Centre du Réseau Sudoc-PS PACA/Nice
Enrichir et faire parler les données du CR (4/5) : passage par la case modélisation
Début mars 2019 s’est tenu à Berlin un Workshop du W3C autour de la structuration des données en graphe et de leur intégration dans le web. Présentée ainsi, la problématique paraît triviale puisque le W3C est justement l’organisme qui gère et promeut ce qu’on appelle le web de données, c’est-à dire l’adoption des standards de la modélisation en RDF (qui est par nature un graphe) pour « pousser », lier et ouvrir les données sur le web. En fait, ce Workshop est le résultat d’un constat : d’une part il y a les modélisations de type web de données donc, avec leurs univers de données identifiées par des URIs sémantiquement décrites et connectées entre elles grâce à des ontologies (et il est vrai que le Linked Open Data Cloud ne cesse de s’étendre), mais à côté on constate également l’utilisation croissante par des acteurs divers et variés (économiques, institutionnels…) de bases de données non-relationnelles dites orientées graphe dans des logiques de curation et visualisation de données décorrélées des problématiques du web.
De quoi s’agit-il ? Il s’agit de structurer ses données comme un ensemble de noeuds (dotés d’attributs sous forme de paires clé-valeur pour les décrire) liés entre eux par des relations (elles-mêmes qualifiées par d’autres attributs) , tout en étant complètement libre dans la détermination des entités, du type de leurs liens et de la nature de leurs propriétés*. Ces modélisations dites de type property graph, jugées à l’usage très performantes pour traiter des masses exponentiellement croissantes de données plus ou moins structurées (le fameux Big Data, qui s’ouvre désormais aux objets connectés !), répondent donc à un besoin auquel la modélisation type RDF répond mal :
- de la flexibilité et de la souplesse dans la création et l’annotation des entités et de leurs connexions,
- un stockage des données de ce fait optimisé par des graphes beaucoup moins verbeux,
- des langages d’interrogation spécifiques à chaque base de données mais relativement simples (toujours plus simples que du SPARQL de toute façon !) et très puissants pour parcourir des chemins dans le graphe.
On comprend donc mieux la teneur du Workshop qui visait en fait à établir des ponts entre deux technologies, l’une dédiée à l’ouverture et l’échange de données, l’autre au stockage et à la navigation dans les données, mais utilisant toutes deux des modélisations en graphe (en sous-texte, « ça sent le roussi » pour le RDF qui pour x raisons reste une technologie de niche, tandis que parallèlement se développe le property graph pour des raisons de pragmatisme et d’efficience).
Pour donner une idée de la diversité des cas d’usages où l’approche property graph se révèle pertinente, on peut mentionner le Consortium International des Journalistes d’Investigation qui a travaillé sur les Panama papers en recourant à une base de données orientée graphe, et ce dans une démarche heuristique pour mettre à jour les connexions dans les 11,5 millions de documents non-structurés qui avaient fuités. Pour ceux que cela interesse, une brève news ici et un billet plus complet ici
Et donc ??? Pourquoi cette loooongue introduction et quel est le rapport avec l’application sur les données de périodiques du CR dont on vous parle depuis 3 billets maintenant (sachant qu’à l’échelle du CR on ne se trouve pas vraiment des problématiques de Big Data) ?
Le lien se trouve dans la modélisation : nous en étions à la fin du billet précédent sur une mini app en tant que preuve de concept sur les données des unicas, il s’agit maintenant de passer à l’échelle sur l’ensemble des données d’unicas et de presse locale au niveau du CR, et de construire les traitements de données au coeur de l’application, afin de créer et automatiser les workflows qui permettront de passer de listing de données issus du Sudoc et du catalogue général de la BnF à une interface web où chaque bibliothèque du réseau pourra visualiser et interroger ses collections, et disposer des métadonnées. La difficulté de l’exercice tient alors à la variabilité des périmètres (CR/RCR) et la multiplicité des sources d’enrichissement des données. En effet, si les trois sources primaires sont bien identifiées et (manuellement mais) facilement récupérables :
- une liste de ppn de tous les unicas de toutes les bibliothèques du CR -> récupérés à partir de Self Sudoc,
- une liste des identifiants ark de tous les titres de presse locale ancienne sur les deux départements Alpes-Maritimes et Var + Monaco référencés sur le site http://presselocaleancienne.bnf.fr/accueil -> récupérés à partir de la fonction d’export en csv par lots du catalogue général de la BnF (voici par exemple un lien profond permettant d’isoler ces titres pour les Alpes-Maritimes : https://catalogue.bnf.fr/search.do?mots1=ALL;2;0;devenu&mots0=GES;-1;0;bipfpig06&&pageRech=rav),
- une liste les bibliothèques de l’ILN 230 du CR -> issue du web service iln2rcr.
