Le blog des BU sur les publications électroniques et les données de la recherche
Articles taggués corpus
Retour d’expérience: aide à la constitution d’un corpus bibliographique sur les études africaines
39 années
par Mathieu Saby.
dans Grand angle
Entre l’été 2014 et l’automne 2015, la BU a collaboré avec un groupe de chercheurs réalisant un livre blanc sur les études africaines. Nous reviendrons dans ce (long) billet sur la nature et le cadre de cette intervention, et les enseignements que nous en avons tiré.
[Billet mis à jour le 9/12/2016 : ajout de l’étape d’harmonisation des disciplines des thèses avec l’outil Openrefine]
Un livre blanc sur les études africaines en France
Différents laboratoires de sciences humaines et sociales français consacrent tout ou partie de leurs travaux à des aires culturelles spécifiques. Sous l’égide de l’institut des SHS du CNRS, quatre GIS (groupements d’intérêt scientifique) fédèrent les compétences et encouragent les partenariats entre spécialistes de l’Afrique, de l’Asie et du Pacifique, des Amériques, et du Moyen orient et du monde musulman. Le GIS sur les études africaines en France regroupe 33 laboratoires, dont l’Unité de Recherche Migrations et Société (URMIS), spécialisée dans l’étude des migrations et des relations interethniques, qui dépend à la fois des université de Nice et Paris-Diderot, de l’Institut de recherche et du développement, et du CNRS.

À la demande du CNRS, ces quatre GIS ont produit des « livres blancs » faisant le bilan des études dans leurs domaines respectifs. Une synthèse de ces livres blanc a été réalisée et une journée d’étude organisée à Paris le 24 octobre dernier. Les livres blancs sont accessibles librement et constituent des documents fort utiles pour faire le point sur les équipes de recherche, les moyens humains et les centres de documentation spécialisés concernant le Moyen-Orient et les mondes musulmans, les Amériques, l’Asie et le Pacifique, et l’Afrique.
À l’été 2014, Mmes Streiff-Fénart, Ballarin et Lesclingand, chercheuses de l’URMIS impliquées dans la rédaction du livre blanc sur les études africaines, ont pris contact avec les collègues de la BU Saint Jean d’Angély, qui avaient déjà noué des relations de longue date avec leur laboratoire. Elles souhaitaient collecter des informations sur les thèses et les articles concernant l’Afrique. Leur demande a été essentiellement étudiée par le département d’ingénierie documentaire des BU, qui leur a proposé d’extraire et d’enrichir semi-automatiquement des données bibliographiques à partir de différentes sources.
L’intervention de la bibliothèque
Nous avons fourni trois jeux de données, concernant
- Les thèses en SHS concernant l’Afrique, soutenues en France de 1930 à 2014 (15 546) ;
- Les articles concernant l’Afrique dans une sélection de 7 revues spécialisées sur l’Afrique, de 1960 à 2013 (3 919) ;
- Les articles concernant l’Afrique dans une sélection de 40 revues de SHS, de 1960 à 2013 (4 941).
Les informations fournies étaient des « métadonnées » (auteur, titre, revue, date, résumé, sujet), et non le texte intégral des articles.
Ce travail a mobilisé les compétences de plusieurs collègues chargés de la documentation électronique et de l’ingénierie documentaire (pour les sources numériques et les aspects techniques), ou en poste dans les BU Saint-Jean d’Angély et Droit (pour les sources imprimées). Il a nécessité une collaboration régulière avec les chercheuses (6 réunions et de nombreux échanges) afin de préciser leurs besoins (liste des revues, critères d’inclusion ou d’exclusion des articles et des thèses, mots clés thématiques et géographiques) et la répartition du travail. Enfin il s’est avéré très prenant tant pour nous que pour les chercheuses, notamment dans la phases de nettoyage des données.
