la recherche: quels enjeux?
39 années
par Mathieu Saby.
dans Grand angle
Les données de la recherche sont précieuses, pour toutes les raisons exposées dans un premier billet. C’est en particulier le cas lorsque leur reproduction est impossible ou difficile (car coûteuse, complexe ou longue) et que leur intérêt potentiel pour la science ou pour la société dépasse le contexte de leur constitution. Il est donc important de les gérer et souhaitable de les partager.
Pourquoi associer la gestion et la diffusion des données?
La gestion des données (data management) désigne au sens large l’ensemble des activités facilitant :
- l’exploitation des données pendant un projet (stockage, partage entre partenaires, sécurisation, description, contrôle qualité…),
- leur préservation à plus ou moins long terme à l’issue du projet,
- leur réutilisation par les partenaires du projet ou éventuellement par des tiers.
La diffusion des données peut se faire quant à elle :
- à la demande (on parlera plutôt de « partage » dans ce cas) ou de bien de manière systématique,
- à destination d’un public large ou restreint,
- et être assortie ou non de conditions ou de restrictions.
Il est en théorie envisageable de bien gérer des données sans pour autant les partager avec des tiers. Par contre, l’inverse n’est pas vrai : pour pouvoir diffuser des données, encore faut-il les avoir au préalable conservées, décrites et documentées. Les financeurs de la recherche, dont l’objectif est de favoriser le partage des données, préconisent donc également l’adoption de bonnes pratiques concernant leur gestion.
Un impératif: préserver, protéger et documenter ses données
Quel que soit l’ampleur du travail, du mémoire de master à la collaboration internationale impliquant des centaines de chercheurs, une perte ou une altération des données peut avoir des conséquences dramatiques pour le projet.
Un accès non autorisé aux données peut également être dangereux pour le projet, mais aussi pour des tierces personnes, en particulier s’il s’agit de données confidentielles ou personnelles. La collecte et le traitement des données personnelles obéit à une réglementation spécifique, appelée à évoluer en 2018, qu’a présentée le correspondant informatique et liberté de l’UNS lors d’une journée d’étude le 23 juin dernier.
Plus généralement, le guide « Pratiquer une recherche intègre et responsable » du comité d’éthique du CNRS (2e édition de décembre 2016) fait de la fiabilité et de la traçabilité des données produites et des traitements réalisés une bonne pratique nécessaire à la fiabilité du travail de recherche. Cela passe en sciences dures par la tenue d’un cahier de laboratoire, qui permet de faciliter le repérage des fraudes, de répondre aux demandes de vérification des relecteurs d’un article, et de sécuriser juridiquement la recherche en fournissant une preuve d’antériorité des résultats.
Partager ses données, quel intérêt pour le chercheur et pour la société?
Au-delà d’une bonne gestion des données, dont l’intérêt est assez évident, quels sont les enjeux spécifiques du partage des données ?
Consolider la science
Une première série d’arguments sont d’ordre scientifique: améliorer la qualité de la recherche, sa visibilité et son impact, et faciliter de nouvelles recherches. Ils sont à replacer dans une logique générale de « science ouverte » : diffusion libre des articles, des données, du code informatique, des algorithmes, des protocoles, transparence de l’évaluation des résultats par les pairs, implication du public dans certaines recherches.

Différents volets de la science ouverte d’après le projet FOSTER
Revenons rapidement sur ces différents points :
Améliorer la qualité et la transparence de la recherche passe par une meilleure reproductibilité des expériences et des analyses. C’est un sujet brûlant en psychologie, en biologie et dans bien d’autres disciplines (voir ce manifeste paru il y a quelques jours dans une revue du groupe Nature). On distingue la « réplication » complète d’une étude, de la collecte des données au résultat final, souvent impossible, et la « reproduction » des résultats à partir des données brutes.
La diffusion des données renforce la visibilité et l’impact d’une étude. Statistiquement, les articles accompagnés de données sont plus cités que les autres (sélection d’articles sur le sujet).
Enfin elle permet de faire avancer plus vite la science :
- Constitution de bases de données internationales de référence, comme en génétique, ou en cristallographie.
- Méta-analyse synthétisant des données issues de plusieurs études pour consolider les connaissances sur un sujet.
- Agrégation ou comparaison de données liées à des lieux ou à des périodes distinctes.
- Application de nouvelles méthodes ou de nouveaux outils à des données anciennes.
- Exploitation de sous-ensembles de données non analysés par leurs producteur (cas de plus en plus fréquent lié à l’augmentation de la taille des jeux de données).
- Nouvelles collaborations avec d’autres chercheurs.
La réutilisation de données est déjà bien établie en génétique ou en astronomie, mais encore balbutiante dans d’autres disciplines. En sciences sociales, elle est par exemple une pratique courante au Royaume-Uni, mais nettement plus marginale en France.
Renforcer la place de la science dans la société
D’autres arguments sont d’ordre socio-économiques, politiques ou patrimoniaux:
- Rationalité économique : la collecte et le traitement des données peuvent couter très cher, il faut donc les « rentabiliser » au maximum, et éviter de recréer des données déjà disponibles.
- Bon usage de l’argent public : la recherche financée sur fonds publics devrait bénéficier à tous, et donc être diffusée sans barrière et le plus largement possible.
- Utilité pour la société et les entreprises : cela concerne au premier chef les données d’essais cliniques, épidémiologiques, économiques, climatologiques, environnementales, etc. A titre d’exemple, la communauté scientifique américaine est fortement mobilisée depuis plusieurs mois pour préserver les données climatologiques, de peur que le président Trump ne les fasse disparaître ou ne restreigne leur disponibilité.