Il faut ensuite requêter plusieurs services d’exposition des données mis à disposition par l’Abes et la BnF pour construire le corpus de métadonnées (ce billet précédent détaille par exemple une méthode d’interrogation de web services et de traitement des résultats dans Excel pour les unicas *)
*A noter qu’entre temps un nouveau web service a été mis en place par l’Abes qui permet d’obtenir les notices complètes en Unimarc/Xml à partir de l’extension .xml ajoutée aux urls pérennes du Sudoc (par exemple https://www.sudoc.fr/156143453.xml), plutôt que les notices incomplètes exposées en RDF. A noter également que désormais les champs ISSN sont exposés dans les notices. Gros avantage enfin, outre la complétude des données bibliographiques, les données d’exemplaires sont également délivrées en fin de notice, ce qui à première vue économise des appels au web service multiwhere pour retrouver les bibliothèques localisées sous les notices. Mais à première vue seulement, car les données d’exemplaires ne contiennent « que » le rcr des bibliothèques : si l’on souhaite des données plus riches (nom et géolocalisation de l’établissement), il faut de toute façon revenir à l’API multiwhere, puisqu’il n’existe pas (à ma connaissance tout du moins) de web service permettant d’obtenir des notices RCR en Unimarc/xml à partir du numéro RCR (les accès aux web services d’Idref qui exposent les données d’autorités en Unimarc/xml se font sur la base du ppn).
Ce qui donne schématiquement si on se concentre sur le côté traitement de données :
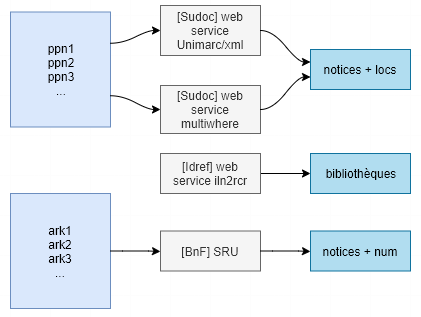
mais qui n’est qu’une partie du schéma global du projet :
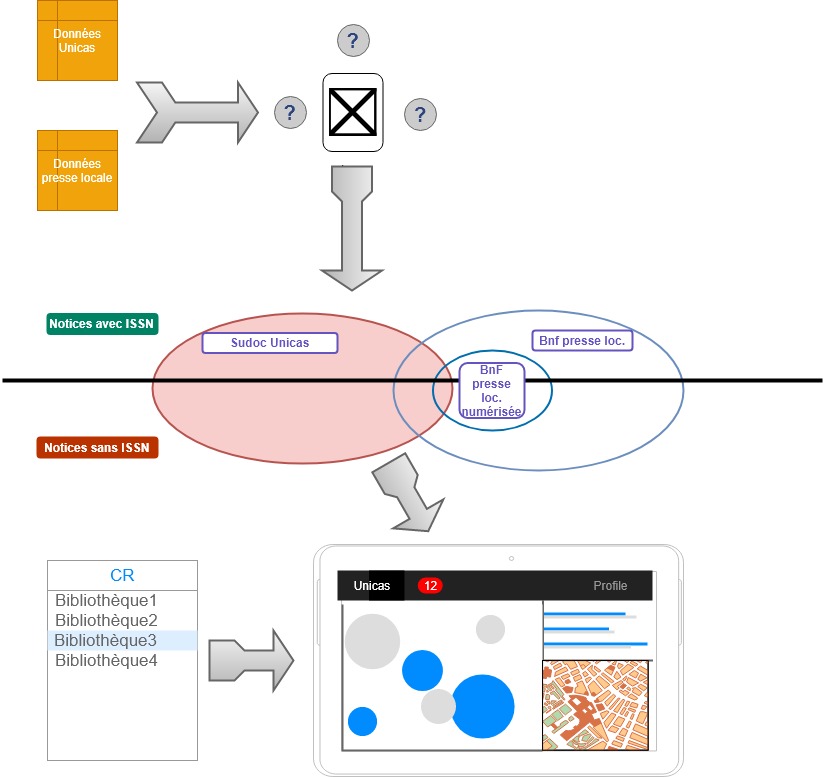
Il s’agit donc de trouver la modélisation, le stockage et le chaînage des traitements de données adéquats qui permettent de déterminer précisément le périmètre des unions et intersections entre « blocs de données » représentés par les cercles au centre du schéma, autrement dit de trouver un moyen de pouvoir répondre aux questions à la fois au niveau global du CR et particulier de chaque RCR : combien unicas ? Parmi ceux-ci quelles notices n’ont pas d’ISSN et peuvent faire l’objet d’une demande via Cidemis ? Quelle est la répartition territoriale et par bibliothèque des titres de presse ? Parmi les titres de presse concernant les AM, lesquels sont également des unicas ? Quels sont les unicas détenus par les bibliothèques monégasques pour lesquels une version numérisée est accessible ? Bref, comment NAVIGUER dans les données ?
