Centre du Réseau Sudoc-PS PACA/Nice
Mission : enrichir et faire parler les données du CR (1/5)
Ce billet, introductif d’une série d’autres billets sur le sujet, vise à développer un des projets présenté dans la Convention sur objectifs 2018-2020 du Centre Régional Sudoc-PS Paca/Nice (CR).
Ce projet comprend la création de deux interfaces web :
* une interface publique destinée à présenter, visualiser, interroger (voire éditorialiser) les données des bibliothèques du CR.
* une interface à usage interne centrée sur la qualité des données dans une optique d’outil de pilotage et d’amélioration.
Au stade où nous en sommes, celui de la formalisation des besoins et de la spécification des fonctionnalités attendues, les contours du projet génèrent encore beaucoup de questions et de tâtonnements. C’est justement l’objectif de cette série de billets que de partager nos réflexions, tests, méthodes de travail, choix d’outils, calendriers, ratés… Toutes les étapes qui rythment le cycle de vie d’un projet.
Concernant le travail sur la qualité des données, l’idée est de se doter d’un tableau de bord de type web qui aura les caractéristiques suivantes :
* reproductibilité : mise à disposition du CR d’une page web dotée d’un formulaire d’injection d’une liste de ppn qui génère un tableau de résultats à la volée.
* interrogation en temps réel des notices du catalogue national Sudoc.
* informations synthétisées sur les critères de qualité retenus en amont par l’équipe (par exemple présence ou non d’un ISSN) et production de listes de titres servant de base de travail pour les corrections.