- Maîtrise des données par la communauté scientifique : même si des acteurs privés (éditeurs, sociétés spécialisées) ont un rôle à jouer dans la diffusion des données, la communauté scientifique doit pouvoir en conserver la maîtrise.
- Constitution d’un patrimoine scientifique. On peut aujourd’hui accéder aux oeuvres et aux travaux préparatoires de Darwin, Newton ou Claude Bernard. Mais de quels éléments disposeront nos héritiers pour documenter l’histoire de la science du XXIe siècle?
- Respect des obligations et recommandations des universités, financeurs et revues. Ces politiques, variables selon les pays et les disciplines, ont été mises en place depuis une dizaine d’années pour apporter une réponse institutionnelle à tous les enjeux exposés précédemment.
Des freins et des difficultés à prendre au sérieux
Le partage et la réutilisation des données de la recherche sont encore loin d’être généralisés. Cela s’explique par différentes objections, qui sont de différents ordres.
Les objections pratiques sont multiples :
- Manque de temps.
- Coût lié à la préservation des données.
- Manque de compétences.
- Manque d’infrastructures adaptés.
L’organisation traditionnelle de la recherche et de la communication scientifique ne favorise pas le partage :
- Faible incitation institutionnelle.
- La communication des résultats scientifique passe avant tout par la rédaction d’articles.
- Manque de reconnaissance du partage de données dans le processus d’évaluation des chercheurs.
Un partage trop rapide et non préparé peut avoir des effets négatifs :
- Risque de mauvaise interprétation des données, qui pourrait nuire à leur producteur.
- Risque d’une mise en évidence d’erreurs dans la collecte ou le traitement des données.
- Risque de favoriser le travail d’une autre équipe au détriment de la sienne, dans un contexte de concurrence de plus en plus vive entre chercheurs. C’est particulièrement vrai lorsqu’un même jeu de données peut donner lieu à plusieurs publications étalées sur plusieurs années.
Les réticences les plus profondes sont liées à la nature même des processus de recherche :
- Difficultés théoriques ou méthodologiques pour réutiliser des données dans certaines disciplines: comme l’explique le projet ANR Reanalyse, « la démarche qualitative construit des données (observations, entretiens en particulier) qui sont produites dans l’interaction du chercheur avec le milieu qu’il étudie : leur réutilisation dans un autre contexte ne va donc pas de soi ».
- Pratiques parfois trop hétérogènes pour que les données puissent facilement être réutilisées : manque d’un format commun partagé par tous les chercheurs une discipline, etc.
Enfin des questions juridiques et éthiques sont à prendre en considération :
- Utilisation de données personnelles ou sensibles, en particulier dans le domaine médical.
- Utilisation de données détenues par un tiers.
- En sciences sociales, la recherche « procède le plus souvent sur la base d’un contrat de confiance entre l’enquêté et l’enquêteur qui n’inclut pas la mise à disposition des informations fournies à d’autres que ceux à qui elles ont été confiées » (citation du projet Reanalyse)
Comment répondre à ces enjeux tout en tenant compte de ces freins? Vous le saurez dans le prochain épisode!
En attendant, quelques liens pour aller plus loin si le sujet vous intéresse :
Pour s’informer
- Site national de veille et information sur les données de la recherche (MENESR, CNRS, INIST-CNRS, INSERM, INRA, IRD)
- Guide d’introduction aux données de la recherche destiné aux doctorants de Bretagne et Pays de Loire (site Formadoct)
- Services et ressources de l’INRA (peut être utile à des chercheurs non rattachés à l’INRA)
- Dossier du CIRAD (idem)
- Série d’articles sur le site des correspondants information scientifique et technique de l’Institut des SHS du CNRS
- Bon article de vulgarisation dans le journal du CNRS : « Préserver les données de la recherche à l’ère du Big Data« , 09/09/2016, par Guillaume Garvanèse
- Billet de l’URFIST de Paris : « Données » de la recherche, les mal-nommées, 15/11/2013 par Sylvie Fayet
Pour se former
- Projet Doranum de formation à distance sur la gestion et le partage des données (INIST-CNRS et réseau des URFIST, avec la participation de la BU de Nice)
- Services et tutoriels sur les données de la recherche sur produits par l’INIST-CNRS
Les données, quel enjeu pour la recherche et les bibliothèques?
59 années
par Mathieu Saby.
dans Grand angle
Un nombre croissant de revues scientifiques demandent aux auteurs de rendre disponibles les données analysées dans leurs articles. C’est par exemple le cas du prestigieux groupe Nature. Ce mouvement international, né dans des disciplines productrices et réutilisatrices de grandes quantité de données (astrophysique, physique des hautes énergies, génomique…), s’étend peu à peu à d’autres domaines, comme les essais cliniques, et se généralise sous l’impulsion d’universités, d’agences de financement de la recherche, de gouvernements et d’organisations scientifiques internationales.
Comment expliquer cette évolution, et comment l’accompagner?
Qu’entend-on par données de la recherche?
La notion de données fait partie de l’ »outillage intellectuel » standard des sciences de la matière et du vivant, et de certaines sciences sociales. Mais un informaticien, un statisticien, un sociologue ou un physicien se font-ils la même idée de leurs « données »? Plusieurs définitions des « données de la recherche » ont été proposées depuis une dizaine d’années, mais elles ont été formulées par différents organismes dans un but opérationnel, et non à l’issue d’une réflexion philosophique. Une des plus influente a été proposée en 2007 dans les Principes et lignes directrices de l’OCDE pour l’accès aux données de la recherche financée sur fonds publics :
les «données de la recherche » sont définies comme des enregistrements factuels (chiffres, textes, images, sons) utilisés comme source principales pour la recherche scientifique et généralement reconnus par la communauté scientifique comme nécessaires pour valider les résultats de la recherche. Un ensemble de données de recherche constitue une représentation systématique et partielle du sujet faisant l’objet de la recherche »
Notons que cette définition fortement marquée par les sciences dures devrait être adaptée pour s’appliquer pleinement aux sciences humaines et sociales.
