Le blog des BU sur les publications électroniques et les données de la recherche
Le web de données, Isidore adore !
L’API d’Isidore pour en explorer les données, c’est chouette. L’accès par un Sparql Endpoint, c’est encore mieux !
Mais avant toute chose, un petit crochet par les concepts et technologies de base du Linked Open Data s’impose (car c’est de cela qu’il s’agit).
Et commençons donc par le formalisme RDF (pour Resource Description Framework) qui ne désigne rien de moins que le modèle de description et de publication des ressources et des métadonnées sur le web. Cette modélisation s’appuie sur 3 fondamentaux :
- Des triplets : une ressource est décrite par un ensemble de triplets, chaque triplet étant constitué par une association du type <sujet><prédicat><objet>, à l’image d’une structure grammaticale sujet-verbe-complément. Par exemple <ce livre><a pour titre>< Merci pour ce moment>, <ce livre><a été écrit par><Valérie Trierweiler> etc.. sont des triplets caractérisant l’opus en question.
- Des ontologies et des thésaurus : ce sont des modélisations (elles-mêmes structurées en triplets RDF) de représentations des connaissances (par exemple le Dublin Core). Dans les triplets RDF, Les prédicats se fondent donc sur les ontologies existantes pour typer les relations sujets-objets, c’est-à dire les sémantiser.
- Des URI : des identifiants pérennes sur le web pour chaque métadonnée. Une URI peut être une URL qui donne accès au contenu de la ressource (on parle alors URI déréférencée), mais pas que…Les sujets et prédicats des triplets RDF sont toujours des URI, tandis que les objets sont soit des URI soit des littéraux. Ainsi nos triplets précédents s’expriment (dans la notice RDF du Sudoc)
<http://www.sudoc.fr/180856936/id> <dc:title> “Merci pour ce moment" <http://www.sudoc.fr/180856936/id"> <marcrel:aut> <http://www.idref.fr/115490108/id>
L’ensemble des triplets constitutifs d’une base de données RDF (Isidore, le Sudoc, l’INSEE, DBPedia…) sont stockés dans un triplestore et forment donc un graphe qu’il est possible de requêter grâce au langage Sparql (assez similaire au SQL, le langage de requête des bases de données relationnelles) via un point d’accès web, un Sparql Endpoint.
