HTTBU
Le blog des BU sur les publications électroniques et les données de la recherche
OpenRefine est un logiciel libre et gratuit permettant de nettoyer, préparer et enrichir des données. Il est utilisé dans le monde des bibliothèques mais aussi par des étudiants et chercheurs dans différentes disciplines.
![]()
Avant de pouvoir analyser des données, il est souvent nécessaire de les nettoyer (harmoniser des valeurs hétérogènes, repérer des anomalies, etc.), de les préparer (changement de format, réorganisation des colonnes, etc.), ou de les enrichir.
Vous avez certainement l’habitude de réaliser ces opérations avec un tableur (Excel, Libreoffice, Google Drive…), ou pour certains d’entre-vous avec des scripts rédigés dans différents langages informatiques (R, Python, Bash…). Mais il existe des outils spécifiques, plus simples d’utilisation que les langages de script, et possédant des fonctions absentes des tableurs traditionnels. Openrefine est l’un d’eux.
Ce 23 octobre, nous avons proposé un atelier de découverte de cet outil au LearningCentre SophiaTech. Pour toutes les personnes qui n’ont pas pu y assister, voici le support créé pour l’occasion :
Si vous souhaitez en savoir plus sur cet outil ou d’autres du même type, n’hésitez pas à nous contacter : donnees-scd@unice.fr
Pour Universalis, la rentrée rime avec nouveautés. Depuis le 1er septembre, la version en ligne de cette encyclopédie propose une interface et des fonctionnalités nouvelles. A cette occasion, nous vous proposons un focus sur cette ressource électronique.
Universalis, c’est la possibilité de faire des recherches en ligne dans 3 outils :

Retrouvez ici des tutoriels pour connaître toutes les astuces de recherche dans Universalis.
Et pour plus d’informations, n’hésitez pas à écrire à docelec@unice.fr.
Dans un billet précédent, nous expliquions, avec un dessin même, pourquoi le plus souvent il n’y avait aucun obstacle juridique à déposer des articles dans une archive ouverte, y compris ceux déjà publiés…
Depuis la loi pour une république numérique du 8 octobre 2016, c’est encore plus simple : l’article 30 stipule en effet que les articles scientifiques peuvent être diffusés en libre accès par leur auteur, même en présence d’un contrat de cession des droits.

Un cadenas ouvert, symbole de l’open access, qui avance grâce aux nouvelles dispositions législatives
Évidemment, il y a quelques subtilités, sinon ce ne serait pas drôle :
N’hésitez donc plus à déposer tous vos articles sur Hal-Unice. Si toutefois un doute vous habite, et que vous tenez absolument à être dans la légalité la plus complète, pas besoin de schéma cette fois : les bibliothécaires de Lilliad ont développé WillO, un outil en ligne simple et pratique, pour vous aider à déterminer si vous pouvez déposer vos articles.

Et pour aller plus loin :
Vous pouvez désormais accéder au site Mediapart depuis les postes informatiques et le wifi de l’Université.

Qu’est-ce que Mediapart ?
Mediapart est un site d’information payant qui a ouvert le 16 mars 2008 et qui est structuré en deux parties :
Parmi les membres fondateurs et actuellement président et directeur de la publication, Edwy Plenel en est la figure la plus médiatique. Ancien journaliste et directeur de la rédaction au Monde (respectivement 1980-2005 et 1996-2005) il est souvent le porte-parole du site sur d’autres médias.
Site d’information et d’investigation, Mediapart s’est notamment distingué en révélant des affaires politiques telles l’affaire Cahuzac et l’affaire Woerth-Bettencourt.
Son indépendance hautement revendiquée s’appuie sur le modèle payant (par abonnement) qui est censé le soustraire aux pressions des annonceurs.
La BU propose 4 accès simultanés depuis des ordinateurs et le wifi de l’Université (reconnaissance sur adresse IP, pas d’accès distant) et à partir des liens présents sur ce billet et sur le site des BU.