Les données se présentent aujourd’hui le plus souvent sous forme numérique, mais ce n’est pas une obligation, et le retraitement de données anciennes impose bien souvent la manipulation de documents physiques.
Elles sont très diverses en terme de format, de volumétrie, et de méthode de constitution ou de collecte.
Toutes ne sont pas créées dans le cadre d’un projet spécifique, car elles peuvent également avoir pour origine :
- l’observation régulière de la nature (séismes, climat…) ou de la société (recensements, statistique publique…),
- l’activité d’organismes publics, d’entreprises et d’individus,
- un autre projet de recherche, éventuellement mené par une équipe différente.
On distingue fréquemment plusieurs « niveaux » de données, par exemple :
- brutes, sans trace de subjectivité (issues directement d’un instrument, etc.),
- traitées (filtrées, corrigées, calibrées, normalisées, etc.),
- dérivées (agrégation, vue spécifique ou synthétique des données, représentation graphique),
- analysées et interprétées (par le texte d’une publication scientifique).
Un enjeu scientifique majeur
Historiquement, les données exploitées par les chercheurs pouvaient être issues :
- d’expériences en environnement contrôlé,
- de l’observation de la nature
- de l’observation de l’homme en société
Cependant l’essor de l’informatique et de l’instrumentation a permis progressivement (depuis quelques décennies ou quelques années selon les disciplines) :
- la création de données « in silico » au moyen de simulations et de modélisations,
- la production d’une quantité toujours croissante de données par divers équipement scientifiques,
- la production de données dans tous les secteurs de la société (industrie, santé, communication, marketing…), qui peuvent devenir autant de sujets d’étude,
- de nouvelles formes de collaborations scientifiques impliquant le partage ou l’élaboration collective de données à large échelle (initiatives internationales en astronomie, génomique, neurosciences, etc.),
- le développement de nouvelles techniques d’analyse, de nouveaux questionnements, voire de nouveaux paradigmes scientifiques dans les disciplines traditionnellement utilisatrices de données mais aussi dans les sciences humaines (« humanités numériques »),
- un diffusion et une réutilisation plus aisée et moins coûteuse des données.
Mais les enjeux liés aux données de la recherche sont aussi économiques et sociétaux, car les données sont devenues stratégiques pour nombre d’entreprises, les pouvoirs publics, et la société dans son ensemble. Cela rend possibles de nouvelles formes de partenariats centrés sur les données entre le monde de la recherche et la société :
- réutilisation de données publiques ou privées par la recherche publique,
- réutilisation de données produites par la recherche par des acteurs publics ou privés,
- partenariats public/privé.
Pourquoi vous parler de tout cela?
Une des missions des bibliothèques universitaires consiste à soutenir la recherche, ce qui implique de :
- Donner accès à des informations scientifiques et techniques, traditionnellement présentées sous forme de livres, de revues ou de bases de données spécialisées,
- Valoriser la production de leur établissement, en promouvant notamment sa diffusion en open access.
Or les données scientifiques tendent à devenir un objet communicable et valorisable au même titre qu’une publication. Les bibliothèques des grandes universités de recherche étrangères ont donc investi ce nouveau champ, en travaillant conjointement avec les services informatique, l’administration de la recherche, et les chercheurs eux-mêmes (voir par exemple à Edinburgh ou dans le Wisconsin). Les universités françaises sont moins avancées, mais plusieurs BU ont des projets de cette nature, et des services ont été développés par l’INIST-CNRS et l’INRA.
Voici pourquoi nous menons depuis l’an dernier une réflexion sur ce sujet, que nous partagerons avec vous sur HTTBU. Après ce premier billet introductif, nous aborderons :
- les principaux enjeux liés au partage et à la gestion des données,
- des questions plus pratiques comme la mise en place de plans de gestion de données,
- les exigences de l’Union européenne dans le cadre du programme Horizon 2020,
- les ressources de formation et d’autoformation.
Si vous souhaitez en savoir plus, ou si vous avez des questions sur un point particulier, vous pouvez nous contacter en écrivant à donnees-scd@unice.fr.
Retour d’expérience: aide à la constitution d’un corpus bibliographique sur les études africaines
39 années
par Mathieu Saby.
dans Grand angle
Entre l’été 2014 et l’automne 2015, la BU a collaboré avec un groupe de chercheurs réalisant un livre blanc sur les études africaines. Nous reviendrons dans ce (long) billet sur la nature et le cadre de cette intervention, et les enseignements que nous en avons tiré.
[Billet mis à jour le 9/12/2016 : ajout de l’étape d’harmonisation des disciplines des thèses avec l’outil Openrefine]
Un livre blanc sur les études africaines en France
Différents laboratoires de sciences humaines et sociales français consacrent tout ou partie de leurs travaux à des aires culturelles spécifiques. Sous l’égide de l’institut des SHS du CNRS, quatre GIS (groupements d’intérêt scientifique) fédèrent les compétences et encouragent les partenariats entre spécialistes de l’Afrique, de l’Asie et du Pacifique, des Amériques, et du Moyen orient et du monde musulman. Le GIS sur les études africaines en France regroupe 33 laboratoires, dont l’Unité de Recherche Migrations et Société (URMIS), spécialisée dans l’étude des migrations et des relations interethniques, qui dépend à la fois des université de Nice et Paris-Diderot, de l’Institut de recherche et du développement, et du CNRS.