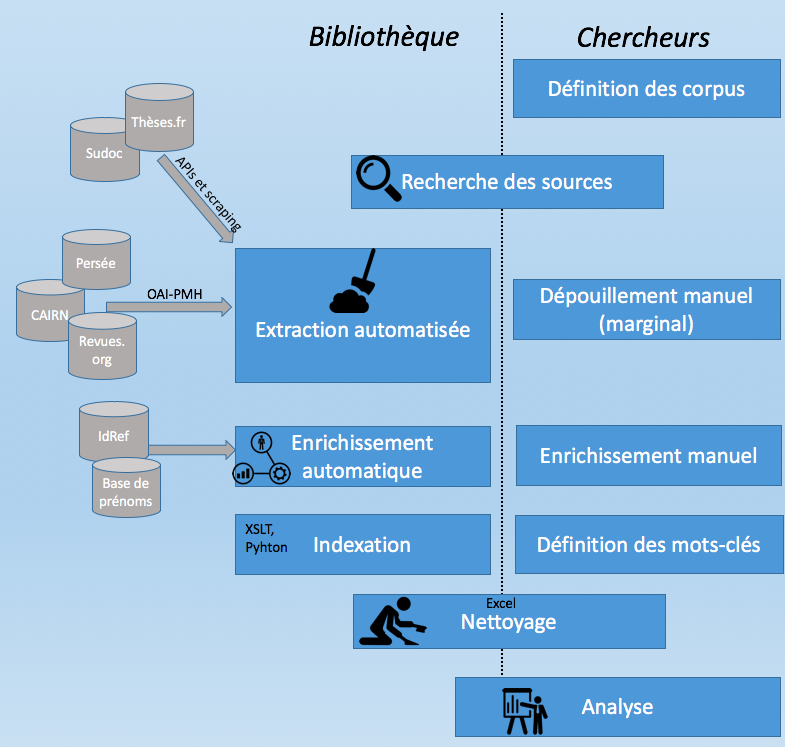
Schéma simplifié du déroulement du projet
Plusieurs sources ont été utilisées:
- Pour les thèses : le portail thèses.fr et le Sudoc (pour les thèses soutenues avant 1985, absentes de thèses.fr) ;
- Pour les revues : les sites Persée, Revues.org et CAIRN, quelques sites de revues isolés.
Notons que certaines revues ont dû être dépouillées manuellement par une stagiaire encadrée par le laboratoire.
La récupération d’information a mobilisé plusieurs techniques:
- Protocole OAI-PMH ;
- API de theses.fr ;
- Web scraping (Sudoc et sites de revues isolées).
Ces données ont été agrégées et dédoublonnées, enrichies et indexées:
- Détermination des disciplines des thèses (les informations étant présentées de manière très hétérogènes dans nos données, nous avons utilisé l’outil OpenRefine pour les harmoniser)
- Ajout du sexe des auteurs (extrait de la base IdREF, ou bien obtenu par croisement avec une liste de prénom) ;
- Indexation thématique et géographique à partir de mots clés présents dans les titres et les résumés. L’indexation géographique a pris en compte les ethnies, les pays, les macro-régions (Afrique de l’Ouest, Sahara…), et certaines formes « alternatives » (variantes de noms de pays, gentilés, capitales et villes principales…).
Puis nettoyées et filtrées (en grande partie manuellement…):
- Suppression de certains types de documents (éditoriaux, nécrologie, notes de lecture) ;
- Suppression d’articles en anglais ;
- Suppression d’articles et de thèses non liés aux sciences humaines (géologie, climatologie, etc.).
Différents outils ont été mobilisés:
Lors des premières étapes, la chaîne d’enrichissement des données a reposé essentiellement sur des traitements en XSLT. Ultérieurement, de petits scripts en Python ont également utilisés. Mais c’est Excel qui a servi d’outil de base pour la compilation, le contrôle qualité et le nettoyage des données. Nous avons également eu recours au logiciel Tableau pour visualiser des données dans une phase intermédiaire du projet.