Pour plus de renseignements : docelec@unice.fr
Dans le cadre de la subvention Collex 2016 du ministère de l’Enseignement Supérieur et de la Recherche la BIU Santé (Paris Descartes) a négocié l’achats d’ebooks auprès des éditeurs Wiley et Elsevier.
Ces collections sont mises à disposition de l’ensemble des usagers autorisés d’une quarantaine de bibliothèques universitaires de médecine.
L’offre est ainsi constituée :
Profitez-en et venez consulter ces collections !

Cette année 2017 voit peu de changements s’opérer au niveau des ressources électroniques. Mais ne soyez pas déçus, c’est plutôt une bonne nouvelle !
En effet l’offre reste quasiment identique qu’en 2016, et au vu de l’évolution constante du coût des ressources électroniques, il y a plutôt de quoi êtr e satisfait : chaque membre de l’Université bénéficie ainsi toujours d’un accès, sur place et à distance, à une documentation numérique riche et complète.
e satisfait : chaque membre de l’Université bénéficie ainsi toujours d’un accès, sur place et à distance, à une documentation numérique riche et complète.
Nous enregistrons un seul désabonnement : celui de Publie.net, plateforme de livres électroniques en littérature contemporaine. Le changement d’offre de l’éditeur nous a contraint à ne pas renouveler notre abonnement pour des raisons techniques principalement.
Au rayon nouveautés :
Pour avoir plus d’informations sur nos ressources en ligne (typologie, accès…), venez consulter le portail des BU ! Nous vous invitons également à participer aux Journées e-docs que nous organisons la semaine du 27 mars à la BU LASH Bosco. Des ateliers de présentation de ressources électroniques vous seront proposés. N’hésitez pas à nous faire part de vos besoins à docelec@unice.fr. Nous pouvons adapter nos ateliers en fonction de vos demandes.
Enfin les bibliothèques sont à votre disposition pour vous procurer les documents qui ne font pas partie de nos collections par le service du Prêt entre bibliothèques.
A très bientôt !
Les données de la recherche sont précieuses, pour toutes les raisons exposées dans un premier billet. C’est en particulier le cas lorsque leur reproduction est impossible ou difficile (car coûteuse, complexe ou longue) et que leur intérêt potentiel pour la science ou pour la société dépasse le contexte de leur constitution. Il est donc important de les gérer et souhaitable de les partager.
La gestion des données (data management) désigne au sens large l’ensemble des activités facilitant :
La diffusion des données peut se faire quant à elle :
Il est en théorie envisageable de bien gérer des données sans pour autant les partager avec des tiers. Par contre, l’inverse n’est pas vrai : pour pouvoir diffuser des données, encore faut-il les avoir au préalable conservées, décrites et documentées. Les financeurs de la recherche, dont l’objectif est de favoriser le partage des données, préconisent donc également l’adoption de bonnes pratiques concernant leur gestion.
Quel que soit l’ampleur du travail, du mémoire de master à la collaboration internationale impliquant des centaines de chercheurs, une perte ou une altération des données peut avoir des conséquences dramatiques pour le projet.
Un accès non autorisé aux données peut également être dangereux pour le projet, mais aussi pour des tierces personnes, en particulier s’il s’agit de données confidentielles ou personnelles. La collecte et le traitement des données personnelles obéit à une réglementation spécifique, appelée à évoluer en 2018, qu’a présentée le correspondant informatique et liberté de l’UNS lors d’une journée d’étude le 23 juin dernier.
Plus généralement, le guide « Pratiquer une recherche intègre et responsable » du comité d’éthique du CNRS (2e édition de décembre 2016) fait de la fiabilité et de la traçabilité des données produites et des traitements réalisés une bonne pratique nécessaire à la fiabilité du travail de recherche. Cela passe en sciences dures par la tenue d’un cahier de laboratoire, qui permet de faciliter le repérage des fraudes, de répondre aux demandes de vérification des relecteurs d’un article, et de sécuriser juridiquement la recherche en fournissant une preuve d’antériorité des résultats.