À la demande du CNRS, ces quatre GIS ont produit des « livres blancs » faisant le bilan des études dans leurs domaines respectifs. Une synthèse de ces livres blanc a été réalisée et une journée d’étude organisée à Paris le 24 octobre dernier. Les livres blancs sont accessibles librement et constituent des documents fort utiles pour faire le point sur les équipes de recherche, les moyens humains et les centres de documentation spécialisés concernant le Moyen-Orient et les mondes musulmans, les Amériques, l’Asie et le Pacifique, et l’Afrique.
À l’été 2014, Mmes Streiff-Fénart, Ballarin et Lesclingand, chercheuses de l’URMIS impliquées dans la rédaction du livre blanc sur les études africaines, ont pris contact avec les collègues de la BU Saint Jean d’Angély, qui avaient déjà noué des relations de longue date avec leur laboratoire. Elles souhaitaient collecter des informations sur les thèses et les articles concernant l’Afrique. Leur demande a été essentiellement étudiée par le département d’ingénierie documentaire des BU, qui leur a proposé d’extraire et d’enrichir semi-automatiquement des données bibliographiques à partir de différentes sources.
L’intervention de la bibliothèque
Nous avons fourni trois jeux de données, concernant
- Les thèses en SHS concernant l’Afrique, soutenues en France de 1930 à 2014 (15 546) ;
- Les articles concernant l’Afrique dans une sélection de 7 revues spécialisées sur l’Afrique, de 1960 à 2013 (3 919) ;
- Les articles concernant l’Afrique dans une sélection de 40 revues de SHS, de 1960 à 2013 (4 941).
Les informations fournies étaient des « métadonnées » (auteur, titre, revue, date, résumé, sujet), et non le texte intégral des articles.
Ce travail a mobilisé les compétences de plusieurs collègues chargés de la documentation électronique et de l’ingénierie documentaire (pour les sources numériques et les aspects techniques), ou en poste dans les BU Saint-Jean d’Angély et Droit (pour les sources imprimées). Il a nécessité une collaboration régulière avec les chercheuses (6 réunions et de nombreux échanges) afin de préciser leurs besoins (liste des revues, critères d’inclusion ou d’exclusion des articles et des thèses, mots clés thématiques et géographiques) et la répartition du travail. Enfin il s’est avéré très prenant tant pour nous que pour les chercheuses, notamment dans la phases de nettoyage des données.
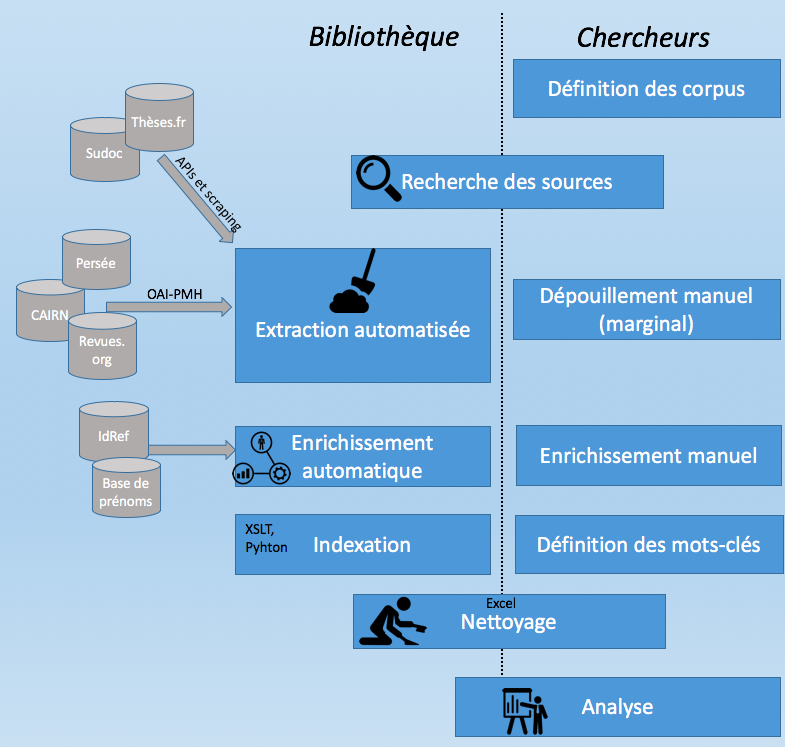
Schéma simplifié du déroulement du projet
Plusieurs sources ont été utilisées:
- Pour les thèses : le portail thèses.fr et le Sudoc (pour les thèses soutenues avant 1985, absentes de thèses.fr) ;
- Pour les revues : les sites Persée, Revues.org et CAIRN, quelques sites de revues isolés.
Notons que certaines revues ont dû être dépouillées manuellement par une stagiaire encadrée par le laboratoire.
La récupération d’information a mobilisé plusieurs techniques:
- Protocole OAI-PMH ;
- API de theses.fr ;
- Web scraping (Sudoc et sites de revues isolées).
Ces données ont été agrégées et dédoublonnées, enrichies et indexées:
- Détermination des disciplines des thèses (les informations étant présentées de manière très hétérogènes dans nos données, nous avons utilisé l’outil OpenRefine pour les harmoniser)
- Ajout du sexe des auteurs (extrait de la base IdREF, ou bien obtenu par croisement avec une liste de prénom) ;
- Indexation thématique et géographique à partir de mots clés présents dans les titres et les résumés. L’indexation géographique a pris en compte les ethnies, les pays, les macro-régions (Afrique de l’Ouest, Sahara…), et certaines formes « alternatives » (variantes de noms de pays, gentilés, capitales et villes principales…).