En résumé, un service de type AlgoSudoc personnalisé et adapté aux notices de périodiques. Techniquement parlant et à ce stade, les choix liés aux types de langages, environnements ou frameworks, ne sont pas arrêtés. Cependant cette partie du projet n’est pas la plus ambitieuse et ne nécessite pas forcément beaucoup de moyens. Voici par exemple une page html (en mode prototype bien sûr) que l’on peut produire avec une simple feuille de style xsl appliquée à une liste de 1000 ppn formatée en xml :
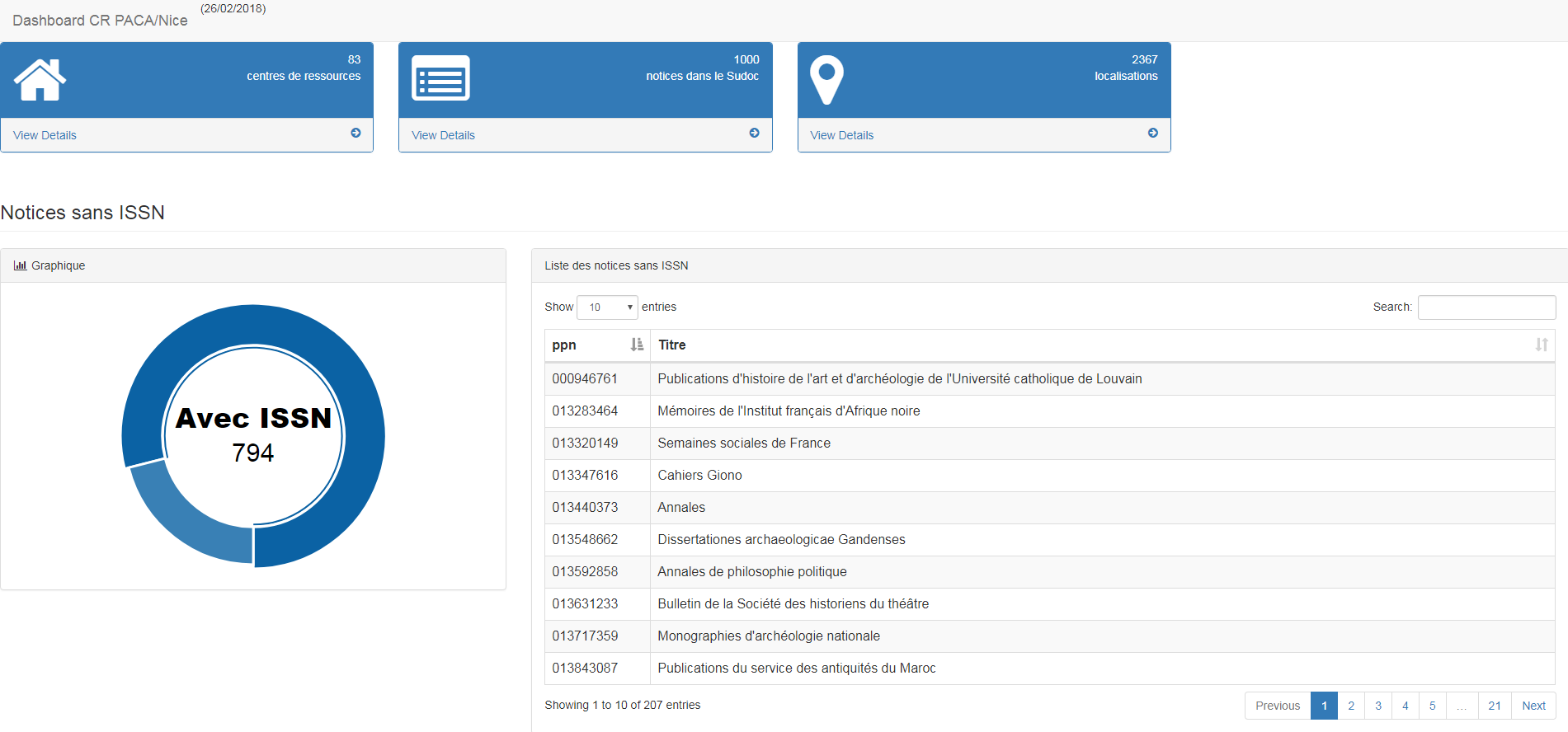
(librairie javascript utilisée pour les graphiques : morris.js)
En revanche le deuxième volet du projet s’annonce plus complexe, puisqu’il s’agit de proposer :
- une interface de visualisation (= de la dataviz),
- dotée d’un moteur de recherche (= de l’indexation),
- plutôt attractive (= du framework web),
- qui rende visible sur le web les données qu’elle intègre (= des données embarquées dans les pages web, s’appuyant sur du RDFa notamment), à l’instar, n’ayons peur de rien, de ce que propose data.bnf
- tout en proposant un type de navigation exploratoire (= de la modélisation en graphe, ou du moins une structuration de données autorisant un parcours de type graphe)
- donc par conséquent, s’appuyant sur des données modélisées selon le modèle LRM et les standards du web de données.
- sans oublier bien sûr de se raccrocher aux deux autres objectifs du CR : la valorisation des unicas et de la presse locale
Si on essaie d’articuler l’ensemble de ces éléments, certaines interrogations se posent d’emblée :