Retour donc à Isidore dans le web de données : Isidore moissonne ses diverses sources selon le protocole OAI-PMH, c’est-à dire rapatrie des sets de données en format Dublin Core, les convertit en triplets RDF, les enrichit par croisement avec des référentiels externes, puis stocke tout ça dans un triplestore accessible avec Sparql par le Sparql Endpoint Virtuoso d’Isidore.
Et illustration de l’intérêt de tout ça avec un cas pratique : comment exploiter les données d’Isidore afin d’obtenir et étudier un corpus constitué de composants Calames et de publications autour des fonds patrimoniaux que possède ma BU (par exemple Henri Bosco, Gabriel Germain, Georges Perros, Samivel… et Michel Butor tant qu’on y est) ?
Pour commencer, on formule sa requête dans le Sparql Endpoint, ici une requête de type CONSTRUCT qui permet d’obtenir un set de résultats formant lui-même un graphe « personnalisé » à partir du graphe d’Isidore, puis on choisit la sérialisation (le format de sortie, RDF/XML en l’occurence) de ce nouveau graphe :
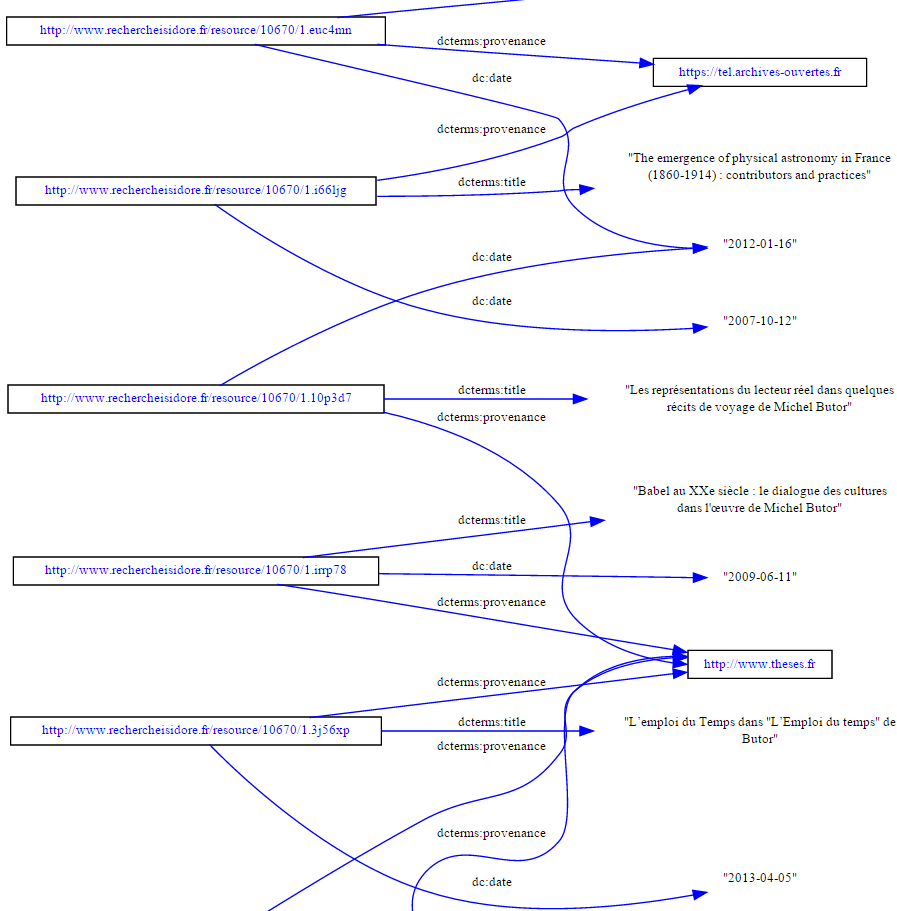
Graphe que l’on peut donc visualiser comme tel :
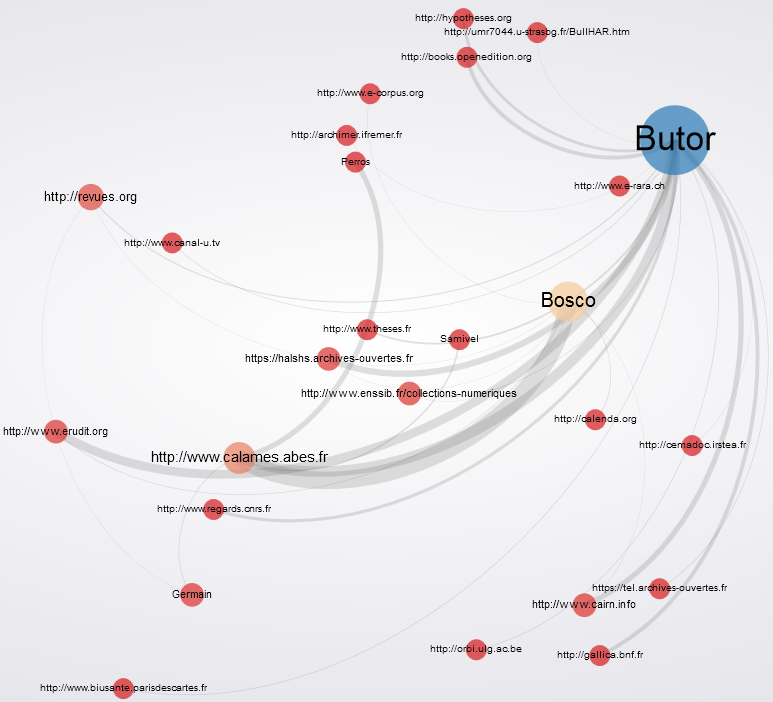
Ou plus joli, plus dynamique et en ligne :
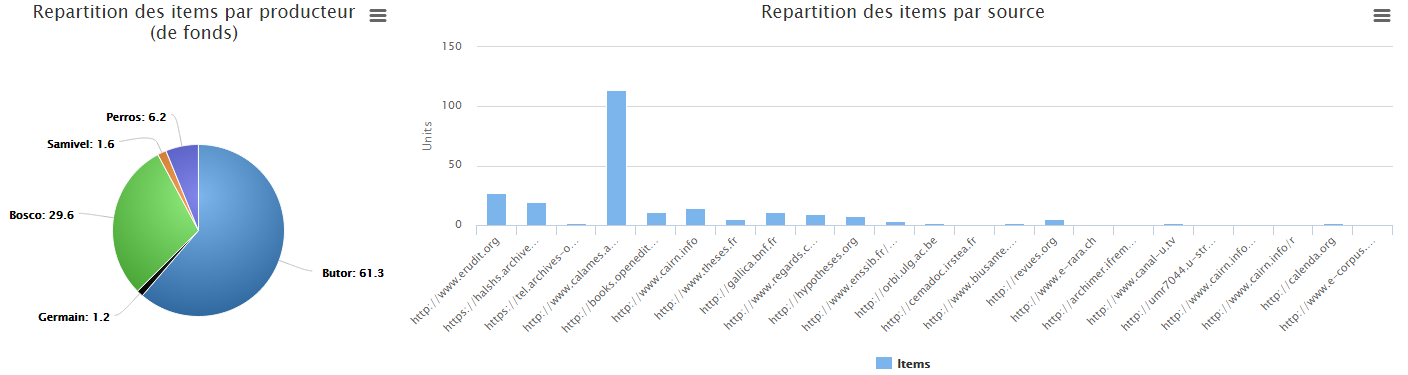
On peut aussi (essayer de) faire de jolis graphiques de visualisation statistique du corpus constitué : poids relatifs de chaque auteur dans les résultats, répartition par source de données…
Dans la même lignée, puisque Isidore enrichit ses données avec le référentiel Geonames, rien n’empêche de cartographier l’ensemble des résultats. Et puisque data.bnf propose aussi son Sparql Endpoint, pourquoi ne pas faire une réquête conjointe sur le graphe d’Isidore et celui de data.bnf afin de s’approcher d’une vue FRBRisée (hiérarchisée) des documents relatifs à ces fonds ? Par exemple pour le fonds Henri Bosco :
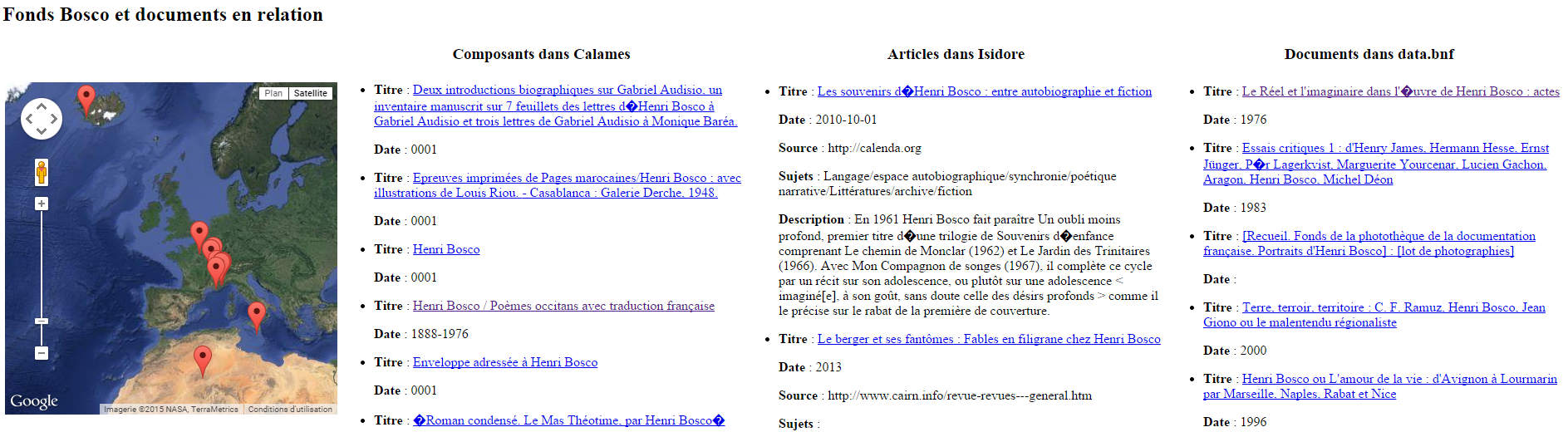
Pour visualiser la page web, c’est ici