Au-delà d’une bonne gestion des données, dont l’intérêt est assez évident, quels sont les enjeux spécifiques du partage des données ?
Une première série d’arguments sont d’ordre scientifique: améliorer la qualité de la recherche, sa visibilité et son impact, et faciliter de nouvelles recherches. Ils sont à replacer dans une logique générale de « science ouverte » : diffusion libre des articles, des données, du code informatique, des algorithmes, des protocoles, transparence de l’évaluation des résultats par les pairs, implication du public dans certaines recherches.

Différents volets de la science ouverte d’après le projet FOSTER
Revenons rapidement sur ces différents points :
Améliorer la qualité et la transparence de la recherche passe par une meilleure reproductibilité des expériences et des analyses. C’est un sujet brûlant en psychologie, en biologie et dans bien d’autres disciplines (voir ce manifeste paru il y a quelques jours dans une revue du groupe Nature). On distingue la « réplication » complète d’une étude, de la collecte des données au résultat final, souvent impossible, et la « reproduction » des résultats à partir des données brutes.
La diffusion des données renforce la visibilité et l’impact d’une étude. Statistiquement, les articles accompagnés de données sont plus cités que les autres (sélection d’articles sur le sujet).
Enfin elle permet de faire avancer plus vite la science :
La réutilisation de données est déjà bien établie en génétique ou en astronomie, mais encore balbutiante dans d’autres disciplines. En sciences sociales, elle est par exemple une pratique courante au Royaume-Uni, mais nettement plus marginale en France.
D’autres arguments sont d’ordre socio-économiques, politiques ou patrimoniaux:
Le partage et la réutilisation des données de la recherche sont encore loin d’être généralisés. Cela s’explique par différentes objections, qui sont de différents ordres.
Les objections pratiques sont multiples :
L’organisation traditionnelle de la recherche et de la communication scientifique ne favorise pas le partage :
Un partage trop rapide et non préparé peut avoir des effets négatifs :
Les réticences les plus profondes sont liées à la nature même des processus de recherche :
Enfin des questions juridiques et éthiques sont à prendre en considération :
Comment répondre à ces enjeux tout en tenant compte de ces freins? Vous le saurez dans le prochain épisode!
En attendant, quelques liens pour aller plus loin si le sujet vous intéresse :
Pour s’informer
Pour se former
Un nombre croissant de revues scientifiques demandent aux auteurs de rendre disponibles les données analysées dans leurs articles. C’est par exemple le cas du prestigieux groupe Nature. Ce mouvement international, né dans des disciplines productrices et réutilisatrices de grandes quantité de données (astrophysique, physique des hautes énergies, génomique…), s’étend peu à peu à d’autres domaines, comme les essais cliniques, et se généralise sous l’impulsion d’universités, d’agences de financement de la recherche, de gouvernements et d’organisations scientifiques internationales.
Comment expliquer cette évolution, et comment l’accompagner?
La notion de données fait partie de l’ »outillage intellectuel » standard des sciences de la matière et du vivant, et de certaines sciences sociales. Mais un informaticien, un statisticien, un sociologue ou un physicien se font-ils la même idée de leurs « données »? Plusieurs définitions des « données de la recherche » ont été proposées depuis une dizaine d’années, mais elles ont été formulées par différents organismes dans un but opérationnel, et non à l’issue d’une réflexion philosophique. Une des plus influente a été proposée en 2007 dans les Principes et lignes directrices de l’OCDE pour l’accès aux données de la recherche financée sur fonds publics :
les «données de la recherche » sont définies comme des enregistrements factuels (chiffres, textes, images, sons) utilisés comme source principales pour la recherche scientifique et généralement reconnus par la communauté scientifique comme nécessaires pour valider les résultats de la recherche. Un ensemble de données de recherche constitue une représentation systématique et partielle du sujet faisant l’objet de la recherche »
Notons que cette définition fortement marquée par les sciences dures devrait être adaptée pour s’appliquer pleinement aux sciences humaines et sociales.