- quel périmètre de données ? Notre réflexe naturel est bien sûr de se concentrer sur les données bibliographiques, mais il y a un fort intérêt à également pousser au même niveau les données locales sur les exemplaires ainsi que les données sur les bibliothèques (= les notices RCR), notamment si l’on considère que le réseau du CR, par nature très hétérogène, comprend aussi des structures de tailles et moyens modestes qui ne sont pas dotées de site web et pour lesquelles une telle interface assurerait une présence et une indexation sur le web.
- quelles sources utiliser pour ces données (Sudoc, ISSN, databnf…), notamment en fonction des récentes évolutions du portail ISSN et des modalités d’exposition des données proposées par ISSN ?
- quel workflow peut-on mettre en place : extraction dynamique ou base de données avec mise à jour ? Et dans le cas de mises à jour, avec quelle fréquence ?
- quelle modélisation opérer, sachant qu’autant FRBR que LRM sont beaucoup moins opérants sur les publications en série que sur les monographies ?
- quelle interface côté utilisateur ? Du « fait maison », du framework web léger, du logiciel open source ?
- quelle articulation avec l’animation de réseau du CR : dans l’idéal le mode collaboratif est bien sûr plutôt envisagé, mais comment le mettre en œuvre ?
En résumé : un vaste et beau chantier devant nous !
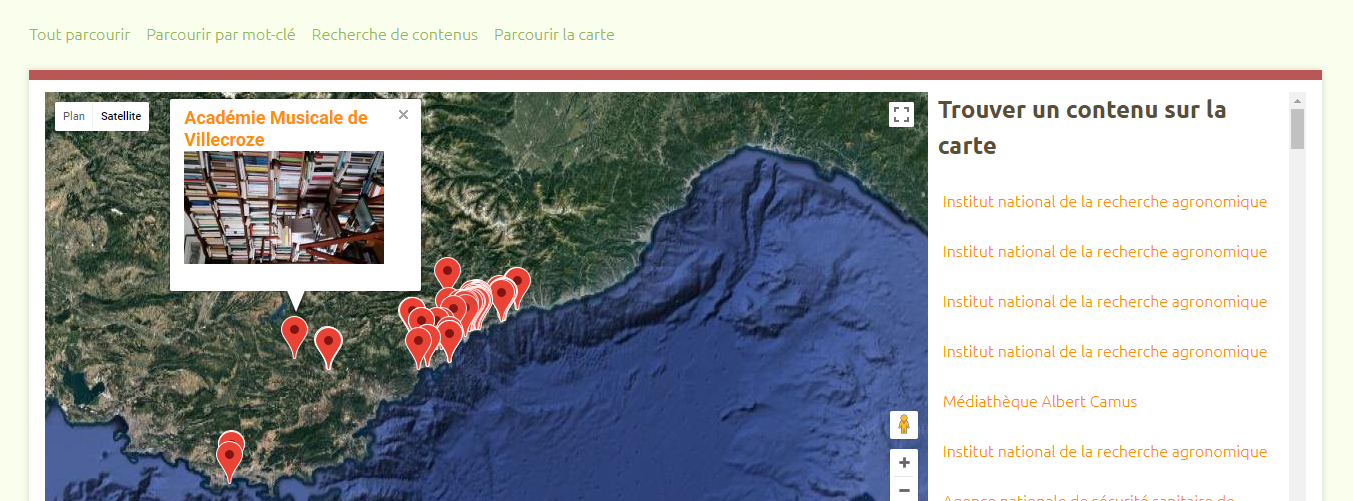
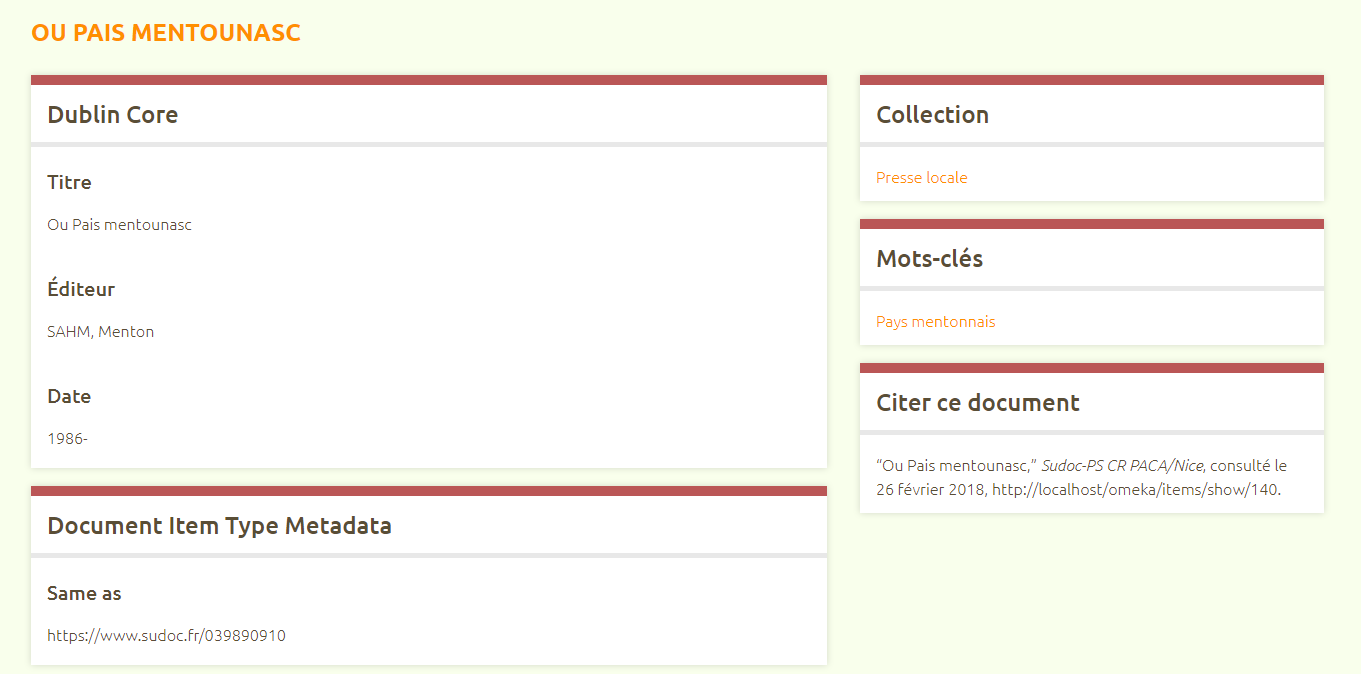
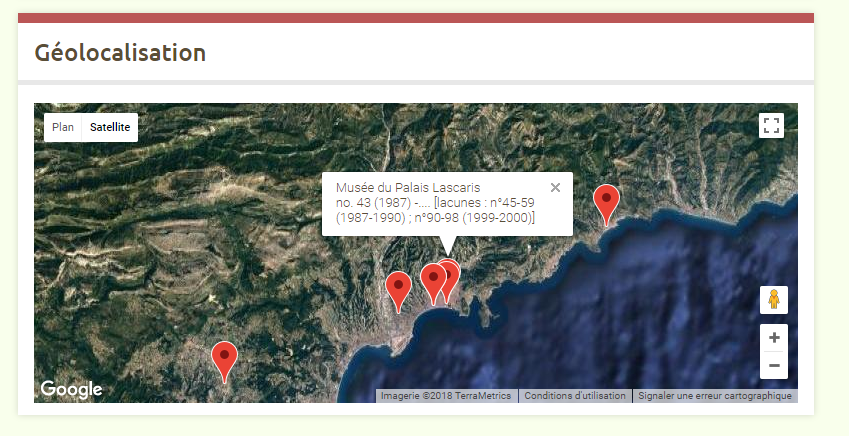
Quoi qu’il en soit, pour illustrer notre propos lors de la présentation du projet à la dernière Journée du Centre Régional (Grasse, nov 2017), nous avons opté pour une visualisation expérimentale avec le logiciel Omeka (dans un usage quelque peu détourné de sa fonction principale d’outil de bibliothèque numérique), qui fournit d’ores et déjà une piste intéressante… A suivre !