Le blog des BU sur les publications électroniques et les données de la recherche
Publications électroniques UNS
Cet utilisateur n'a pas partagé ses informations de profil
Articles par Publications électroniques UNS
50 ans d’activité scientifique, 50 ans d’open access, 50 ans de collaborations
011 années
par Publications électroniques UNS.
dans Zoom sur...
J’ai décrit dans un précédent billet le contenu de HAL-Unice, en terme de volumétrie.
Rappelons que les constatations sont faites pour le corpus constaté, c’est-à-dire les archives déposées dans HAL, et les articles signalés par les chercheurs dans HAL. Ce corpus ne prend donc en compte
- ni l’ensemble de la publication scientifique de l’Université
- ni même l’ensemble de la politique d’open access des structures de recherche de l’Université, car il existe d’autres dépôts d’archives en France et dans le monde
Si les archives déposées dans ArXiv par des chercheurs français se retrouvent automatiquement dans HAL, ce n’est pas le cas par exemple de CiteSeerx, dans lequel on trouvera de nombreux articles déposés par des chercheurs affiliés à l’Université de Nice, qui ne sont pas du tout signalés dans HAL.
Par ailleurs les disciplines sont inégalement représentées du fait aussi des pratiques de publication des chercheurs, directement liées aux conditions d’évaluation (ex : publier un ouvrage compte-t-il ou non ?) et aux pratiques des communautés scientifiques et des maisons d’édition.
Pour les archives qui y sont déposées ou signalées, HAL-Unice constitue-t-il un bon corpus pour donner à voir toutes les collaborations entre laboratoires et structures de recherche ? On peut toujours essayer.
A chaque notice est associée l’affiliation du ou des auteurs. Cette affiliation est presque toujours exprimée de manière double, quand elle désigne le nom du labo et l’université de rattachement de celui-ci ; ou triple quand il s’agit d’une UMR, rattachée à la fois au CNRS et à l’Université.
En moyenne, une ressource est affiliée à 6 structures de recherche, avec un maximum de 56 pour l’ensemble étudié…
On peut donc considérer que chaque article est le fruit d’une collaboration entre les structures de recherche auxquelles appartiennent leurs auteurs. Chaque article donne à voir une collaboration entre deux structures de recherche.
De manière plus globale (c’est-à-dire en regardant les liens entre les structures de recherche, non pas notice par notice mais pour l’ensemble du corpus), on découvre tout un réseau continu entre les établissements.

Explications
Les données qui ont permis de générer ce graphe :
A chaque article est associé un ou plusieurs « sets ». Quand il y a plusieurs affiliations d’établissements, cela apparaît sous la forme :
<collection>UNICE</collection> <collection>SHS</collection> <collection>EPHE</collection> <collection>INRAP</collection> <collection>CNRS</collection> <collection>UNIV-TLSE2</collection> <collection>CEPAM</collection> <collection>TRACES</collection> <collection>CBAE</collection> <collection>UNIV-MONTP3</collection> <collection>UMR5140</collection> <collection>UNIV-AMU</collection> <collection>MMSH</collection> <collection>LADIR</collection> <collection>UPMC</collection>
On a considéré qu’à travers cette liste, chaque structure de recherche était liée à chacune des autres, ce qui a généré toutes les paires possibles :