Puis nettoyées et filtrées (en grande partie manuellement…):
- Suppression de certains types de documents (éditoriaux, nécrologie, notes de lecture) ;
- Suppression d’articles en anglais ;
- Suppression d’articles et de thèses non liés aux sciences humaines (géologie, climatologie, etc.).
Différents outils ont été mobilisés:
Lors des premières étapes, la chaîne d’enrichissement des données a reposé essentiellement sur des traitements en XSLT. Ultérieurement, de petits scripts en Python ont également utilisés. Mais c’est Excel qui a servi d’outil de base pour la compilation, le contrôle qualité et le nettoyage des données. Nous avons également eu recours au logiciel Tableau pour visualiser des données dans une phase intermédiaire du projet.
L’analyse des données
Les données fournies par la BU ont fait l’objet d’une première analyse rapide afin de contrôler la qualité des données, puis d’une analyse plus approfondie par les membres du GIS, présentée dans la 3e partie (« L’Afrique dans les thèses et les revues ») du livre blanc.

Concernant les thèses, les auteurs ont pu mettre en évidence:
- Une forte progression du nombre de thèses à la fin des années 1970 et dans les années 1980, puis une stabilisation (environ 400 thèses par an sur l’Afrique aujourd’hui) ;
- Une domination du droit et des langues jusqu’aux années 1970, puis une diversification (histoire, géographie, sciences économiques, sciences politiques, anthropologie) ;
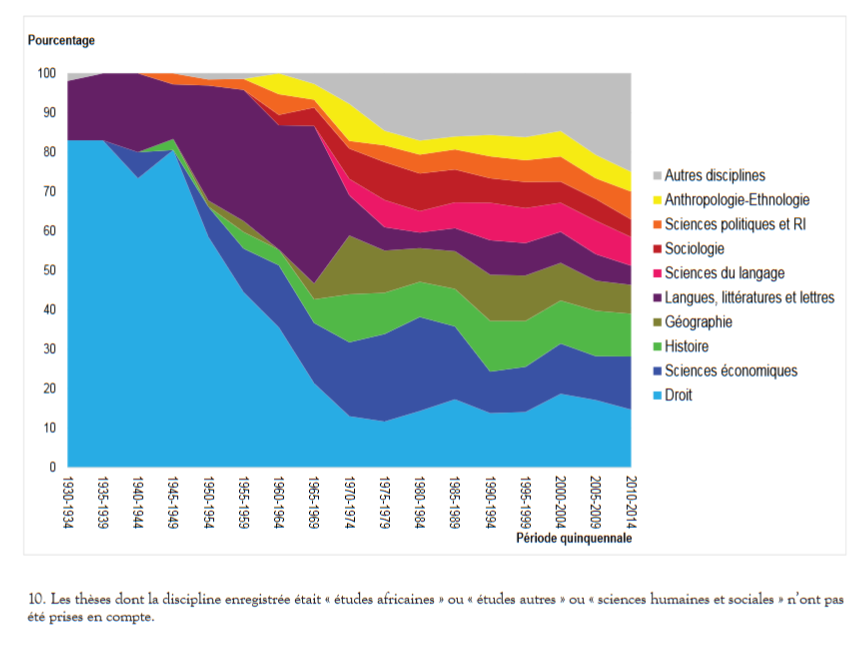
Évolution de la part des disciplines les plus représentées (fig 3. p. 78)
- Une suprématie francilienne et parisienne : Près de la moitié des thèses sur l’Afrique ont été soutenues dans une université francilienne, principalement dans Paris intra-muros. Bordeaux et Aix-Marseille constituent deux pôles secondaires importants ;
- Un sex-ratio très déséquilibré en défaveur des femmes, le différentiel tendant à s’atténuer dans la période la plus récente, mais beaucoup plus lentement pour les directeurs de thèses que pour les doctorants ;
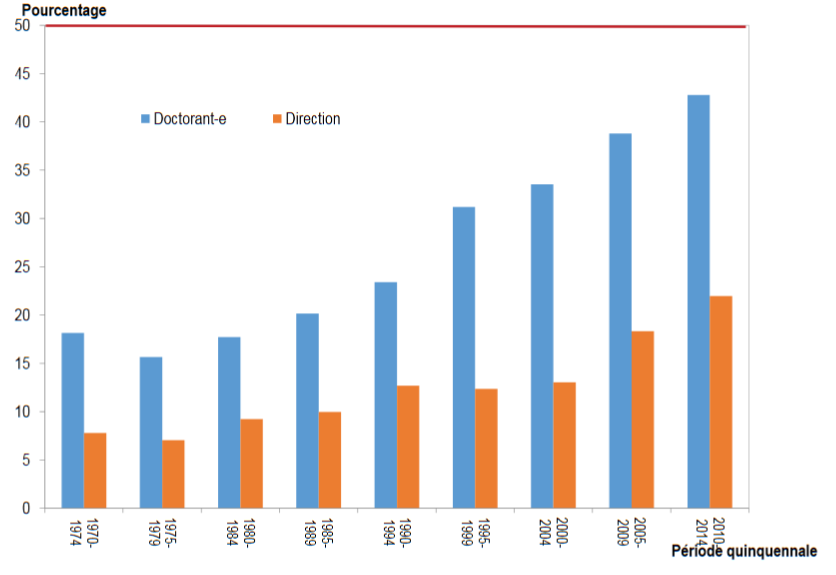
Évolution de la part des femmes (doctorant-e et direction) depuis 1970 (fig 5 p. 80)
- Un sex-ratio très différentié selon les disciplines : 1 doctorante pour 4 ou 4,5 doctorant en droit ou en philosophie (mais la philosophie ne représente que 0,7% des thèse, le sex-ratio est à prendre avec précaution), contre 1 pour 1 en démographie, et 1 directrice de thèse pour 11 à 12 directeurs en sciences économiques et politiques !