Ainsi, les métadonnées d’Isidore formalisées en RDF, c’est la possibilité de :
- s’affranchir du niveau des notices et parcourir le graphe ouvert d’Isidore au niveau des données et non plus des notices
- exploiter l’interopérabilité de données sorties de leurs silos et structurées selon le même formalisme, indépendamment de leurs formats natifs (le web de données)
- pouvoir lier les données entre elles grâce aux URI et aux alignements des ontologies entre elles (le linked open data)
- d’exploiter sémantiquement le typage des relations entre sujets et objets, d’appliquer des algorithmes d’exploration sémantique grâce aux prédicats définis par des ontologies elles-mêmes définies sur le web (compréhensibles par des machines) pour un traitement « intelligent » des données (le web sémantique)
Au-delà des formats et des normes, il est sans doute là l’enjeu pour nos données bibliographiques comme pour les autres (données de gestion , données de la recherche…) : s’inscrire dans cette nouvelle brique de l’architecture du web où ce ne sont plus les pages html ou les documents qui sont liés mais les données et participer à la constitution d’un graphe, un jour, devenu universel.
Logiciels libres utilisés : Rhizomik RedeFer (et ses supers API), gexf-js Viewer, Highcharts
NB : pour ceux qui la chercheraient, il y encore une culotte quelque part…

[…] Depuis janvier 2015, ISIDORE indexe et enrichi en 3 langues. Suite à cette nouvelle fonctionnalité, plusieurs universités, organismes, bibliothèques et éditeurs scientifiques hors de la francophonie nous ont manifesté l’intérêt d’être moissonnés et indexés par ISIDORE. Motivés par le fait de relier et de signaler leurs données et documents dans un environnement de plus 3 millions de ressources en SHS, ils sont aussi intéressés par les enrichissements trilingues reliant les données entre elles et offrant ainsi un espace de navigation riche, multilingue à la fois accessible sur le web (portail, version mobile, modules WordPress, etc.) et pour créer des applications dans le web sémantique. […]