L’analyse des données
Les données fournies par la BU ont fait l’objet d’une première analyse rapide afin de contrôler la qualité des données, puis d’une analyse plus approfondie par les membres du GIS, présentée dans la 3e partie (« L’Afrique dans les thèses et les revues ») du livre blanc.

Concernant les thèses, les auteurs ont pu mettre en évidence:
- Une forte progression du nombre de thèses à la fin des années 1970 et dans les années 1980, puis une stabilisation (environ 400 thèses par an sur l’Afrique aujourd’hui) ;
- Une domination du droit et des langues jusqu’aux années 1970, puis une diversification (histoire, géographie, sciences économiques, sciences politiques, anthropologie) ;
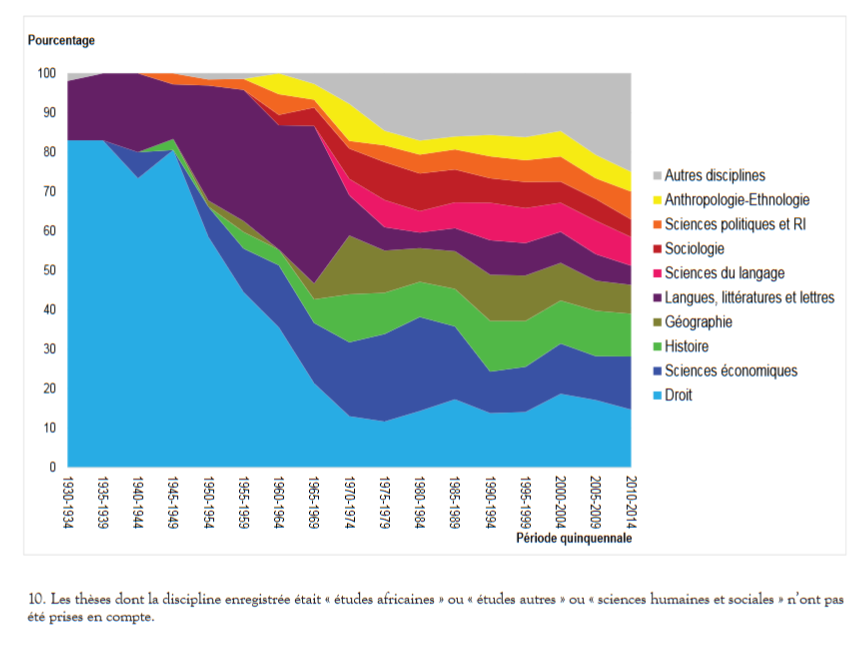
Évolution de la part des disciplines les plus représentées (fig 3. p. 78)
- Une suprématie francilienne et parisienne : Près de la moitié des thèses sur l’Afrique ont été soutenues dans une université francilienne, principalement dans Paris intra-muros. Bordeaux et Aix-Marseille constituent deux pôles secondaires importants ;