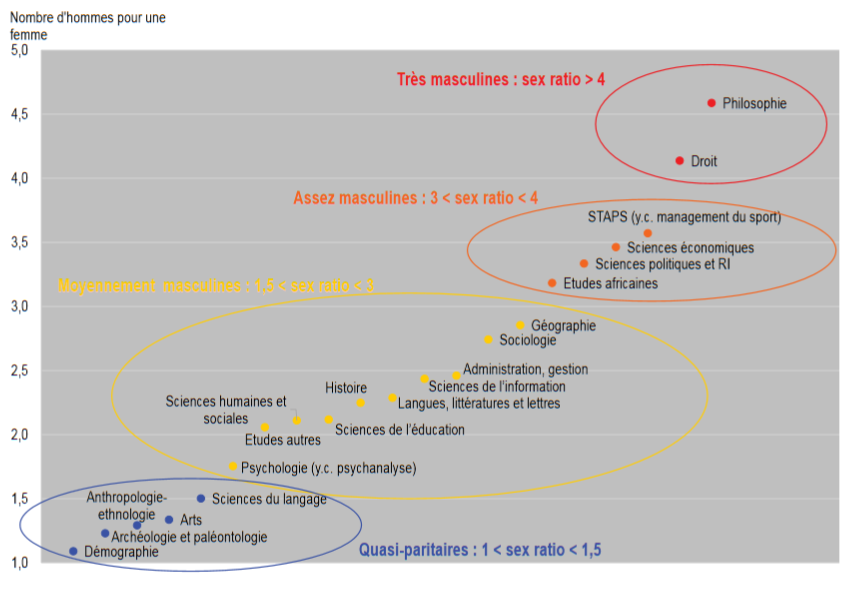
Sex ratio par disciplines (doctorants) (fig 6 p. 82)
D’autres analyses ont porté sur les revues:
- La part des articles consacrés à l’Afrique dans des revues non spécialisées : L’Afrique est bien représentée (19 à 48 % des articles) dans les revues thématiques sur le développement, le Sud, les grandes aires culturelles, les migrations, et dans une moindre part (8 à 23%) dans les revues géographie, d’anthropologie et de démographie. Elle occupe une place réduite dans les revues d’histoire, de droit, d’économie et de sociologie.
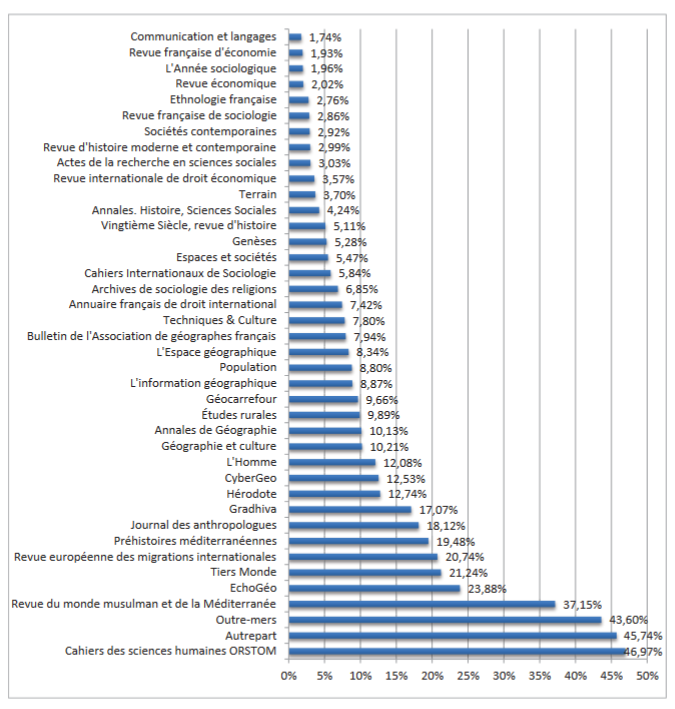
Part de l’Afrique dans des revues généralistes (fig. 1 p. 95)
- L’importance respectives des différentes macro-régions dans les revues spécialisées sur l’Afrique: les articles concernant l’Afrique de l’Ouest (en particulier la Côte d’Ivoire, le Sénégal et le Mali) sont de loin les plus nombreux, mais le nombre d’articles consacrés à l’Afrique australe et l’Afrique de l’Est a fortement progressé au cours de la période (ainsi que ceux consacrés à l’Afrique du Nord, mais il s’agit en partie d’un artéfact statistique du à la prise en compte de la revue Maghreb-Machrek à partir de 2003)
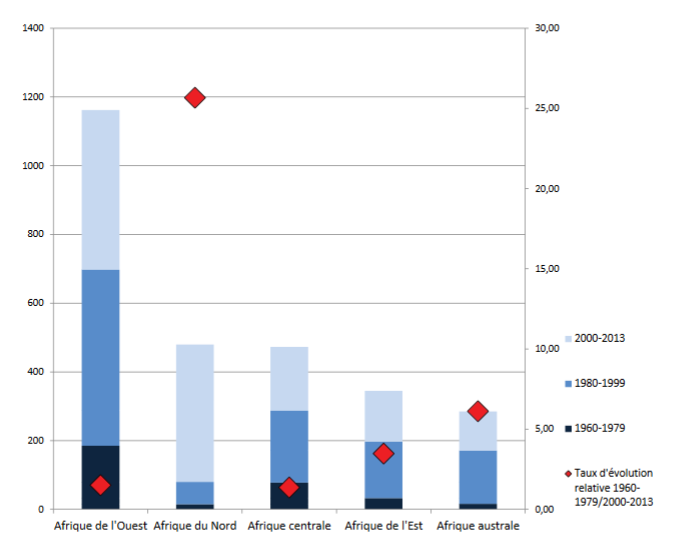
Nombre d’articles par région. Évolution. (fig. 3 p. 99)
- Poids et évolution des différents thèmes dans les revues spécialisées: et surtout leur évolution: dans les années 1960, les articles évoquaient en priorité des sujets liés aux sociétés traditionnelles. Dans les années 2010, cette place est occupée par les sujets liés à la politique et à l’administration. Des thèmes quasiment inexistant il y a 50 ans ont désormais une place importante: la communication, le droit, la sexualité, les problèmes sociaux, les crises, la guerre et la violence.