Les données se présentent aujourd’hui le plus souvent sous forme numérique, mais ce n’est pas une obligation, et le retraitement de données anciennes impose bien souvent la manipulation de documents physiques.
Elles sont très diverses en terme de format, de volumétrie, et de méthode de constitution ou de collecte.
Toutes ne sont pas créées dans le cadre d’un projet spécifique, car elles peuvent également avoir pour origine :
On distingue fréquemment plusieurs « niveaux » de données, par exemple :
Historiquement, les données exploitées par les chercheurs pouvaient être issues :
Cependant l’essor de l’informatique et de l’instrumentation a permis progressivement (depuis quelques décennies ou quelques années selon les disciplines) :
Mais les enjeux liés aux données de la recherche sont aussi économiques et sociétaux, car les données sont devenues stratégiques pour nombre d’entreprises, les pouvoirs publics, et la société dans son ensemble. Cela rend possibles de nouvelles formes de partenariats centrés sur les données entre le monde de la recherche et la société :
Une des missions des bibliothèques universitaires consiste à soutenir la recherche, ce qui implique de :
Or les données scientifiques tendent à devenir un objet communicable et valorisable au même titre qu’une publication. Les bibliothèques des grandes universités de recherche étrangères ont donc investi ce nouveau champ, en travaillant conjointement avec les services informatique, l’administration de la recherche, et les chercheurs eux-mêmes (voir par exemple à Edinburgh ou dans le Wisconsin). Les universités françaises sont moins avancées, mais plusieurs BU ont des projets de cette nature, et des services ont été développés par l’INIST-CNRS et l’INRA.
Voici pourquoi nous menons depuis l’an dernier une réflexion sur ce sujet, que nous partagerons avec vous sur HTTBU. Après ce premier billet introductif, nous aborderons :
Si vous souhaitez en savoir plus, ou si vous avez des questions sur un point particulier, vous pouvez nous contacter en écrivant à donnees-scd@unice.fr.
Entre l’été 2014 et l’automne 2015, la BU a collaboré avec un groupe de chercheurs réalisant un livre blanc sur les études africaines. Nous reviendrons dans ce (long) billet sur la nature et le cadre de cette intervention, et les enseignements que nous en avons tiré.
[Billet mis à jour le 9/12/2016 : ajout de l’étape d’harmonisation des disciplines des thèses avec l’outil Openrefine]
Différents laboratoires de sciences humaines et sociales français consacrent tout ou partie de leurs travaux à des aires culturelles spécifiques. Sous l’égide de l’institut des SHS du CNRS, quatre GIS (groupements d’intérêt scientifique) fédèrent les compétences et encouragent les partenariats entre spécialistes de l’Afrique, de l’Asie et du Pacifique, des Amériques, et du Moyen orient et du monde musulman. Le GIS sur les études africaines en France regroupe 33 laboratoires, dont l’Unité de Recherche Migrations et Société (URMIS), spécialisée dans l’étude des migrations et des relations interethniques, qui dépend à la fois des université de Nice et Paris-Diderot, de l’Institut de recherche et du développement, et du CNRS.

À la demande du CNRS, ces quatre GIS ont produit des « livres blancs » faisant le bilan des études dans leurs domaines respectifs. Une synthèse de ces livres blanc a été réalisée et une journée d’étude organisée à Paris le 24 octobre dernier. Les livres blancs sont accessibles librement et constituent des documents fort utiles pour faire le point sur les équipes de recherche, les moyens humains et les centres de documentation spécialisés concernant le Moyen-Orient et les mondes musulmans, les Amériques, l’Asie et le Pacifique, et l’Afrique.
À l’été 2014, Mmes Streiff-Fénart, Ballarin et Lesclingand, chercheuses de l’URMIS impliquées dans la rédaction du livre blanc sur les études africaines, ont pris contact avec les collègues de la BU Saint Jean d’Angély, qui avaient déjà noué des relations de longue date avec leur laboratoire. Elles souhaitaient collecter des informations sur les thèses et les articles concernant l’Afrique. Leur demande a été essentiellement étudiée par le département d’ingénierie documentaire des BU, qui leur a proposé d’extraire et d’enrichir semi-automatiquement des données bibliographiques à partir de différentes sources.