- Un sex-ratio très déséquilibré en défaveur des femmes, le différentiel tendant à s’atténuer dans la période la plus récente, mais beaucoup plus lentement pour les directeurs de thèses que pour les doctorants ;
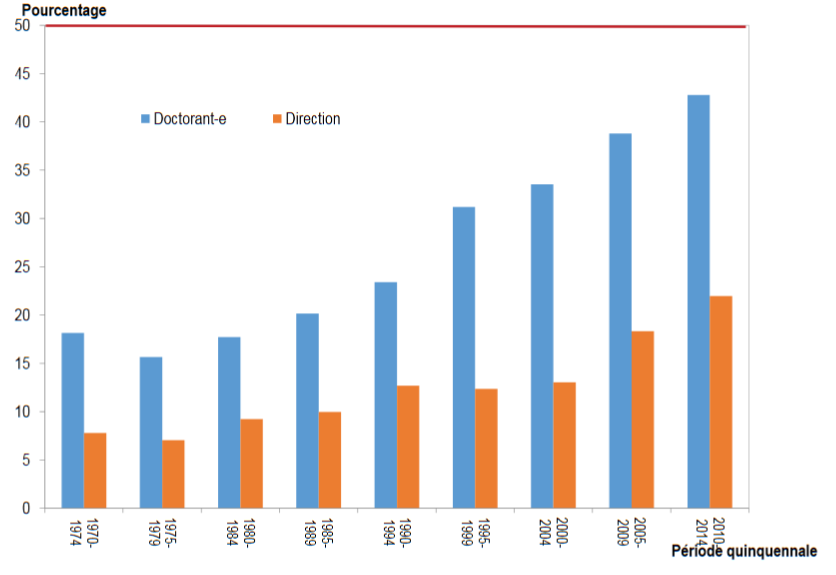
Évolution de la part des femmes (doctorant-e et direction) depuis 1970 (fig 5 p. 80)
- Un sex-ratio très différentié selon les disciplines : 1 doctorante pour 4 ou 4,5 doctorant en droit ou en philosophie (mais la philosophie ne représente que 0,7% des thèse, le sex-ratio est à prendre avec précaution), contre 1 pour 1 en démographie, et 1 directrice de thèse pour 11 à 12 directeurs en sciences économiques et politiques !
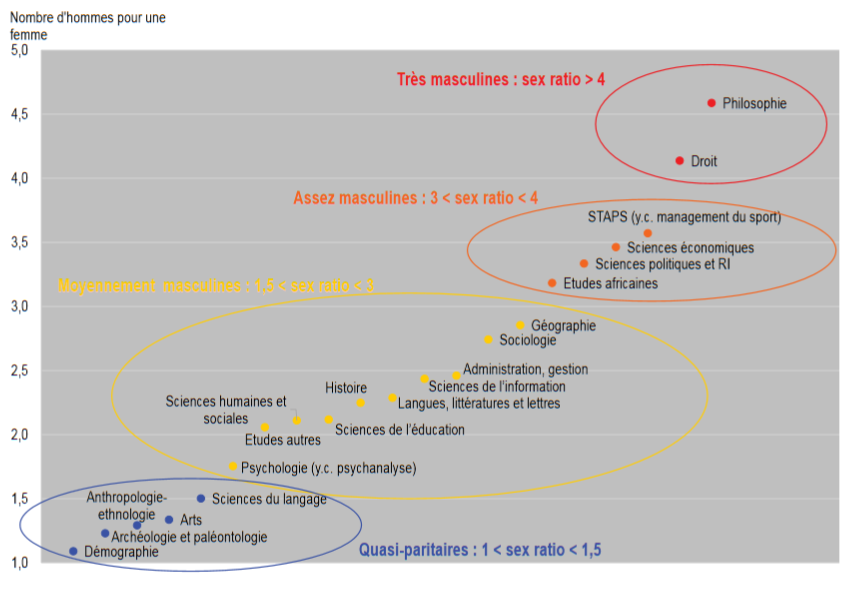
Sex ratio par disciplines (doctorants) (fig 6 p. 82)
D’autres analyses ont porté sur les revues:
- La part des articles consacrés à l’Afrique dans des revues non spécialisées : L’Afrique est bien représentée (19 à 48 % des articles) dans les revues thématiques sur le développement, le Sud, les grandes aires culturelles, les migrations, et dans une moindre part (8 à 23%) dans les revues géographie, d’anthropologie et de démographie. Elle occupe une place réduite dans les revues d’histoire, de droit, d’économie et de sociologie.