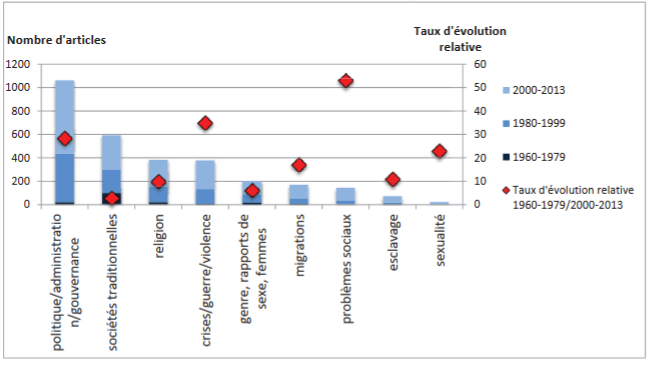
Précautions d’usage
Notre travail, en tant que « producteurs » des données a aussi été d’avertir les chercheuses de la présence de divers biais, dont certains n’ont pas pu être corrigés :
- « Silence documentaire » (documents non intégrés au corpus) lié à des sources lacunaires (certaines revues n’étaient pas en ligne pour des périodes clés, et n’ont pas pu être dépouillées manuellement) et au non-repérage d’articles si les mots clés liés à l’Afrique n’étaient pas présents dans le titre ou le résumé ;
- « Bruit documentaire » (documents intégrés à tort au corpus) lié à la présence de mots clés liés à l’Afrique dans des titres ou résumés d’articles pourtant non liés à l’Afrique, de mots clés ambigus, et à la difficulté d’exclure certains types de documents (nécrologies, éditoriaux, notes de lecture…) ;
- Silence et bruit dans l’indexation des documents intégrés au corpus ;
- Hétérogénéité quantitative et qualitative du corpus: création et disparition de revues, métadonnées de plus en plus précises et détaillées au fil du temps (le taux de résumés disponibles croit fortement à partir des années 1980, ce qui induit mécaniquement un accroissement du nombre de mots clés reconnus) ;
- Importance du nettoyage manuel, et donc possibilité d’erreurs humaines.
Quel bilan?
Concernant la communication avec les chercheuses, notre position d’« extériorité » a pu être un handicap, qui a entraîné quelques malentendus, et un surcroît de travail pour toutes les parties prenantes. Nous avons pu également constater des différences « culturelles » entre bibliothécaires et chercheurs (par exemple, un bibliothécaire fera tout pour conserver les identifiants permettant de recroiser des données, alors qu’une démographe aura le réflexe de les supprimer).
L’idée initiale d’une « extraction automatisée de données » a dû être fortement nuancée, surtout sur un corpus aussi hétérogène. Certaines sources ont dû être dépouillées manuellement, d’autres n’ont pas pu l’être, et les données finalement recueillies ont été plus hétérogènes que prévu, ce qui a entraîné un travail important de nettoyage de notre part et de la part du GIS, et a limité la faisabilité ou la fiabilité de certaines analyses.
Nous avions pensé utiliser certaines sources qui n’ont finalement pas pu être retenues pour des raisons techniques, de qualité et de complétude des données (les premiers essais à partir des données d’Isidore n’ont pas été concluants) ou de disponibilité (un export global des thèses du Sudoc nous aurait fait gagner du temps).
Les méthodes mises en œuvre liaient fortement les phases d’extraction et d’indexation. Ces deux volets gagneraient à être distingués : même si l’extraction est basée sur certains mots-clés, ce ne sont pas forcément ces mots-clés qui doivent servir lors de l’analyse.
Enfin, les outils et méthodes développés n’ont pas été pensées dès le départ pour être réutilisables. Si un projet du même type se représentait, nous chercherions à les rendre plus génériques.
Et après?
La contribution au livre blanc sur les études africaines nous a permis de confirmer notre intuition de départ: les bibliothèques disposent de compétences qui peuvent être utiles à certains projets de recherche.
D’autres expérimentations du même type sont en cours, et seront le sujet de billets à venir.
Vers de nouveaux services pour la recherche
09 années
par Mathieu Saby.
dans Flash-infos
Peut-être avez-vous remarqué que depuis quelques mois, dans le bandeau d’HTTBU les « données de la recherche » ont rejoint les « publications électroniques » ?
Un petit historique s’impose pour comprendre ce changement. La bibliothèque universitaire a développé depuis plusieurs années des services s’adressant principalement ou exclusivement aux chercheurs:
- accès à la documentation électronique (également accessible aux étudiants) ;
- aide à la diffusion de vos travaux (assistance au dépôt de travaux dans l’archive ouverte HAL Unice, conseils sur le droits d’auteur et les licences libres, publication en ligne de revues et de colloques (Revel), gestion des thèses électroniques.