Nous avons fourni trois jeux de données, concernant
Les informations fournies étaient des « métadonnées » (auteur, titre, revue, date, résumé, sujet), et non le texte intégral des articles.
Ce travail a mobilisé les compétences de plusieurs collègues chargés de la documentation électronique et de l’ingénierie documentaire (pour les sources numériques et les aspects techniques), ou en poste dans les BU Saint-Jean d’Angély et Droit (pour les sources imprimées). Il a nécessité une collaboration régulière avec les chercheuses (6 réunions et de nombreux échanges) afin de préciser leurs besoins (liste des revues, critères d’inclusion ou d’exclusion des articles et des thèses, mots clés thématiques et géographiques) et la répartition du travail. Enfin il s’est avéré très prenant tant pour nous que pour les chercheuses, notamment dans la phases de nettoyage des données.
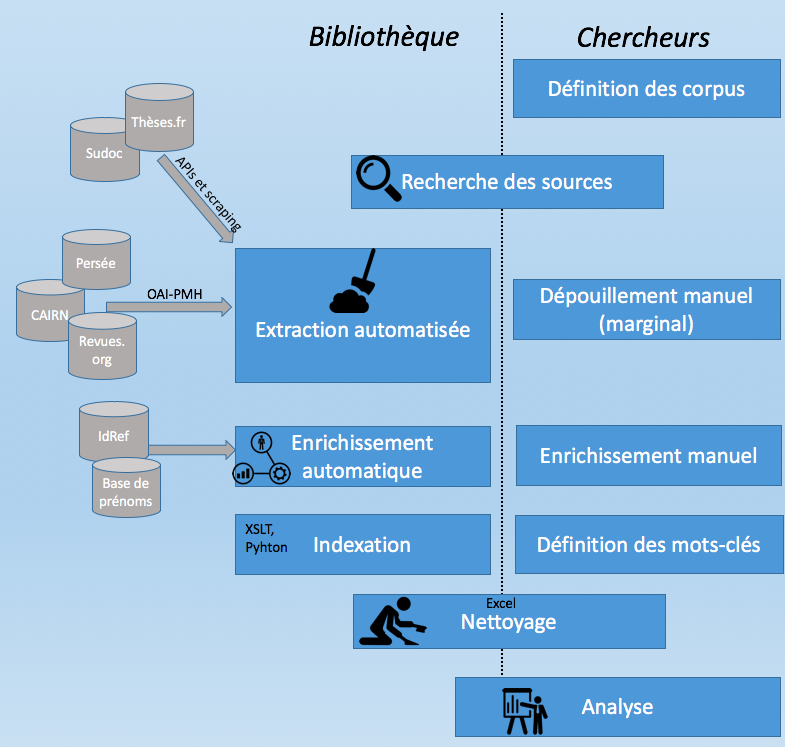
Schéma simplifié du déroulement du projet
Plusieurs sources ont été utilisées:
Notons que certaines revues ont dû être dépouillées manuellement par une stagiaire encadrée par le laboratoire.
La récupération d’information a mobilisé plusieurs techniques:
Ces données ont été agrégées et dédoublonnées, enrichies et indexées:
Puis nettoyées et filtrées (en grande partie manuellement…):
Différents outils ont été mobilisés:
Lors des premières étapes, la chaîne d’enrichissement des données a reposé essentiellement sur des traitements en XSLT. Ultérieurement, de petits scripts en Python ont également utilisés. Mais c’est Excel qui a servi d’outil de base pour la compilation, le contrôle qualité et le nettoyage des données. Nous avons également eu recours au logiciel Tableau pour visualiser des données dans une phase intermédiaire du projet.