UNICE;SHS / UNICE;EPHE / UNICE;INRAP / UNICE;CNRS / UNICE;UNIV-TLSE2 / UNICE;CEPAM / UNICE;TRACES / UNICE;CBAE / UNICE;UNIV-MONTP3 / UNICE;UMR5140 / UNICE;UNIV-AMU / UNICE;MMSH / UNICE;LADIR / UNICE;UPMC / SHS;EPHE / SHS;INRAP / SHS;CNRS / SHS;UNIV-TLSE2 / SHS;CEPAM / SHS;TRACES / SHS;CBAE / SHS;UNIV-MONTP3 / SHS;UMR5140 / SHS;UNIV-AMU / SHS;MMSH / SHS;LADIR / SHS;UPMC / EPHE;INRAP / EPHE;CNRS / EPHE;UNIV-TLSE2 / EPHE;CEPAM / EPHE;TRACES / EPHE;CBAE / EPHE;UNIV-MONTP3 / EPHE;UMR5140 / EPHE;UNIV-AMU / EPHE;MMSH / EPHE;LADIR / EPHE;UPMC / INRAP;CNRS / INRAP;UNIV-TLSE2 / INRAP;CEPAM / INRAP;TRACES / INRAP;CBAE / INRAP;UNIV-MONTP3 / INRAP;UMR5140 / INRAP;UNIV-AMU / INRAP;MMSH / INRAP;LADIR / INRAP;UPMC / CNRS;UNIV-TLSE2 / CNRS;CEPAM / CNRS;TRACES / CNRS;CBAE / CNRS;UNIV-MONTP3 / CNRS;UMR5140 / CNRS;UNIV-AMU / CNRS;MMSH / CNRS;LADIR / CNRS;UPMC / UNIV-TLSE2;CEPAM / UNIV-TLSE2;TRACES / UNIV-TLSE2;CBAE / UNIV-TLSE2;UNIV-MONTP3 / UNIV-TLSE2;UMR5140 / UNIV-TLSE2;UNIV-AMU / UNIV-TLSE2;MMSH / UNIV-TLSE2;LADIR / UNIV-TLSE2;UPMC / CEPAM;TRACES / CEPAM;CBAE / CEPAM;UNIV-MONTP3 / CEPAM;UMR5140 / CEPAM;UNIV-AMU / CEPAM;MMSH / CEPAM;LADIR / CEPAM;UPMC / TRACES;CBAE / TRACES;UNIV-MONTP3 / TRACES;UMR5140 / TRACES;UNIV-AMU / TRACES;MMSH / TRACES;LADIR / TRACES;UPMC / CBAE;UNIV-MONTP3 / CBAE;UMR5140 / CBAE;UNIV-AMU / CBAE;MMSH / CBAE;LADIR / CBAE;UPMC / UNIV-MONTP3;UMR5140 / UNIV-MONTP3;UNIV-AMU / UNIV-MONTP3;MMSH / UNIV-MONTP3;LADIR / UNIV-MONTP3;UPMC / UMR5140;UNIV-AMU / UMR5140;MMSH / UMR5140;LADIR / UMR5140;UPMC / UNIV-AMU;MMSH / UNIV-AMU;LADIR / UNIV-AMU;UPMC / MMSH;LADIR / MMSH;UPMC / LADIR;UPMC
L’ensemble de ces paires a ensuite été chargée dans Gephi, pour obtenir une clusterisation et une répartition spatiale qui a rapproché les établissements travaillant le plus souvent ensemble, et attribuant (ou tentant d’attribuer) des couleurs par sous-groupes.
Le corpus considéré de manière « brute » (sans sélection des données traitées) laisse entendre qu’il n’y a pas vraiment de sous-ensembles nets : aucun groupe de noeuds ne se détache vraiment des autres, il y a plutôt, dans l’activité de publication, un continuum de la recherche.
Limites et reprises
On peut voir d’emblée au moins 3 limites aux données en entrée :
- il y a un trop grand nombre de noeuds (1177 « établissements » distincts) et de liens (31.000 liens distincts) pour obtenir un graphe satisfaisant
- Les données en entrée ne sont pas propres : les collections « SHS », « AO-ECONOMIE », ne sont pas des établissements
- Les universités sont sur le même plan que les laboratoires : donc toutes les universités sont finalement liées entre elles (via leurs laboratoires, y compris ceux qui ne travailleraient que dans un champ disciplinaire bien précis, et avec une liste fermée d’autres laboratoires du même champ disciplinaire).
Cette absence de partition en sous-groupes est donc inévitable tant qu’on prend en compte les universités.
Voici donc 2 autres tentatives pour voir si une visualisation différente pourrait se dégager :
1. Données en entrée nettoyées des mentions de domaines de recherche, et des noms d’Université (ou CNRS)
Dans le graphe ci-dessous, les universités et le CNRS ont été retirées. Ne sont conservées que les structures de recherche de type Laboratoire ou Institut.
On passe ainsi à 1063 établissements (nœuds) et 18.000 liens :

Certains sous-ensembles se dégagent mieux (le graphe est moins uniforme) : SophiaTech et l’INRIA avec le labo de math J.A. Dieudonné ; les laboratoires de l’OCA (en vert) – et juste à côté, dans un vert légèrement différent, des structures de recherche en SHS (la plus visible sur le graphe étant le CEPAM).