HTTBU ayant été conçu pour faire connaître ces services, vous pouvez y lire des informations sur les ressources électroniques acquises pour la communauté UNS (évolution de l’offre, nouvelles interfaces, tests) ou disponibles en accès ouvert, mais aussi sur les mutations de la communication scientifique et les débats en cours sur ces sujets.
Ponctuellement, d’autres thèmes « numériques » ont pu être abordés, comme les MOOCs ou les humanités numériques. Enfin, nous avons consacré quelques billets plus techniques à des essais d’exploration et de visualisation de données bibliographiques (issues de HAL et Isidore).

Construire de nouveaux services, un chantier ambitieux! (source: Construction in Toronto May 2012)
Or, l’émergence de nouveaux modes de diffusion de la connaissance, et plus généralement l’évolution des pratiques de recherche rendent nécessaires une adaptation de ces services historiques, et le développement de nouveaux services.
Nous nous inscrivons dans un mouvement général de renforcement du soutien à la recherche par les BU, qu’illustrent par exemple les bibliothèques de Versailles Saint-Quentin (implication dans le projet de Dictionnaire des éditeurs français du XIXe siècle), de l’Ecole des ponts, de Bordeaux Montaigne ou de Grenoble (notamment par le biais de sa participation au projet Fonte Gaïa). Il y aurait bien sûr de nombreux autres exemples inspirants à citer, en France ou à l’étranger.
Nous souhaitons partager avec vous ce travail en cours. Vous pourrez donc lire dans les prochaines semaines des billets de synthèse sur différentes thématiques, des conseils pratiques, des retours d’expériences, et l’annonce de nouvelles actions, en particulier dans les domaines suivant:
- gestion et la diffusion des données produites par les chercheurs;
- outils et méthodes numériques permettant de traiter et manipuler des données, notamment en SHS;
- évolutions réglementaires récentes concernant la diffusion des résultats de la recherche et la fouille de texte et de données (Text & Data Mining);
- recommandations et exigences de l’Union européenne en matière de diffusion des résultats la recherche (projets Horizon 2020).
Vous trouverez des informations plus détaillées sur les pages de notre site présentant nos services d’accompagnement à la publication et à la gestion et manipulation de données et, pour en savoir plus sur la démarche, cette présentation faite en juin dernier lors d’une journée d’étude organisée par l’URFIST de Nice (certains points ont naturellement évolué depuis, mais la trame globale reste d’actualité) :
N’hésitez pas à nous contacter dès à présent si vous souhaitez avoir des informations sur l’un de ces sujets!
Enquête sur l’utilisation des outils de communication scientifique
410 années
par Mathieu Saby.
dans Flash-infos
ORCID, DOAJ, HAL, ArXiv, Zenodo, Zotero, Mendeley, Academia, Google Scholar, GitHub, Dryad, Figshare…
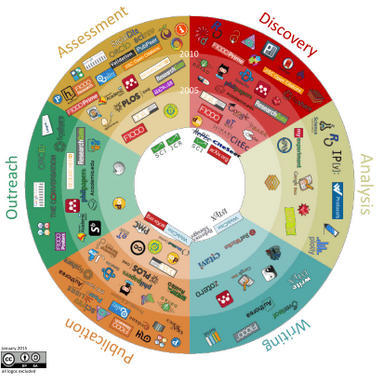
-
Kramer, Bianca; Bosman, Jeroen (2015): 101 Innovations in Scholarly Communication - the Changing Research Workflow. Figshare.
Certains de ces noms vous sont peut-être familiers, mais probablement pas tous. Ils ne sont qu’un échantillon des 575 outils recensés par la bibliothèque de l’université d’Utrecht (Pays-Bas) dans le cadre d’une étude sur les nouveaux outils et workflows utilisés par le chercheurs pour se documenter, rédiger leurs publications, analyser, publier et diffuser leurs résultats.
Cet inventaire a servi de base à une enquête internationale, en cours jusqu’en février, que son ampleur et sa méthodologie rendent particulièrement intéressante, et dont les premiers résultats sont déjà disponibles.
La Bibliothèque universitaire invite les chercheurs et doctorants de l’UNS à participer à cet effort collectif en prenant quelques minutes pour remplir le questionnaire établi par nos collègues hollandais.
Une URL spécifique est réservée aux membres de l’UNS. Après la clôture de l’enquête, nous recevrons des données (anonymisées) correspondant aux questionnaires saisis par les membres de l’UNS, ce qui nous permettra de mieux connaître vos pratiques et vos besoins.
Répondre au questionnaire (lien réservé aux membres de l’UNS)
Si vous ne faites pas partie de l’UNS mais que vous êtes intéressés par cette enquête, vous pouvez remplir la version générique.
Pour en savoir plus sur l’enquête vous pouvez consulter cette page d’introduction en français : https://101innovations.wordpress.com/francais/
Pour en savoir plus sur le projet de recherche dans son ensemble : https://101innovations.wordpress.com/tag/updates-insights/
Deux équipes de la Bibliothèque sont à votre écoute pour toute question relative aux thématiques abordées dans cette enquête. N’hésitez pas à les contacter:
– le service « Publication » publication-scd@unice.fr : droits d’auteurs, modèles éditoriaux, open access, création de revues et de colloques
– l’équipe « Données de la recherche » donnees-scd@unice.fr, créée cet automne : expérimentation de services centrés sur la gestion, la diffusion et le traitement des données de la recherche