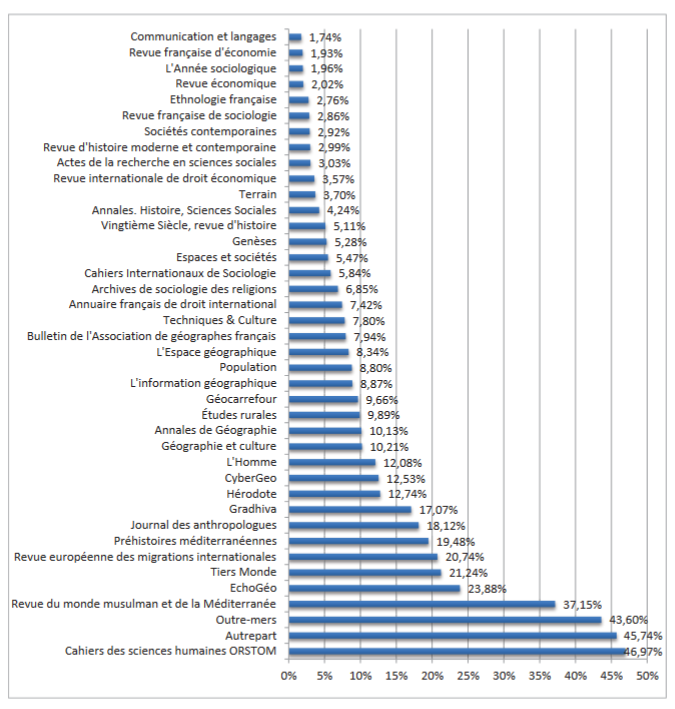
Part de l’Afrique dans des revues généralistes (fig. 1 p. 95)
- L’importance respectives des différentes macro-régions dans les revues spécialisées sur l’Afrique: les articles concernant l’Afrique de l’Ouest (en particulier la Côte d’Ivoire, le Sénégal et le Mali) sont de loin les plus nombreux, mais le nombre d’articles consacrés à l’Afrique australe et l’Afrique de l’Est a fortement progressé au cours de la période (ainsi que ceux consacrés à l’Afrique du Nord, mais il s’agit en partie d’un artéfact statistique du à la prise en compte de la revue Maghreb-Machrek à partir de 2003)
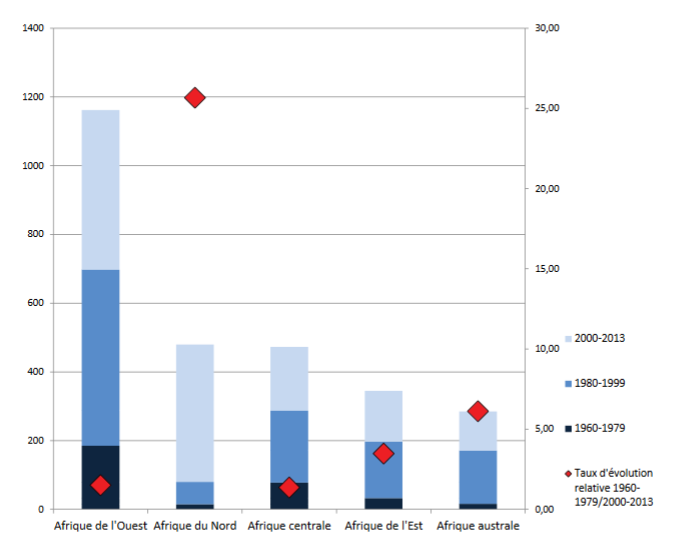
Nombre d’articles par région. Évolution. (fig. 3 p. 99)
- Poids et évolution des différents thèmes dans les revues spécialisées: et surtout leur évolution: dans les années 1960, les articles évoquaient en priorité des sujets liés aux sociétés traditionnelles. Dans les années 2010, cette place est occupée par les sujets liés à la politique et à l’administration. Des thèmes quasiment inexistant il y a 50 ans ont désormais une place importante: la communication, le droit, la sexualité, les problèmes sociaux, les crises, la guerre et la violence.
