Le blog des BU sur les publications électroniques et les données de la recherche
DfR : l’autre interface Jstor
A côté de son interface standard, Jstor offre aux chercheurs l’interface Data for Research. Encore en version beta, cette interface propose des fonctionnalités d’exploitation avancées de la base Jstor.
Intérêts de cette interface :
- Décharger en une fois un nombre important de données (limité à 1000 maximum) sans avoir à les sélectionner page par page. Il s’agit cependant uniquement des références bibliographiques et résumés (pas de texte intégral)
- Visualiser graphiquement la répartition chronologique d’un corpus (date) et les mots-clés (nuage de mots)
- Bénéficier de fonctionnalités d’analyse linguistique sur les documents (extraction automatique de mots-clés, fréquence de mots isolés, digrammes, trigrammes…)
Quelques exemples d’exploitation : travailler sur l’évolution d’une discipline, sur l’usage d’un concept dans une discipline, récupérer l’ensemble des articles parus dans une revue, en afficher la distribution chronologique et thématique…
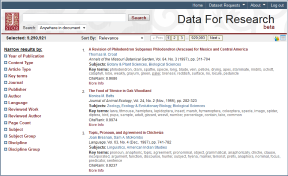
Fonctionnement de la recherche
La sélection se fait par restrictions successives. Par défaut l’ensemble des documents Jstor est sélectionné, et l’on peut ensuite rechercher des termes et/ou restreindre par les facettes proposées en colonne de gauche.
– Recherche : l’interface propose un champ de recherche unique, avec éventuellement une limitation sur les champs à interroger (titre, auteur, résumé, légende, mot-clé, citations).
Il est possible d’affiner sa recherche en construisant des équations, à l’aide d’opérateurs booléens et des codes de champs, visibles dans les URL, par exemple :
Recherche d’articles ayant le mot « Afrique » dans titre ou résumé : ((ta:afrique) OR (ab:afrique))
Récupération des articles de la revue Etudes rurales en se limitant au type « article » : (jcode:etudesrurales) AND (ty:fla)
– Facettes :
La facette Date affiche un graphique de distribution chronologique. La facette Key terms présente un nuage de mots. Les listes ou graphiques pour chaque facette sont exportables
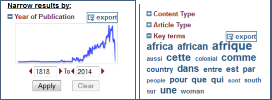
Comment récupérer le corpus de données ?
Il faut créer un compte et s’identifier (Log in/register).
Le corpus doit être inférieur à 1000 documents, sinon une sélection aléatoire sera faite lors de l’export. Il est possible de contacter Jstor pour lever cette limite. Il faut alors expliciter en détail son projet, comme le demandent aussi d’autres éditeurs pour la fouille de données. Toutefois, cette exigence peut sembler problématique (voir la question des données du data mining dans ce billet de Sciences Communes…).
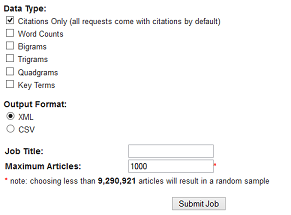
Une fois sa sélection faite, cliquer sur Datasets request, puis Submit new request.
Une fenêtre s’ouvre et vous indique le statut du traitement. Lorsque le résultat est prêt, un mail est envoyé à l’adresse de messagerie paramétrée. Aller sur « List prior requests » pour récupérer les résultats au format zip (full dataset) et un rappel des critères de recherche (summary file)
![]()
En cas de problème, l’assistance mail Jstor s’avère très réactive et efficace.
L’exploitation des résultats
L’ensemble des références bibliographiques est récupéré dans un fichier unique.
On peut par exemple importer ces données dans Excel (fonctionne bien pour l’export csv en choisissant le codage UTF8)
Pour les analyses linguistiques, on obtient un fichier par référence ; le liens avec les références se fait par l’identifiant du document.
On peut ensuite utiliser un outil d’analyse de texte (exemples trouvés – non testés – : JstorR, Paper Machines, Mallet…)
Pour les usages autorisés et la ré-exposition des données, voir les Terms and conditions (en particulier, l’incorporation dans des bases de données accessibles doit se faire avec l’accord de l’éditeur)
Quelques limites de DfR
- Contenu de la base JSTOR. Une grande partie des revues sont accessibles uniquement jusqu’à une certaine date ou après une période d’embargo de plusieurs années. Jstor est donc plus adapté à des recherches portant sur une vaste période chronologique ou l’antériorité, et pas sur les années récentes
- Complétude des données : les résumés par exemple ne sont pas nécessairement présents, surtout avant les années 70. La restriction d’une recherche sur ce critère présente donc un biais.
- La sélection « en entonnoir » est parfois frustrante ; si l’on n’utilise pas d’équation de recherche avancée, impossible par exemple de sélectionner plus d’une revue ou d’une discipline à la fois dans les facettes
- La restriction à 1000 documents s‘avère à l’usage assez contraignante
- Les mots clés ne sont pas toujours très pertinents dans les langues autres que l’anglais
- La recherche porte sur le texte intégral du document, ce qui génère parfois du bruit dans les recherches.
Malgré tout cet outil simple à prendre en main me semble ouvrir de nombreuses possibilités.

Laisser un commentaire