Les données fournies par la BU ont fait l’objet d’une première analyse rapide afin de contrôler la qualité des données, puis d’une analyse plus approfondie par les membres du GIS, présentée dans la 3e partie (« L’Afrique dans les thèses et les revues ») du livre blanc.
Concernant les thèses, les auteurs ont pu mettre en évidence:
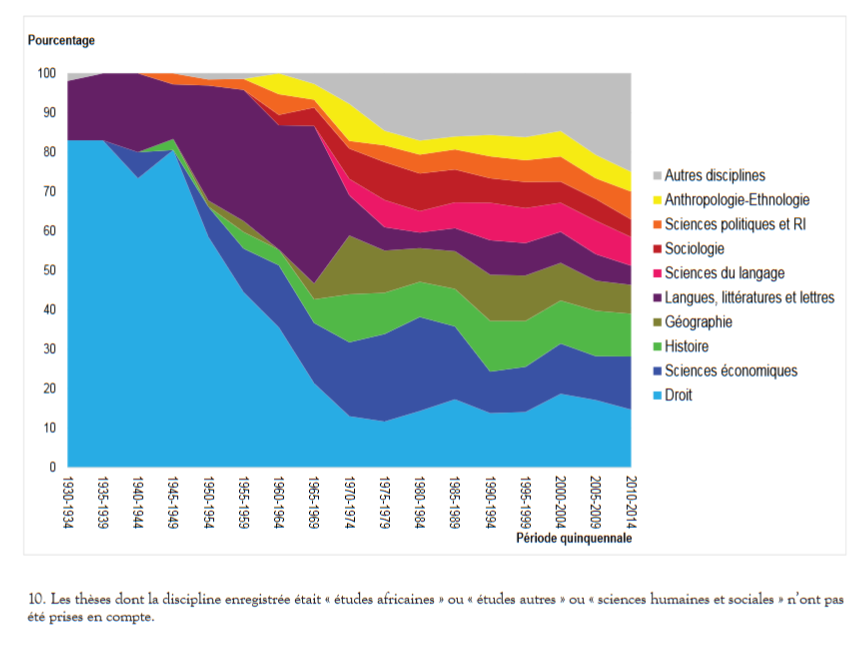
Évolution de la part des disciplines les plus représentées (fig 3. p. 78)
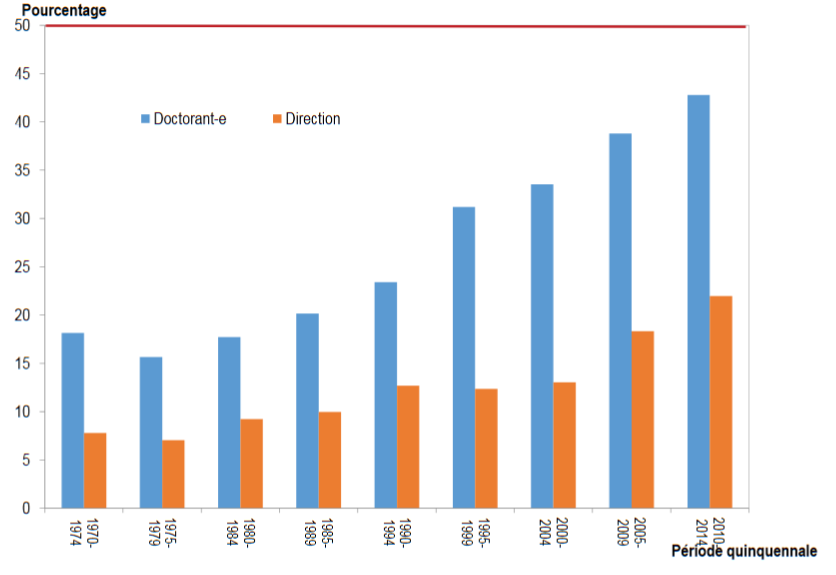
Évolution de la part des femmes (doctorant-e et direction) depuis 1970 (fig 5 p. 80)
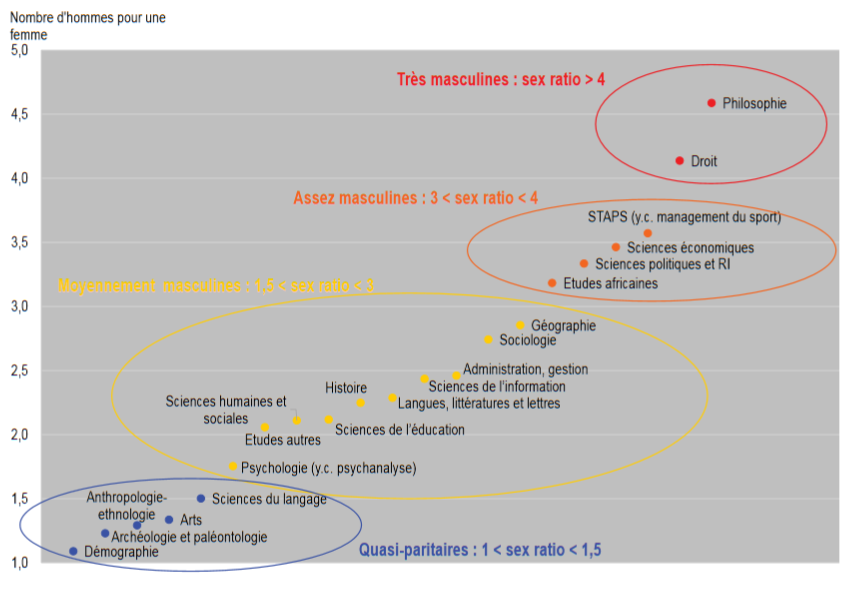
Sex ratio par disciplines (doctorants) (fig 6 p. 82)
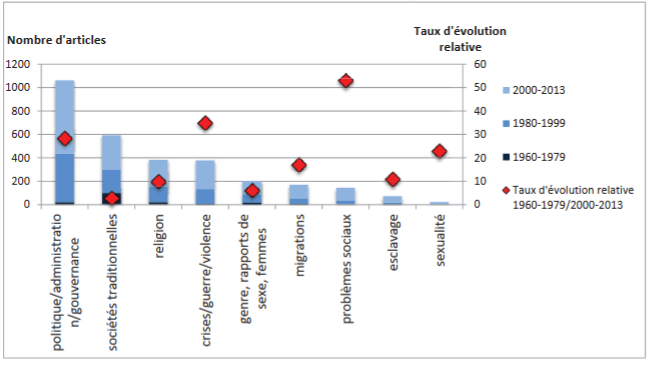
D’autres analyses ont porté sur les revues:
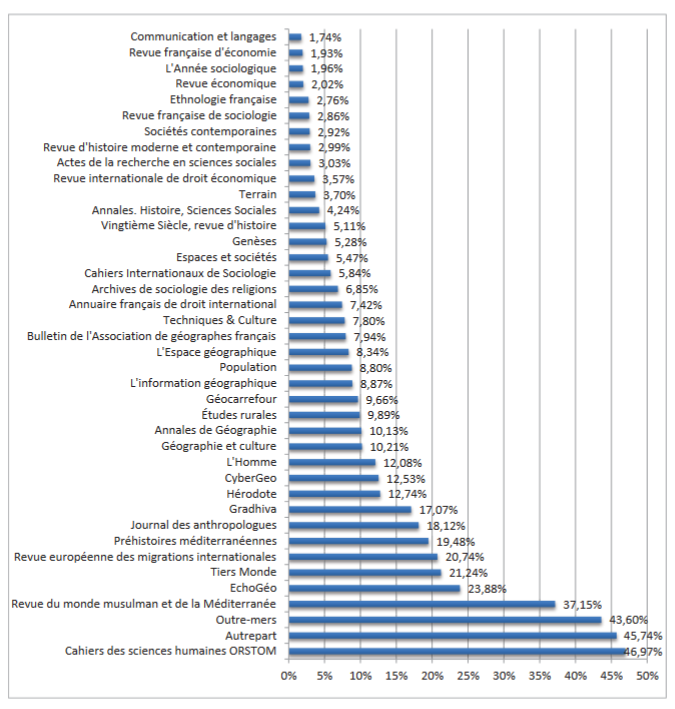
Part de l’Afrique dans des revues généralistes (fig. 1 p. 95)
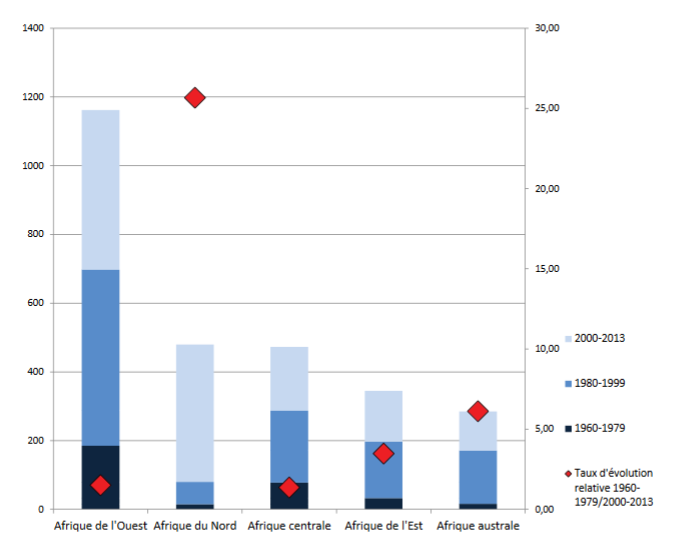
Nombre d’articles par région. Évolution. (fig. 3 p. 99)
Notre travail, en tant que « producteurs » des données a aussi été d’avertir les chercheuses de la présence de divers biais, dont certains n’ont pas pu être corrigés :