C’est ici que l’on retrouve nos graphes : quand il s’agit de parcours dans les données, autrement dit ici de requêtes croisées entre sources distinctes, il est avantageux de sortir de la logique relationnelle de jointures entre fichiers plats et de passer à une modélisation type graphe. Ainsi, en décidant d’adopter une base de données orientée graphe (Neo4j en l’occurence) basée sur une modélisation property graph, le coeur du travail consiste à bien déterminer (et ce en fonction des questions auxquelles on veut pouvoir répondre) :
- les types d’entités à modéliser (les noeuds du graphe et leurs attributs),
- les liens entre les entités et les propriétés (caractéristiques) de ces liens,
- parmi ces connexions, celles que l’on connait de par la structure des sources de données, et celles que l’on crée dans la base de données par algorithme d’alignement entre noeuds.
Si on « recolle » à nos données Sudoc et BnF, voici ce que cela donne en substance :
– on créé des noeuds de type Bibliothèques qualifiés par des attributs de nom, RCR, latitude et longitude et des noeuds de type unicas caractérisés par quelques éléments extraits de la notice Sudoc (titre, ppn, issn, zone 309) ; ces noeuds peuvent être connectés par une relation illustrant la localisation du périodique, ce lien étant créé à partir à partir du web service multiwhere.
– On créé également des noeuds représentant les titres de presse locale définis par les métadonnées de titre, identifiant ark et issn; on définit une relation d’équivalence « same_as » avec les noeuds unicas quand l’attribut issn est le même.
– On ajoute des noeuds qui représentent les versions numérisées des titres de presse locale quand le champ correspondant est présent dans la notice Unimarc/xml renvoyée par le SRU de la BnF, et on les relie aux noeuds de type presse locale ancienne représentants les versions imprimées
– etc…
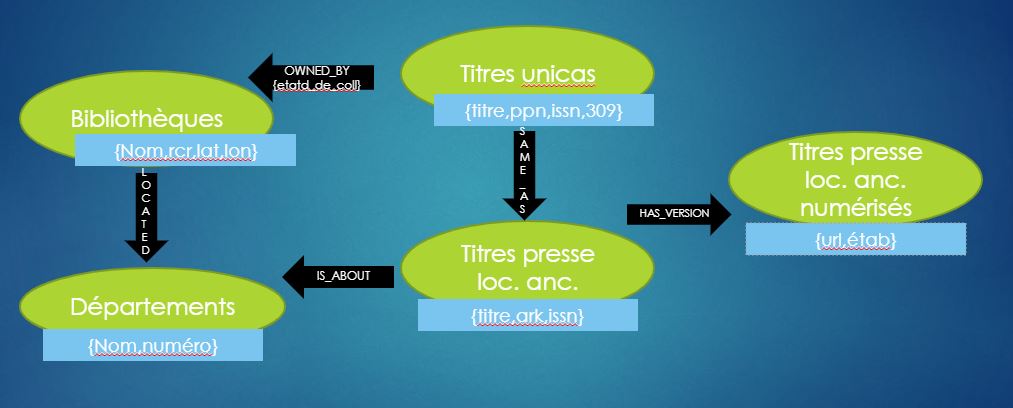
[Cliquer sur l’image pour voir l’animation]
Voilà pour le modèle de données… Évidemment l’alimentation du graphe dans la base de données ne s’effectue pas manuellement, l’ensemble du workflow est automatisé (notamment pour faciliter les mises à jour et favoriser la reproductibilité du processus). La démarche est la suivante :
- on effectue un chargement initial à minima dans la base de données en important uniquement les listes de ppn d’unicas et d’ark de presse locale,
- on automatise les enrichissements (ajouts des attributs et des liens) par des requêtes aux API précédemment explicitées directement dans la base de données (grâce à une librairie de fonctions et procédures nommée Apoc intégrée comme un plugin à Neo4j). La succession des requêtes utilisées en langage Cypher est disponible sur ce Gist https://gist.github.com/gegedenice/c7e53cc4c3d65b8bc1639d4b55a90be6,
- on développe l’application au-dessus de la base de données pour proposer une interface web de visualisation et redistribuer les données du graphe par des API et des exports en Excel.