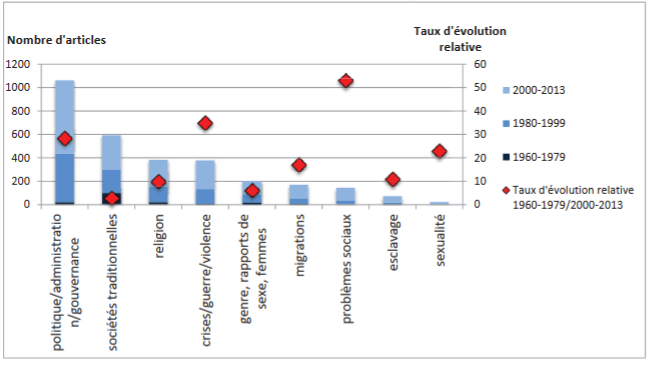
Précautions d’usage
Notre travail, en tant que « producteurs » des données a aussi été d’avertir les chercheuses de la présence de divers biais, dont certains n’ont pas pu être corrigés :
- « Silence documentaire » (documents non intégrés au corpus) lié à des sources lacunaires (certaines revues n’étaient pas en ligne pour des périodes clés, et n’ont pas pu être dépouillées manuellement) et au non-repérage d’articles si les mots clés liés à l’Afrique n’étaient pas présents dans le titre ou le résumé ;
- « Bruit documentaire » (documents intégrés à tort au corpus) lié à la présence de mots clés liés à l’Afrique dans des titres ou résumés d’articles pourtant non liés à l’Afrique, de mots clés ambigus, et à la difficulté d’exclure certains types de documents (nécrologies, éditoriaux, notes de lecture…) ;
- Silence et bruit dans l’indexation des documents intégrés au corpus ;
- Hétérogénéité quantitative et qualitative du corpus: création et disparition de revues, métadonnées de plus en plus précises et détaillées au fil du temps (le taux de résumés disponibles croit fortement à partir des années 1980, ce qui induit mécaniquement un accroissement du nombre de mots clés reconnus) ;
- Importance du nettoyage manuel, et donc possibilité d’erreurs humaines.
Quel bilan?
Concernant la communication avec les chercheuses, notre position d’« extériorité » a pu être un handicap, qui a entraîné quelques malentendus, et un surcroît de travail pour toutes les parties prenantes. Nous avons pu également constater des différences « culturelles » entre bibliothécaires et chercheurs (par exemple, un bibliothécaire fera tout pour conserver les identifiants permettant de recroiser des données, alors qu’une démographe aura le réflexe de les supprimer).
L’idée initiale d’une « extraction automatisée de données » a dû être fortement nuancée, surtout sur un corpus aussi hétérogène. Certaines sources ont dû être dépouillées manuellement, d’autres n’ont pas pu l’être, et les données finalement recueillies ont été plus hétérogènes que prévu, ce qui a entraîné un travail important de nettoyage de notre part et de la part du GIS, et a limité la faisabilité ou la fiabilité de certaines analyses.
Nous avions pensé utiliser certaines sources qui n’ont finalement pas pu être retenues pour des raisons techniques, de qualité et de complétude des données (les premiers essais à partir des données d’Isidore n’ont pas été concluants) ou de disponibilité (un export global des thèses du Sudoc nous aurait fait gagner du temps).
Les méthodes mises en œuvre liaient fortement les phases d’extraction et d’indexation. Ces deux volets gagneraient à être distingués : même si l’extraction est basée sur certains mots-clés, ce ne sont pas forcément ces mots-clés qui doivent servir lors de l’analyse.
Enfin, les outils et méthodes développés n’ont pas été pensées dès le départ pour être réutilisables. Si un projet du même type se représentait, nous chercherions à les rendre plus génériques.
Et après?
La contribution au livre blanc sur les études africaines nous a permis de confirmer notre intuition de départ: les bibliothèques disposent de compétences qui peuvent être utiles à certains projets de recherche.
D’autres expérimentations du même type sont en cours, et seront le sujet de billets à venir.