Concernant la communication avec les chercheuses, notre position d’« extériorité » a pu être un handicap, qui a entraîné quelques malentendus, et un surcroît de travail pour toutes les parties prenantes. Nous avons pu également constater des différences « culturelles » entre bibliothécaires et chercheurs (par exemple, un bibliothécaire fera tout pour conserver les identifiants permettant de recroiser des données, alors qu’une démographe aura le réflexe de les supprimer).
L’idée initiale d’une « extraction automatisée de données » a dû être fortement nuancée, surtout sur un corpus aussi hétérogène. Certaines sources ont dû être dépouillées manuellement, d’autres n’ont pas pu l’être, et les données finalement recueillies ont été plus hétérogènes que prévu, ce qui a entraîné un travail important de nettoyage de notre part et de la part du GIS, et a limité la faisabilité ou la fiabilité de certaines analyses.
Nous avions pensé utiliser certaines sources qui n’ont finalement pas pu être retenues pour des raisons techniques, de qualité et de complétude des données (les premiers essais à partir des données d’Isidore n’ont pas été concluants) ou de disponibilité (un export global des thèses du Sudoc nous aurait fait gagner du temps).
Les méthodes mises en œuvre liaient fortement les phases d’extraction et d’indexation. Ces deux volets gagneraient à être distingués : même si l’extraction est basée sur certains mots-clés, ce ne sont pas forcément ces mots-clés qui doivent servir lors de l’analyse.
Enfin, les outils et méthodes développés n’ont pas été pensées dès le départ pour être réutilisables. Si un projet du même type se représentait, nous chercherions à les rendre plus génériques.
La contribution au livre blanc sur les études africaines nous a permis de confirmer notre intuition de départ: les bibliothèques disposent de compétences qui peuvent être utiles à certains projets de recherche.
D’autres expérimentations du même type sont en cours, et seront le sujet de billets à venir.
 SCD BU Université Nice Sophia Antipolis
2017 |
Propulsé par WordPress et Mystique thème par digitalnature
SCD BU Université Nice Sophia Antipolis
2017 |
Propulsé par WordPress et Mystique thème par digitalnature