Pourtant de nombreux liens existent manifestement entre ces groupes, et on continue d’observer le continuum évoqué plus haut.
2. Données en entrée : les liens les plus importants
Une méthode supplémentaire pour « nettoyer » les données consiste à évacuer toutes les collaborations trop ponctuelles (1 à 5 occurrences), pour ne conserver que celles qui se sont répétées pour la rédaction de plusieurs archives déposées.
Ci-dessous le graphe exploitant les collaborations répétées au moins 6 fois dans le corpus étudié (404 structures de recherche, 2830 liens) :

Le risque est évidemment de faire disparaître des laboratoires très présents dans le corpus initial, mais qui travaillent ponctuellement avec un grand nombre d’autre laboratoires très diversifiés : chaque lien concernant ce labo apparaissant peu de fois, il finit par disparaître complètement du graphe…
661 structures sont évacuées suite à ce filtre supplémentaire, mais aucune ne relève de l’Université Nice Sophia Antipolis (qui est le sujet de ce billet).
Ultime remarque : les SHS semble avoir disparu dans la masse. Du coup, voici un graphe rien que pour eux.

Celui-ci est dynamique et permet notamment de filtrer sur le nom d’un labo (via le petit moteur de recherche dans l’en-tête), pour voir identifier ses partenaires et sa position dans le réseau.
Pourquoi dans le graphe global ne voit-on presque plus que des structures de recherche en sciences ? Parce que dans les archives déposées ou signalées dans HAL-Unice, les SHS indiquent beaucoup moins d’affiliations : les collaborations entre labos sont en moins grand nombre :
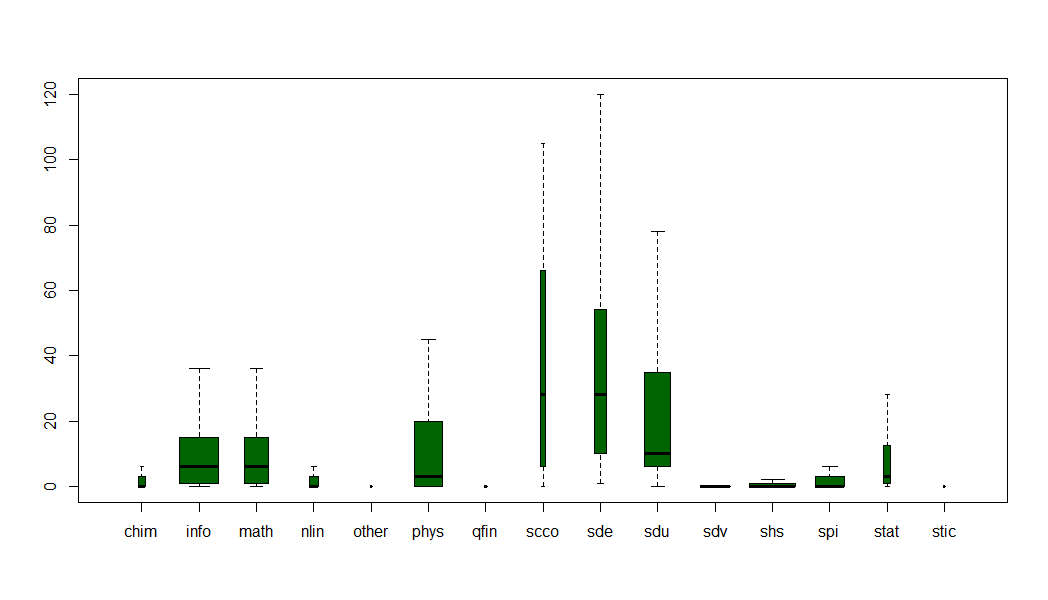
Comment lire ce graphique ?
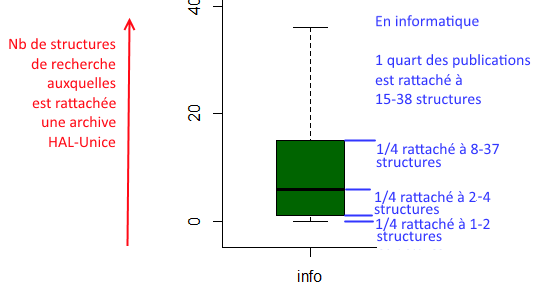
- Pour chaque discipline, on voit le nombre d’établissements auxquelles sont rattachées les archives, avec leur dispersion.