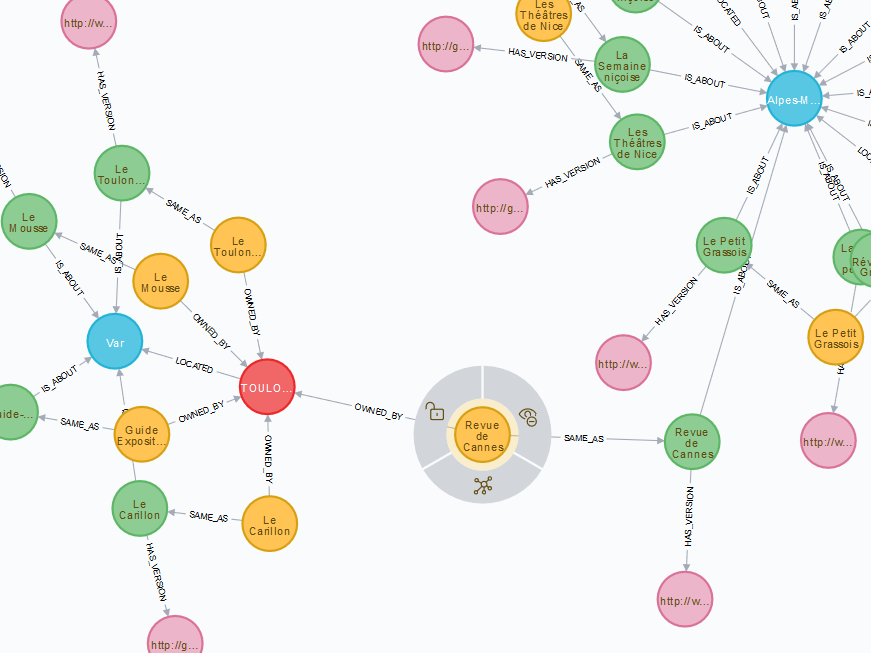
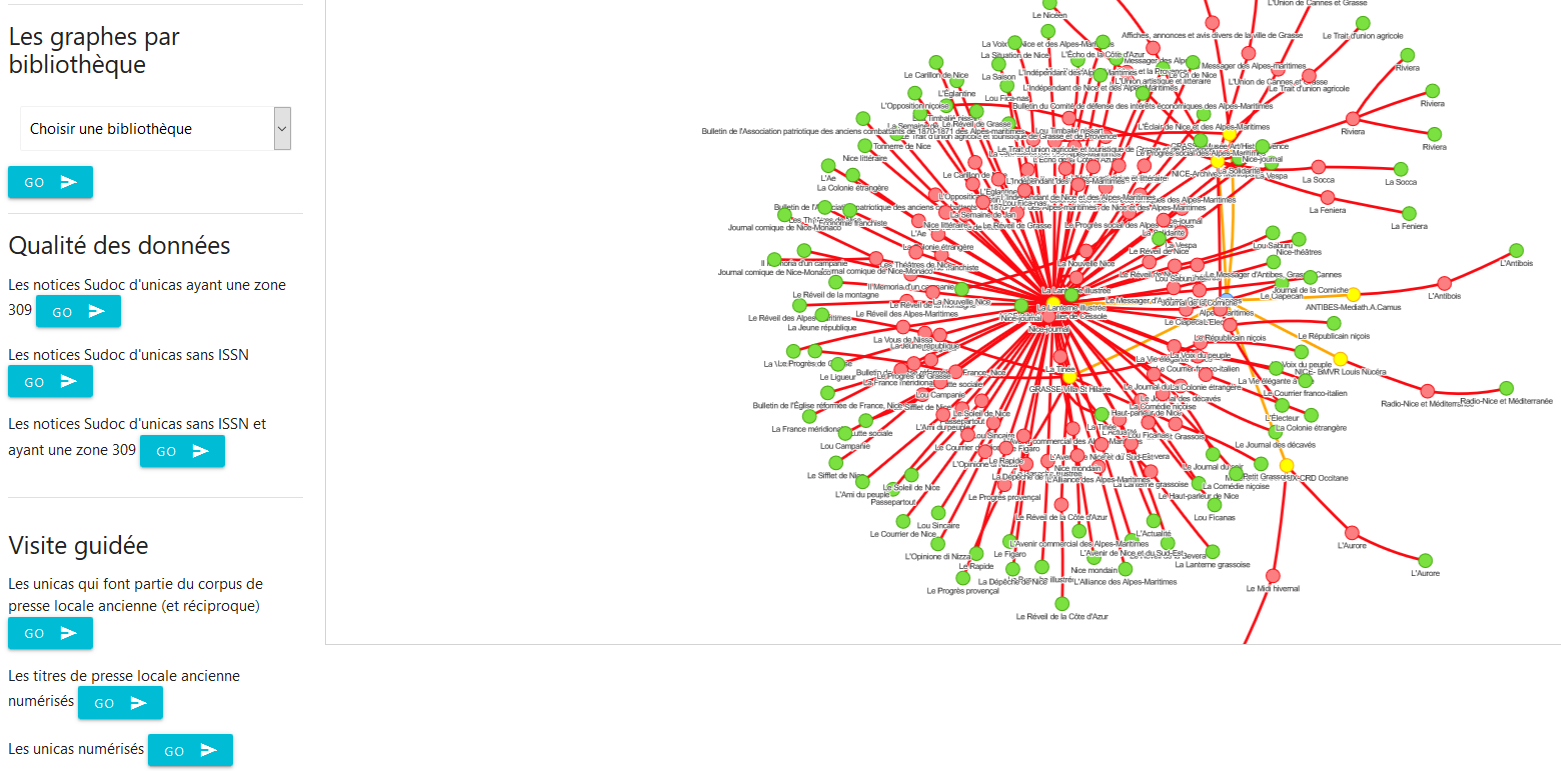
Voici un extrait du graphe final dans l’interface graphique de la base de données qui illustre exactement à quel point la dimension exploratoire est facilitée dans ce genre de visualisation et comment elle aide à mettre à jour des connexions qu’il serait extrêmement laborieux de mettre en évidence par des techniques plus classiques de jointures.
Au centre de l’image, le noeud jaune représente un unica (la Revue de Cannes), périodique également référencé comme un titre de presse locale ancienne (le noeud vert) concernant le département des Alpes-Maritimes (le noeud bleu) ayant fait l’objet d’une numérisation aux Archives municipales de Cannes (le noeud rose), mais dont la collection papier est détenue à la BM de Toulon (le noeud rouge).
Et la version web complète proposée dans l’application :
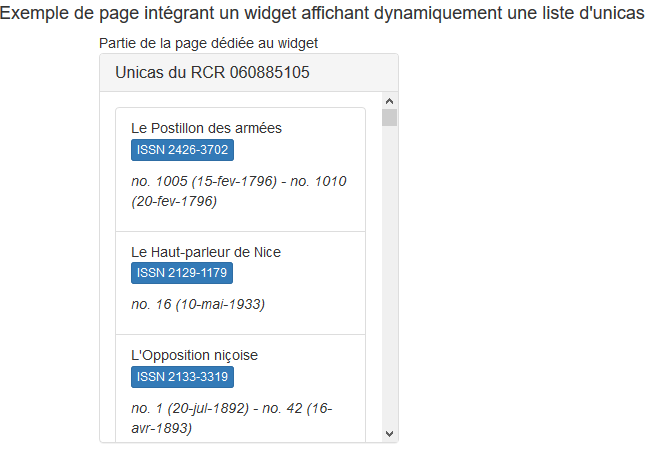
Comme prévu initialement, au-delà de la pure visualisation de parcours de graphe, l’application proposera des fonctionnalités de redistribution des données à destination des bibliothèques s’appuyant sur les traitements et appariements réalisés dans la base de données
| Sous forme d’API
(avec des urls paramétrables pour spécifier le rcr voulu) |
Par export Excel | Intégration de widget
sur une page web |
 |

|
 |

Quelques infos pratiques pour conclure (enfin !) en légèreté après cette avalanche de points techniques :
- l’application ouvrira en production à la rentrée universitaire 2019, elle sera présentée dans le détail lors de la prochaine journée annuelle du réseau le 5 novembre à la Bibliothèque du Chevalier de Cessole
- A la demande de l’Abes, nous l’avons déjà présentée le 27 mai 2019 à l’occasion de la journée Sudoc-PS qui se tient traditionnellement chaque année en marge des Journées Abes (programme). Le PowerPoint de notre présentation est accessible en ligne ici.
- Comme mentionné dans le billet, le code des requêtes utilisées pour alimenter le graphe est déjà disponible ici, le reste du code de l’application sera évidemment déposé en open source à l’ouverture.
* les seules conditions à remplir sont que le graphe doit être orienté et les nœuds labellisés