Par exemple, en physique, le nombre d’établissement par archive va de 1 à 48. La moitié des archives sont rattachés à 1-8 établissements, l’autre moitié des archives de physique sont rattachées à 8-48 établissements.
En SHS, les 3/4 des publications sont rattachés à une seule structure de recherche
On voit donc que les Sciences du Vivant (SDV), les SHS, la science non linéaire (NLIN) sont plus tassées, donc sont rattachées à un moins grand nombre de structures de recherche, que l’économie, les sciences de l’environnement (SDE) ou les sciences de l’Univers (SDU) - La largeur des colonnes rend compte du nombre d’archives recensées : il y en a beaucoup plus en informatique, en physique et en SHS qu’en économie et en statistiques
Les archives en SHS contiennent moins de liens entre structures de recherche que celles en informatique, ce qui permet d’expliquer en grande partie leur « disparition » dans le graphe globale des collaborations
Limite essentielle de l’exercice
Si la démarche est intéressante (et justifie la publication de ce billet), les observations ci-dessus sont trop tributaires de la source des informations, qui est très partielle. J’ai déjà signalé que le corpus n’était ni exhaustif ni représentatif.
Il y a un autre biais, tout aussi gênant : le champ « setSpec » où sont stockées les informations exploitées ci-dessus est uniquement la mention des tampons associés à chaque ressource. Donc si un laboratoire de recherche n’a pas choisi de demander l’activation d’un tampon pour ses publications, il n’est pas mentionné dans ces setSpec.
Peut-on exploiter une autre source d’informations pour rattacher chaque archive déposée à des structures de recherche ? 2 autres sources seraient envisageables :
- Le champ « contributeurs » mentionne souvent le nom des laboratoires
- à partir du nom du chercheur, retrouver le nom de son laboratoire grâce à l’API Affiliation des auteurs
La première piste est bloquée du fait que, contrairement au champ setSpec, l’information n’y est pas normalisée : sur 22295 « contributeurs » dans le corpus, il y a 8244 formes différentes, ce qui ne veut pas dire 8244 structures de recherche : l’INRIA de Sophia-Antipolis apparaît sous 75 formes différentes.
La seconde piste serait plus prometteuse, s’il n’y avait le problème des homonymes, et des affiliations multiples (qui sont parfois en fait la même structure bénéficiant de plusieurs « fiches » dans HAL) ou successives.
Conclusions
L’analyse des collaborations entre structures de recherche, au travers du cas du corpus de HAL-Unice, donne à voir (à visualiser) le réseau de la recherche française, à travers le prisme de leur activité dans HAL (nombre de dépôts et tampon).
On pourrait pousser cependant plus loin l’analyse, pour calculer, par exemple en fonction des disciplines, le nombre de structures de recherche (moyen, médian) auquel un laboratoire (ou l’un de ses chercheurs) de l’Université s’associe.
Une évolution sur la durée pourrait aussi se révéler intéressante, mais sur un autre corpus : celui de HAL-Unice, pour cela, est sans doute trop concentré sur le XXIe siècle.
En revanche une projection cartographique, avec des données de géolocalisation, donnerait à voir l’extension de ces collaborations, et le poids des partenariats locaux. Il faudrait pour cela lier chaque structure à ces informations.
Pour avoir une vision plus satisfaisante, il faudrait entreprendre un gros travail de reprise des données disponibles, en systématisant par exemple la constitution de « collections » (tampons) par structure de recherche.
Le travail d’analyse est aussi très tributaire des données : et telles qu’elles sont il n’est pas toujours simple de distinguer automatiquement les structures UNS des autres, de les rattacher à une ou plusieurs disciplines. On pourra donc envisager des opérations de nettoyage et d’amélioration de la base initiale, pour pouvoir ensuite l’exploiter un peu mieux.
Ces 2 billets étaient surtout l’occasion de donner à voir ce que contenait HAL-Unice, comme reflet d’une partie de la production scientifique de l’Université.
Les thèses, produites elles durant 5 décennies, en sont un autre volet au moins aussi intéressant. Il en sera donc bientôt question.
